

模型的作用及类型
飞书智能伙伴创建平台中,模型是智能应用运转机制的“大脑”。选择合适的模型,能够让智能应用最大化释放出能力,让智能应用更好地工作。
目前「模型管理」模块中,我们提供了如下不同类型的模型管理能力,这些模型会分别服务不同的场景:
LLM 模型
LLM(大语言模型)是智能应用运转最核心的部分,主要运用在以下一些核心场景中:
- 智能匹配技能:当用户向智能应用发起对话时,智能应用需要理解用户的输入并判断用户的意图,进而规划使用哪一个技能来执行,以满足用户的输入。在这个场景下,不同的 LLM 模型的速度和准确率会有比较大的差别,如下表所示:
- 知识问答:在知识问答中,LLM 需要根据用户的输入以及基于输入检索的相关知识,进行总结并反馈给用户。在这个场景下,不同的 LLM 模型的速度和效果会有比较大的差别,如下表所示:
- 知识问答技能在选择模型时,若追求效果,建议选择4-turbo-0125版本;若追求速度及性价比,建议选择3.5-turbo的0125版本:
- 知识问答(数据分析):在数据分析中,会有多个部分用到 LLM,包括 SQL 生成、图表生成、洞察生成等。由于场景比较复杂,目前在数据分析场景下建议使用Doubao-pro-32k 模型,这两类模型是目前在数据分析场景下中能够平衡速度和准确性后达到最好效果的选择。
- 模型推理模式:模型推理模式中,允许开发者通过编写提示词,指引大模型进行推理并自主选择工具完成任务。在模型推理模式中,会绑定一个Agent 技能,对话时只会命中该 Agent 技能并执行。模型推理模式依赖Function Calling,因此在使用该模式的时候需要确认调用的模型支持Function Calling。
- 模型推理模式在选择模型时,若追求效果,建议选择4o版本;
- AI 字段提取:主要是分析输入的长文本,解析并识别抽取指定待提取的字段,该能力可以在许多场景中发挥作用,适用于有结构化数据需要从非结构化文本中提取,以下是一些具体的例子:
- 客户服务:AI 可以从客户的邮件、聊天记录或电话录音中提取关键信息,如订单号、问题描述等,然后自动分类或转发到适当的部门,或者提供给客服人员参考。
- 文档处理:在处理发票、合同、报告等文档时,AI 可以提取日期、金额、名称、地址等关键字段,自动填充到数据库或电子表格中。
- 健康医疗:AI 可以从医疗记录中提取病人的姓名、病历号、诊断结果等信息,帮助医生和护士快速理解病人的情况。
Embedding 模型
Embedding 模型主要用于知识问答的场景。核心逻辑是:把用户的输入进行计算后,变成一个模型能够理解的【向量】,并且与已经以【向量】的形式存储在知识库中的知识,进行向量空间的相似度计算,匹配度高的则为需要召回的知识内容,再通过重排序后经过 LLM 模型总结,就形成了知识问答的答案。
目前平台提供两种 Embedding 模型:
- BYOM-Embedding:飞书官方提供的 Embedding 模型
- CloudModel-Text-Embedding-002: 其他云厂商提供的一款Embedding 模型
注意:由于飞书文档、飞书在线表格、服务台等知识库来源本身内置了 Embedding 模型,因此即使配置了第三方的 Embedding 模型,也只会影响本地文件上传以后的向量计算。
多模态模型
在Aily中,目前多模态模型的主要使用场景是:
- 当用户和智能应用对话并上传一张图片时,智能应用能够接收图片,理解这个图片的内容,提取出有用的信息。
为了满足这个场景,目前平台支持接入以下模型:
- CloudModel-4o-0513以及CloudModel-4o-0806:其他云厂商提供的一款多模态模型,主要用于图片理解
- GLM-4V以及GLM-4V-Plus:智谱提供的图片理解多模型模型
- Doubao-vision-pro:AI 图片理解(豆包),图文多模大模型,智能地分析图片,并根据用户的指令生成相应的内容
用户配置了多模态模型后,可以在Workflow技能中的【图片问答】中进行使用。
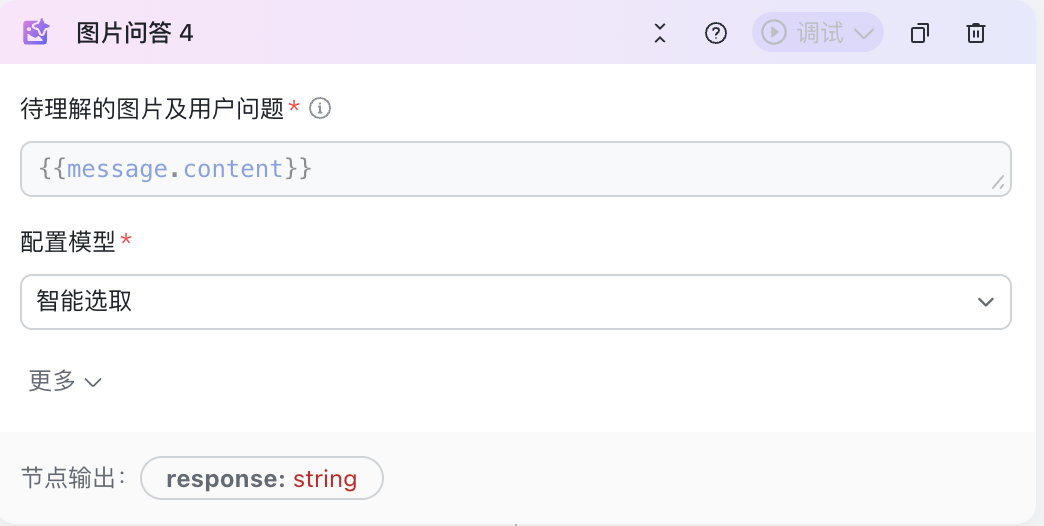
250px|700px|reset
如何管理企业下所有可用的模型?
- 进入企业管理后台
- 点击智能应用创建平台 - 管理后台 , 即可进入企业管理后台
- 企业管理员身份:模型管理仅对企业管理员开放权限并可配置,如果您不是企业管理员身份,请联系企业内部管理员开通对应权限。
250px|700px|reset
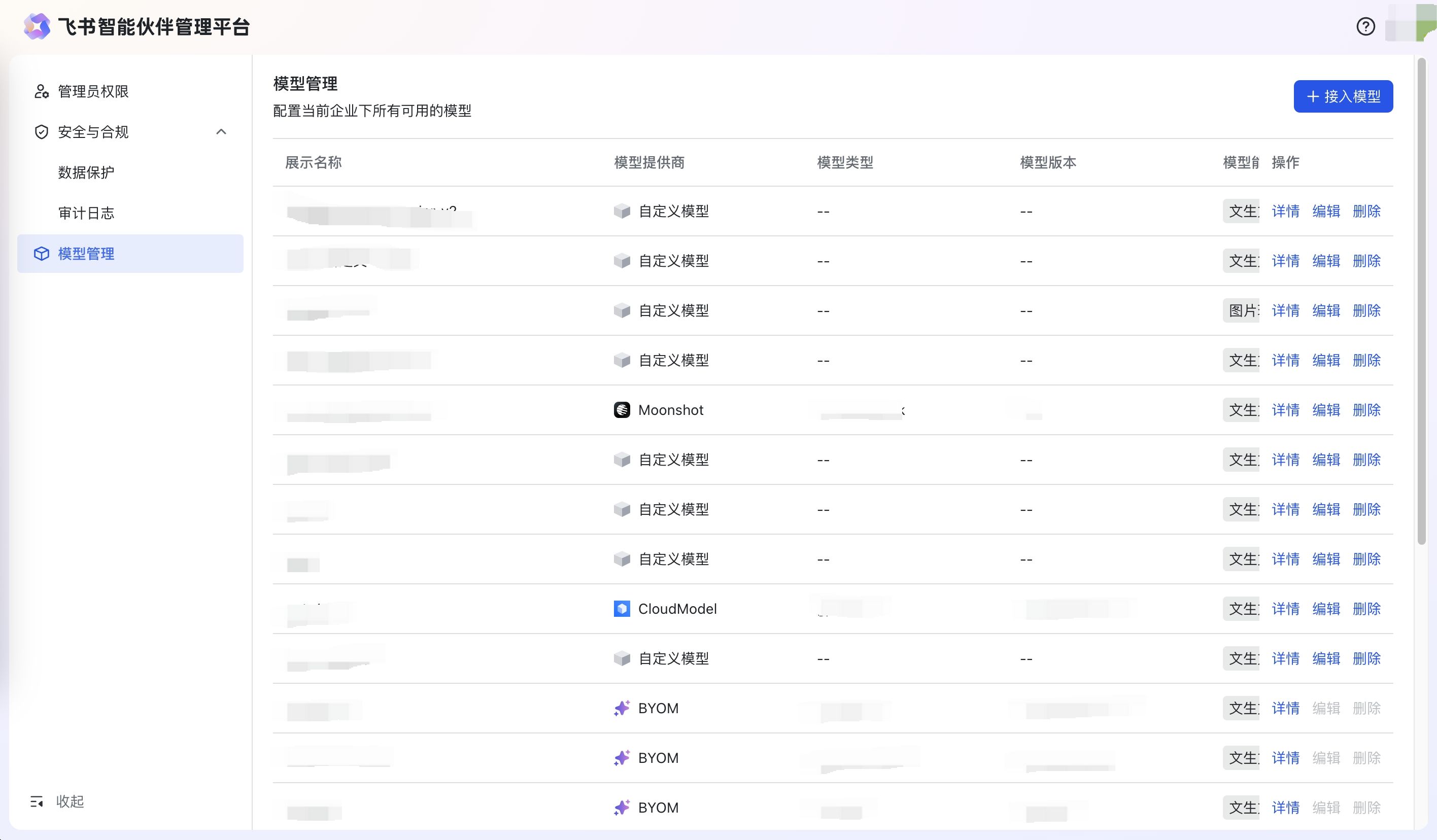
- 模型管理
- 进入管理后台后,选择模型管理,可以看到当前企业所有可用的模型列表,如果当前企业没有购买/配置其他模型,默认展示飞书提供的模型列表
250px|700px|reset
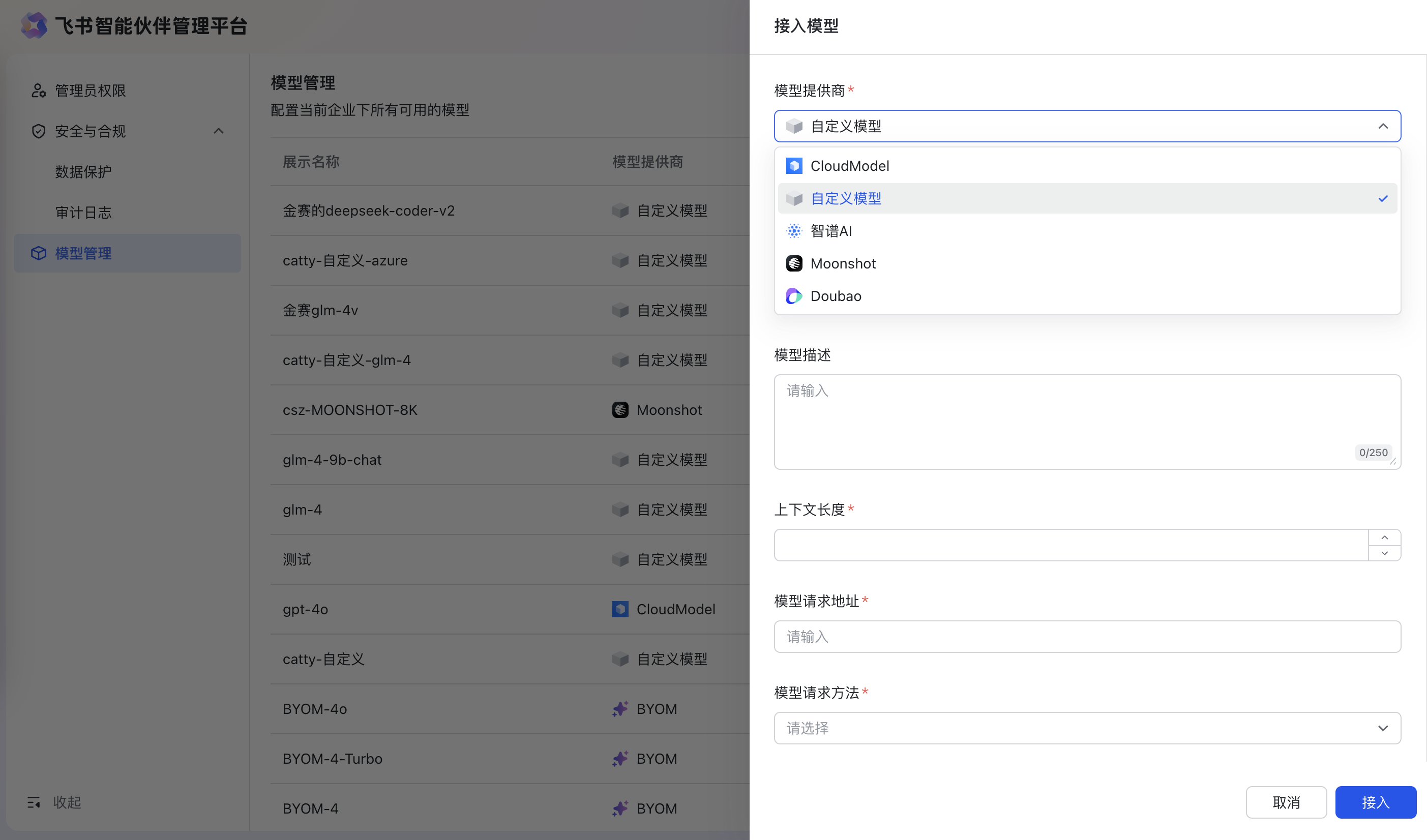
如何添加企业自定义模型?
- 场景一: 企业购买了其他云厂商提供的模型服务,需要在企业租户内接入,可以点击接入模型来接入购买的云厂商模型服务
- 场景二:企业需要接入自己部署的自定义模型,需要在企业租户内接入,可以点击接入模型来接入企业自己提供的自定义模型服务
接入Cloud模型
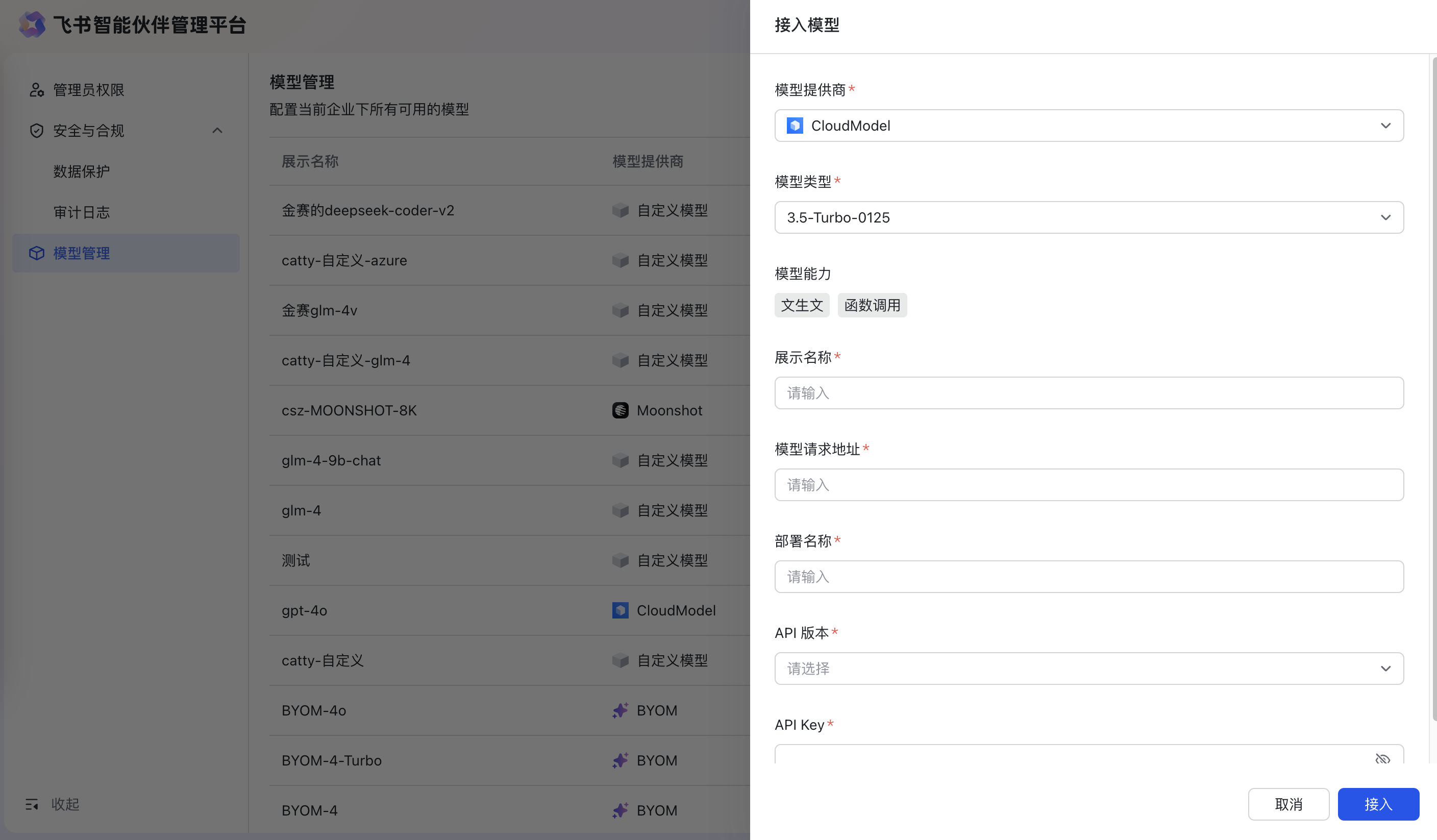
- 接入Cloud 模型配置参数:
- 模型提供商:选择接入Cloud Model
- 模型类型:选择模型类别,如3.5-Turbo-0125
- 模型能力:文生文、文生图、图片理解、函数调用
- 展示名称:填写模型对外部应用和LLM节点展示的名称
- 模型请求地址:模型请求地址
- 部署名称:填写模型部署时显示的名称
- API版本:填写API版本信息
- API key:填写模型调用时所需要的API key信息
- 添加成功:提示模型接入成功
- 添加失败:提示模型校验失败,请检查参数
250px|700px|reset
- 接入自定义模型
- 模型提供商:选择接入自定义模型
- 模型能力:文生文、文生图、图片理解、函数调用
- 展示名称:填写模型对外部应用和LLM节点展示的名称
- 模型描述:描述该模型支持的能力
- 上下文长度:模型支持的窗口大小,指的是发送给模型的指令以及模型输出内容的长度限制。
- 模型请求地址:模型请求地址
- 模型请求方法:POST/GET/PUT/DELETE
- 模型请求头:需要配置键值对,最多可添加10条
250px|700px|reset
模型操作
- 接入成功 - 详情查看 - 编辑 -删除
- 接入成功后,会提示“接入模型成功”,最新接入的模型显示在第一条
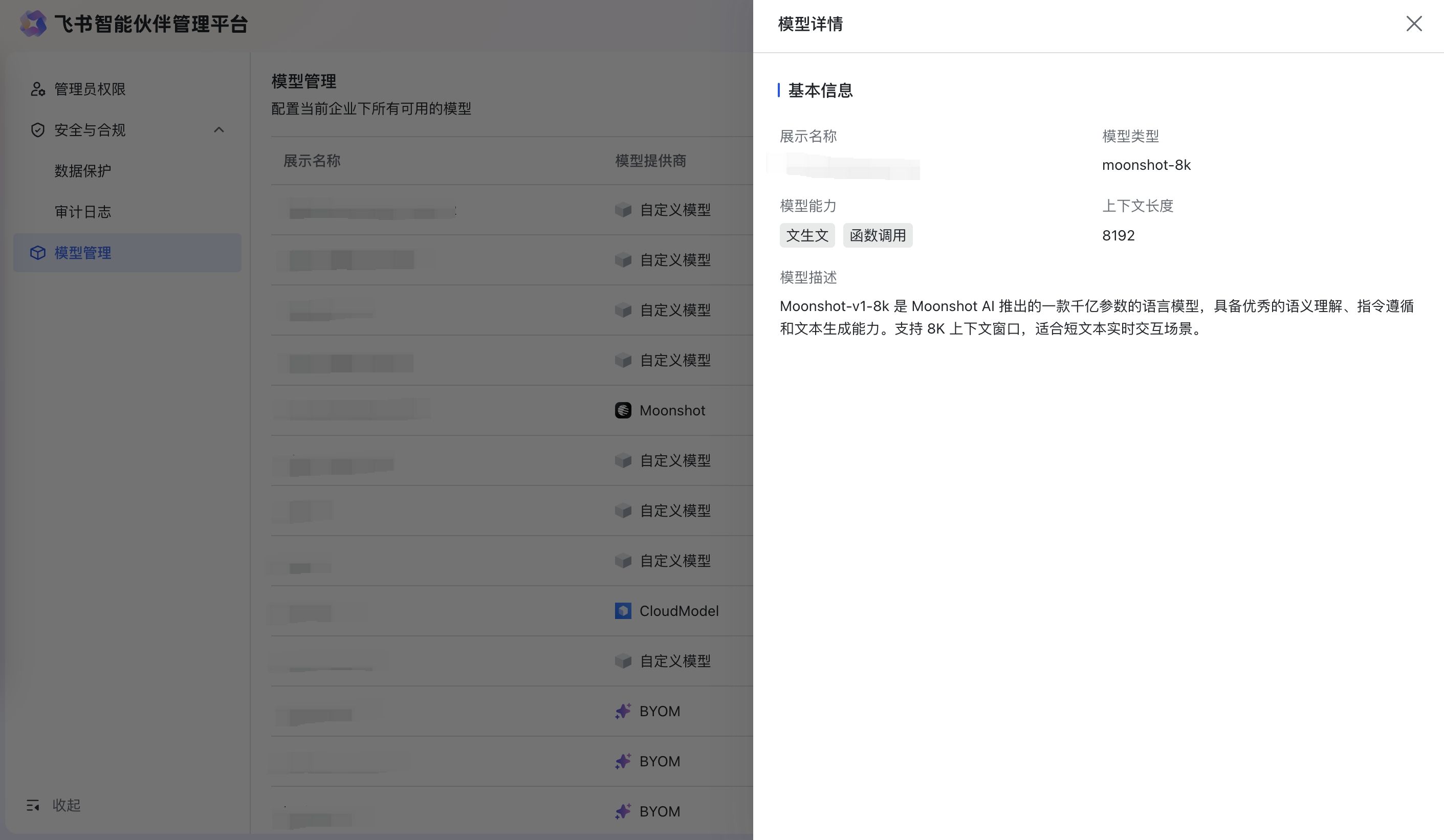
- 详情:点击详情可以查看配置模型的基础信息
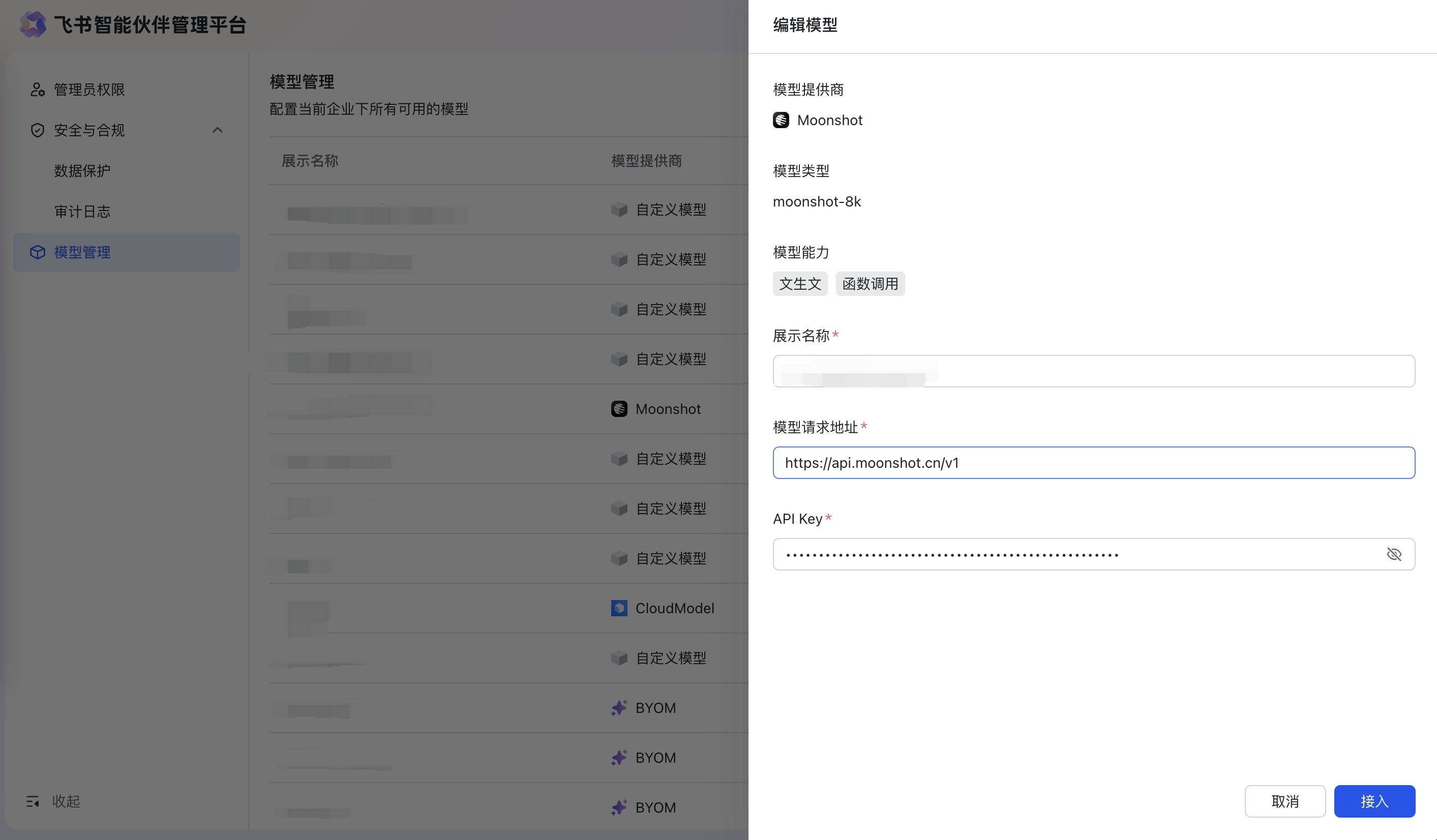
- 编辑:点击编辑可以进入编辑模型页面修改模型配置信息,编辑完成后保存,会提示“模型保存成功”
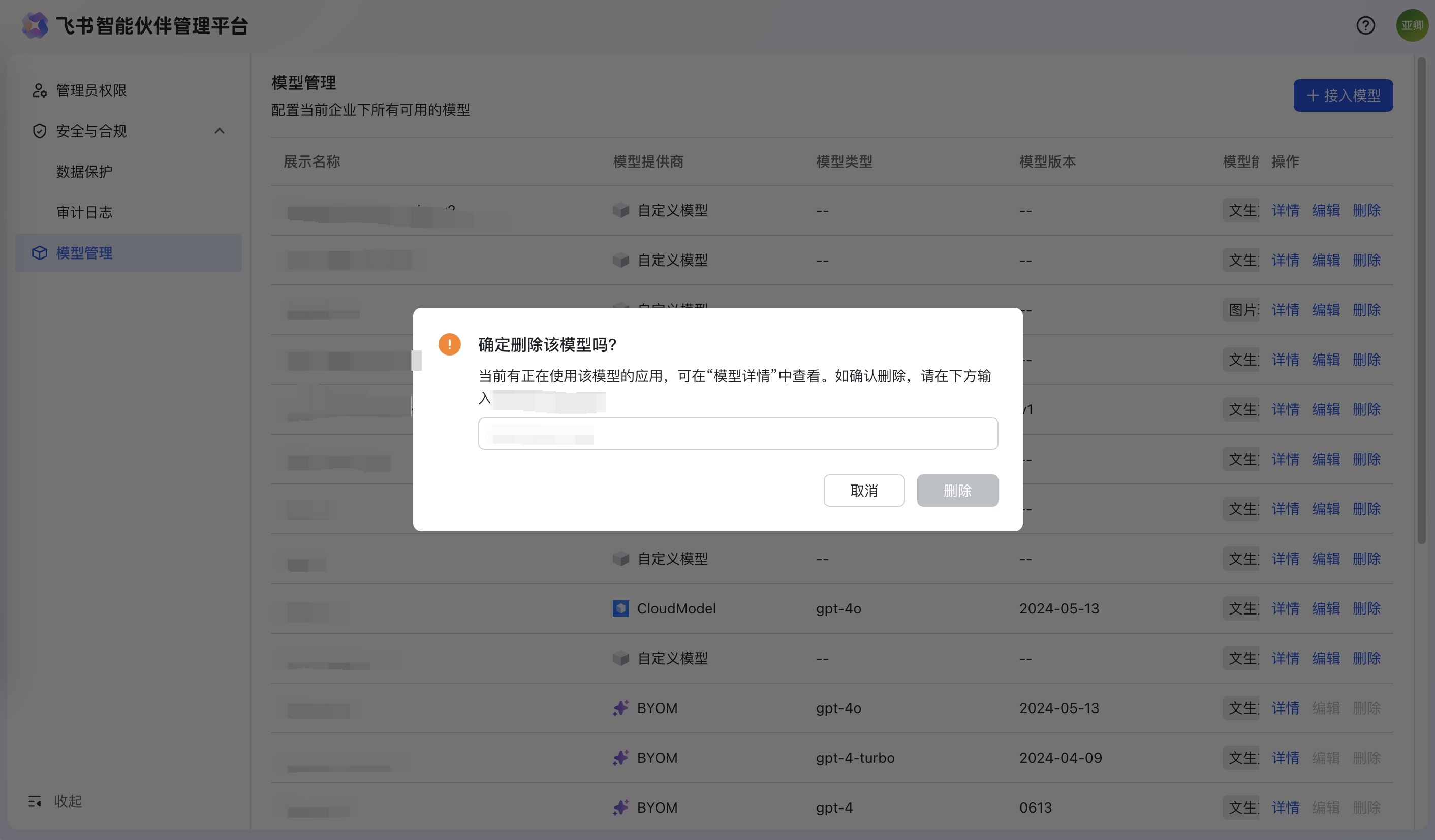
- 删除:点击删除,会弹窗提示用户并要求用户输入模型相关信息,删除成功后会有消息通知“模型删除成功”
250px|700px|reset
250px|700px|reset
250px|700px|reset
250px|700px|reset
- 应用设置自定义模型
- 企业管理员在模型管理后台添加好自定义/Cloud模型后,在应用中模型选择时可以选择企业已经增加好的模型。
如何选择适合的模型?
- 从端到端的体验出发,我们建议优先选择效果好的模型。效果好代表模型能够更理解你的需求,并且把你的任务做对。例如:数据分析,我们强烈建议使用 CloudModel-4-8K 和 CloudModel-4-32K。
- 在效果能接受的情况下,我们可以关注速度。例如:一些比较简单的总结类任务,我们可以适当尝试使用 CloudModel-3.5-Turbo-16K 这样的模型。
- 根据你的任务复杂度,匹配选择。对于一些复杂的任务,建议使用 CloudModel-4-8K 这类参数量比较大的模型;对于一些简单的任务,在保证效果的情况下可以适当选择一些参数量小的模型,以保证推理速度。
- 根据你的输入 Token 数,匹配选择。每一个模型都有对应的上下文窗口,如果你的输入 Token 数很大,则需要选择上下文窗口比较大的模型(例如:CloudModel-4-Turbo),或者你可以对输入进行切分,通过并行处理来降低单次给模型的 Token 输入数量。
接入自定义模型技术有哪些要求?
接口要求
调用方式 | 支持标准的 HTTP 调用 |
请求方法 | POST |
字符编码 | UTF-8 |
响应格式 | JSON 或 标准 Stream Event |
模型规格最小要求
tpm | >= 8k |
qpm | >= 5 |
窗口 | >= 2k |
模型入参要求
模型入参 遵从 open ai、glm、deepseek 厂商 主流的模型消息协议
模型出参要求
模型出参 遵从 open ai、glm、deepseek 厂商 主流的模型消息协议
相关文档
- 智谱模型调用文档
常见问题
总是出现 Token 超限的报错,什么原因?
如果你经常看见下面这种类型的报错:
“This model's maximum context length is 8192 tokens. However, your messages resulted in 459756 tokens. Please reduce the length of the messages”
这是在说明:你发送的消息的 token 数量,已经超过了大模型单次能够处理的 token 上限了。
首先我们要了解什么是 token。
token 通常指的是模型处理的输入文本的最小单位。对于英语而言,一个 token 可以是一个完整的单词,也可以是一个单词的一部分(例如,一个词根或一个前缀后缀),或者甚至是一个字符。每一个模型对 token 长度的定义不同,例如 OpenAI 的 GPT 给出过这么样的一个类比(详细可参考https://github.com/openai/tiktoken):
- 1 token ~= 4 chars in English
- 1 token ~= ¾ words
- 100 tokens ~= 75 words
Or
- 1-2 sentence ~= 30 tokens
- 1 paragraph ~= 100 tokens
- 1,500 words ~= 2048 tokens
而模型对 token 的限制一般会分为两部分,一部分称之为 Prompt Token,指的是你向模型提供的输入文本的 token 数量。这里包括了你的请求(prompt)和系统或用户的对话历史(chathistory);另一部分称之为 Completion Token,指的是模型生成的输出文本的 token 数量。这两部分任何一部分超过了模型的限制,都会出现Token超限的报错。
目前来说,一些市面上 context length 超长的模型(比如 GPT-4-turbo 有128k 的 context length),大部分加长的部分都在prompt token而不是completion token(比如128k的GPT-4-turbo本身只有8192的completion token长度)。
如何解决 token 超限报错问题?
如果你的场景里,“喂”给模型的 prompt token 很长,出现了 token 超限报错。那么可以选择更大 context length 的模型,或者缩减你的输入长度;如果是模型输出的 completion token 超限,那么建议你检查一下:是不是让模型按照了一定的格式或模板输出导致他的输出超限,或者在你的 prompt 中告诉模型“请回答得尽量精简。”
到底什么是Function Call?
模型本质是一个text-in,text-out的系统,本质并不具备直接调用函数的能力,但是有些模型可以在输出中生成一个JSON Object,这个JSON Object中可以包含调用函数或API所需的参数。一个包含LLM的系统中就可以借助模型生成的这个Object,完成对API或者函数的调用。
如果你遇到“模型不支持function call”这样的报错,说明你选择的模型没有经过相关的训练,不具备根据用户的输入判断需要使用什么样的函数并生成对应的结构化JSON Object的能力。









