

中文分词的算法与模型的发展
早期统计方法
早期的中文分词技术主要依赖于统计方法。这些方法通常基于频率和概率,通过分析大规模语料库中的词频和词共现关系来进行分词。典型的统计方法包括基于N元语法模型、最大匹配法(如正向最大匹配和逆向最大匹配)等。这些方法简单且易于实现,但在处理新词和歧义词时效果较差。这些方法在早期的中文分词工具和中文分词器中广泛应用。
立即加入飞书 AI ready 计划,AI 时代快人一步 →
条件随机场(CRF)方法
随着机器学习的发展,条件随机场(CRF)成为中文分词的主流方法之一。CRF是一种无向图模型,能够有效地处理序列标注问题。通过定义特征函数,CRF可以捕捉上下文信息,提高分词的准确率。CRF方法的代表性工作包括《使用条件随机场进行中文分词和新词检测》。尽管CRF在分词性能上有显著提升,但其训练过程较为复杂,计算成本较高。
深度学习方法的兴起
近年来,深度学习技术在自然语言处理领域取得了突破性进展,中文分词也不例外。基于深度学习的方法,如卷积神经网络(CNN)、长短期记忆网络(LSTM)和Transformer,逐渐成为主流。这些方法能够自动学习特征,减少了对人工特征工程的依赖,提高了分词的准确性和鲁棒性。例如,BiLSTM-CRF模型结合了双向LSTM和CRF的优势,实现了中文分词的高精度。特别是在java中文分词和es中文分词领域,这些深度学习方法也得到了广泛应用。
关键系统与框架
BERT及其变体在中文分词中的应用
BERT(Bidirectional Encoder Representations from Transformers)是由Google提出的一种预训练语言模型,通过双向Transformer架构捕捉上下文信息。BERT在中文分词中表现出色,许多研究者基于BERT提出了改进的模型,例如ZEN和BERT-LE。ZEN通过引入N-gram表示增强了BERT在中文分词任务中的性能,而BERT-LE则进一步优化了BERT的训练和推理效率。
LSTM-CRF模型的影响
LSTM-CRF模型是中文分词中的经典组合。LSTM能够捕捉序列中的长距离依赖关系,而CRF则能有效地进行序列标注。许多研究者在LSTM-CRF的基础上进行了改进,例如引入字符嵌入、子词嵌入等,以进一步提升分词性能。代表性工作包括Ma et al.(2018)和Chen et al.(2017)。这些模型在中文分词器和中文分词工具中得到了广泛应用。
Transformer模型的创新应用
Transformer模型由于其并行计算能力和强大的特征提取能力,在自然语言处理任务中广泛应用。近年来,研究者们尝试将Transformer应用于中文分词任务,并取得了显著成果。例如,LATTE模型通过结合格结构和图神经网络,利用多粒度表示来补充字符表示,从而提高了分词的准确性。特别是在java中文分词和es中文分词的应用中,Transformer模型展示了其强大的潜力。
评估指标与数据集
常用的评估指标
中文分词的主要评估指标是F1-score,它综合了精确率(Precision)和召回率(Recall)。F1-score的计算公式为:
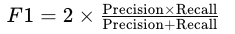
此外,准确率(Accuracy)和错误率(Error Rate)也是常用的评估指标。
主流数据集简介
常用的中文分词数据集包括Chinese Treebank 6(CTB6)、Chinese Treebank 7(CTB7)、AS、CityU、PKU和MSR等。这些数据集涵盖了不同领域和风格的文本,为模型的训练和评估提供了丰富的资源。
系统性能对比
不同系统在各数据集上的表现有所差异。以下是一些代表性系统在CTB6、CTB7、AS、CityU、PKU和MSR数据集上的F1-score:
- CTB6: Huang et al. (2019) - 97.6, Tian et al. (2020) - 97.3
- CTB7: Ma et al. (2018) - 96.6, Kurita et al. (2017) - 96.2
- AS: Tian et al. (2020) - 96.6, Huang et al. (2019) - 96.6
- CityU: Tian et al. (2020) - 97.9, Huang et al. (2019) - 97.6
- PKU: Huang et al. (2019) - 96.6, Tian et al. (2020) - 96.5
- MSR: Tian et al. (2020) - 98.4, Ma et al. (2018) - 98.1
中文分词在自然语言处理中的角色
文本分析
中文分词是文本分析的基础步骤,通过将连续的字符序列切分成词语,能够帮助后续的文本分类、情感分析等任务更好地理解文本内容。例如,在情感分析中,准确的分词能够提高情感词的识别率,从而提升分析的准确性。使用中文分词工具可以大大提高文本分析的效率。
语义理解
分词是语义理解的前提条件。通过分词,模型能够更好地捕捉句子的语义信息,理解文本的含义。在问答系统和对话系统中,分词的准确性直接影响到系统的回答质量。高效的中文分词器在这些应用中至关重要。
机器翻译
在机器翻译任务中,分词能够帮助模型更好地对齐源语言和目标语言的词语,从而提高翻译的质量。例如,在中英翻译中,准确的分词能够帮助模型更好地理解中文句子的结构,生成更符合语法和语义的英文句子。特别是在java中文分词和es中文分词的应用中,分词的质量对翻译结果有直接影响。
中文分词的企业级应用案例
搜索引擎优化
在搜索引擎优化中,分词技术能够帮助搜索引擎更好地理解用户的查询意图,提高搜索结果的相关性。例如,当用户搜索“北京旅游景点”时,准确的分词能够帮助搜索引擎识别出“北京”、“旅游”、“景点”三个关键词,从而返回更精确的搜索结果。使用中文分词工具可以显著提升效果。
智能客服系统
智能客服系统通过分词技术,能够更好地理解用户的问题,提供准确的回答。例如,当用户询问“如何办理信用卡”时,系统通过分词识别出“办理”、“信用卡”两个关键词,从而准确地匹配到相关的回答。高效的中文分词器在智能客服系统中发挥着重要作用。
舆情分析工具
舆情分析工具通过分词技术,能够实时监控和分析社交媒体上的信息,帮助企业了解公众对产品或服务的反馈。例如,通过分词识别出“产品质量”、“服务态度”等关键词,企业可以及时发现问题,做出相应的改进。使用java中文分词和es中文分词技术可以大大提高舆情分析的效率和准确性。
中文分词面临的挑战与未来趋势
新词识别问题
新词识别是中文分词面临的一个重要挑战。由于语言的不断发展,新词不断出现,传统的分词方法难以应对这些新词。如何在分词过程中准确识别新词,是一个亟待解决的问题。有效的中文分词器需要具备强大的新词识别能力。
多义词和歧义词处理
多义词和歧义词是中文分词的另一个难点。由于中文词语的多义性和歧义性,同一个词在不同的上下文中可能有不同的含义。如何在分词过程中准确区分这些多义词和歧义词,是提高分词准确性的关键。高效的中文分词工具在处理多义词和歧义词方面具有重要作用。
数据稀缺
中文分词的语料库相对于英文来说较为有限,模型训练时面临数据稀缺的问题。模型需要通过合理的数据增强和迁移学习等方法来提高分词的效果。
飞书在中文分词中的应用
飞书在中文分词中的应用包括对一段中文文本进行分词。这可以用于文本处理、自然语言处理等场景,帮助更好地理解和处理中文文本内容。
立即加入飞书 AI ready 计划,AI 时代快人一步 →
以下是飞书提供的AI能力中有关中文分词的详细信息:
飞书提供的AI能力在中文分词中的应用包括对一段中文文本进行分词。这可以用于文本处理、自然语言处理等场景,帮助更好地理解和处理中文文本内容。
此外,飞书还提供其他自然语言处理(NLP)相关的AI能力,如关键词提取、实体识别等,这些能力可以组合使用以提高文本分析的效果。








