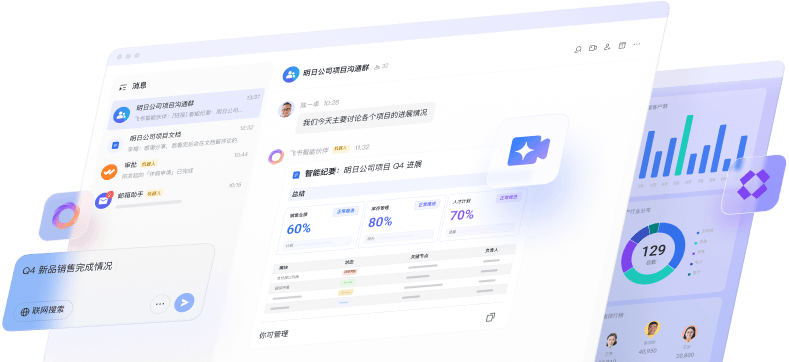
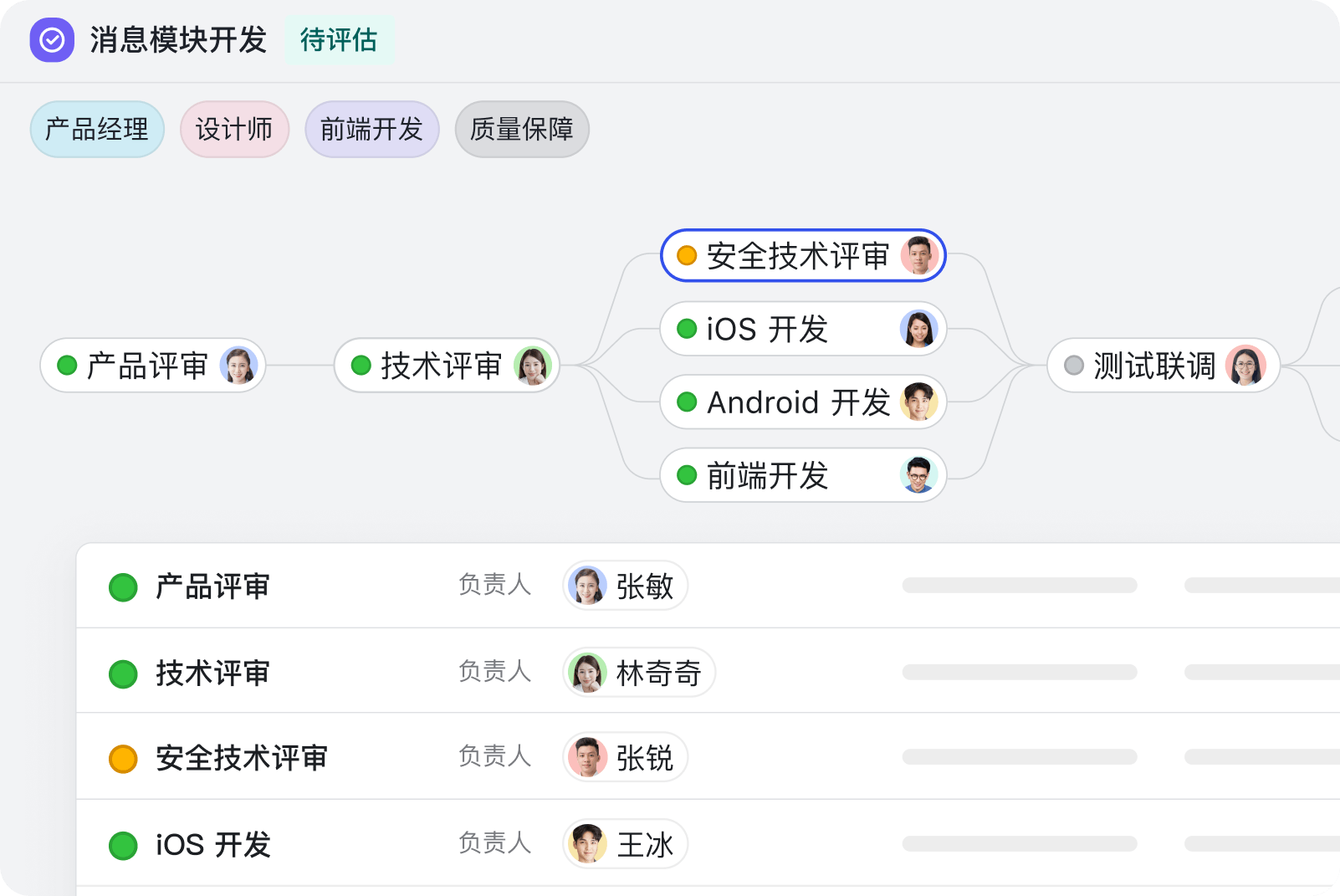
上周项目复盘会,产品经理翻了30个群聊记录找需求变更截图,运营翻了12张Excel找活动转化率数据,研发说「我之前发在群里的BUG列表找不到了」 ——这样的场景是不是很熟悉?90%的团队都在为「数据分散」买单:群聊里的文件过期、表格版本混乱、文档和任务脱节,最后复盘变成「找数据大赛」,真正该讨论的「为什么延期」「哪里可以优化」反而没时间说。
这篇文章要解决三个问题:
- 为什么你存的不是「数据资产」而是「数据碎片」?
- 项目数据沉淀的底层逻辑是什么?
- 飞书项目如何用系统能力终结数据分散?
📊 别再怪团队不会复盘:90%的项目数据死在「分散式存储」里
你以为的「数据沉淀」,其实是「数据碎片」:表格、群聊、文档的信息黑洞
我们常说「要沉淀数据」,但很多时候存的只是「数据碎片」:
- 群聊传文件:「@所有人 这是最新的需求文档」,三天后被新消息刷到100页后,没人找得到;
- Excel存数据:同一个项目有「需求清单_v1.xls」「需求清单_final.xls」「需求清单_最终版_final.xls」,到底哪个是最新的?
- 文档和任务脱节:文档里写了「用户登录模块要加验证码」,但任务里没关联,研发做的时候根本没看到。
传统存储方式的代价,远不止「找数据麻烦」:
| 存储方式 | 痛点 | 团队成本 |
|---|---|---|
| 群聊文件 | 易过期、难检索 | 找一个文件平均花15分钟 |
| Excel表格 | 版本混乱、无关联 | 整理版本需要2小时/周 |
| 独立文档 | 与任务脱节 | 重复沟通需求变更3次/项目 |
🔍 从「碎片」到「资产」:项目数据沉淀的3层逻辑框架
第一层:定义「可沉淀数据」——区分「过程垃圾」与「价值线索」
不是所有数据都值得存,要先区分「过程垃圾」和「价值线索」:
- 价值线索:能反推决策(比如「选A方案而不是B方案」的讨论记录)、支撑复盘(比如「延期原因」的沟通记录)、复用经验(比如「用户登录模块的测试用例」);
- 过程垃圾:「今天中午吃什么」的群聊、重复的测试数据、无最终版标记的草稿文档。
判断标准很简单:这个数据能帮下一次项目做得更好吗?能,就留;不能,就删。
第二层:建立「链路关联」——让任务、沟通、结果数据形成闭环
数据的价值在于「关联」,比如:
- 需求文档关联「需求评审」任务 → 研发做任务时能直接看到文档;
- 沟通记录关联「第三方接口延迟」问题 → 复盘时能快速定位原因;
- 结果数据(比如转化率)关联「上线」里程碑 → 能直接看目标完成情况。
飞书项目的「链路关联」逻辑,就是把这些数据「串成一条线」:需求→任务→沟通→结果,每一步都有迹可循。
第三层:设计「复盘接口」——把数据变成下一次项目的「参考公式」
沉淀数据不是目的,是为了「复用经验」。比如:
- 上一个项目「第三方接口延迟」导致延期 → 这次项目启动时,系统自动提醒「提前确认第三方工期」;
- 上一个项目「需求变更」占延期原因的40% → 这次项目模板里自动加「需求变更审批流程」。
飞书项目的「复盘接口」,就是把这些经验变成「可复制的公式」,直接套用到下一个项目。
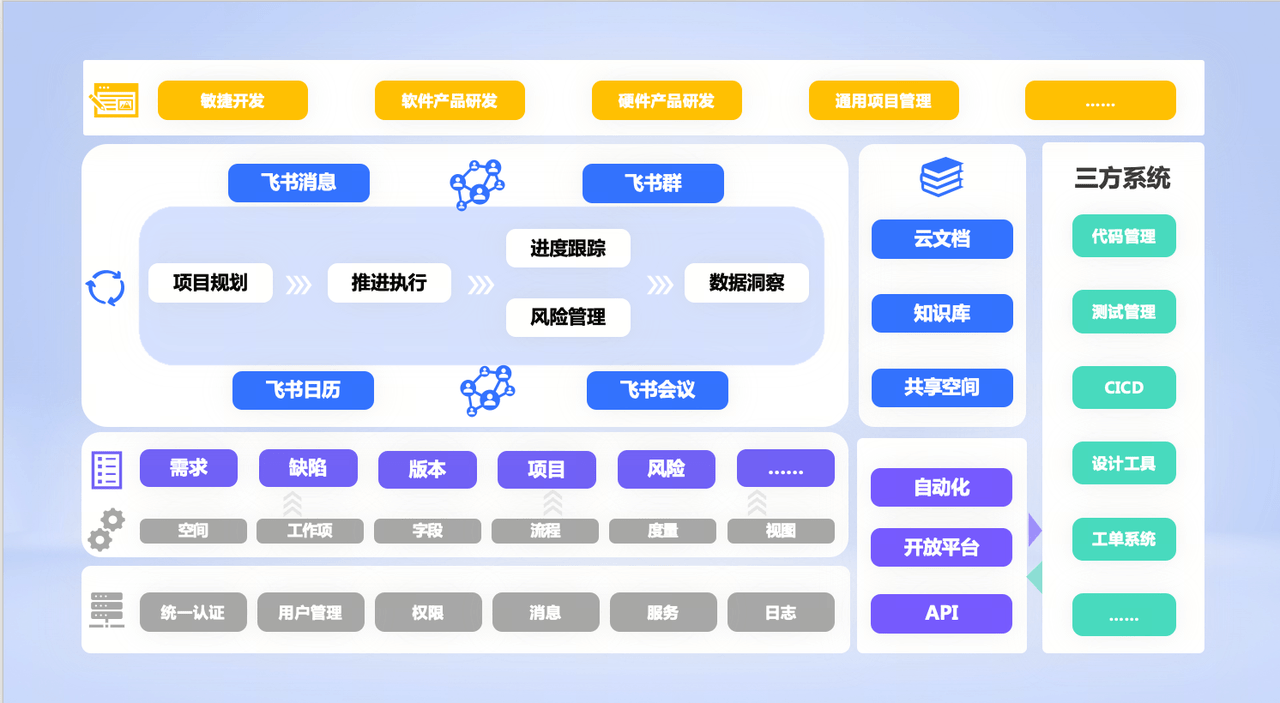
🛠️ 飞书项目:用「系统级沉淀」终结数据分散的5个关键能力

「项目全景页」:从需求提出到上线,所有数据自动串成「时间线」
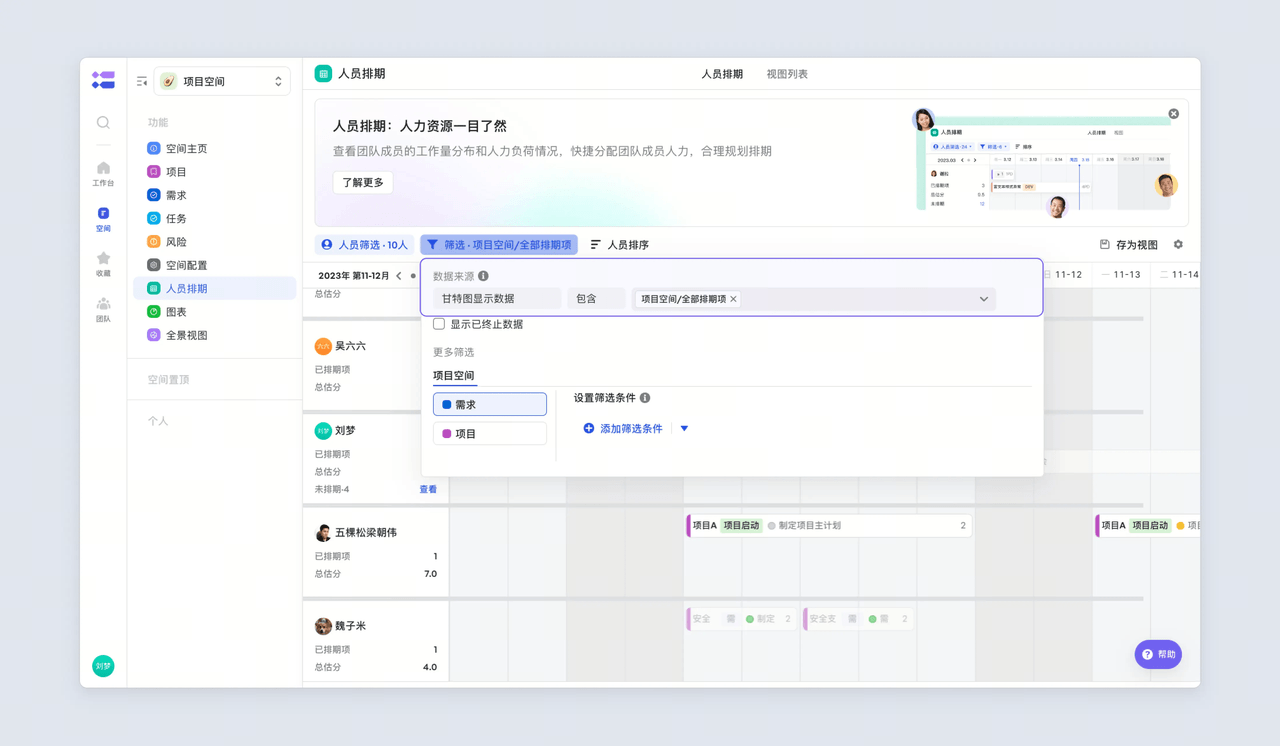 飞书项目的「项目全景页」是数据的「总地图」:从需求提出(文档)→任务分配(研发、设计)→里程碑交付(原型、测试报告)→上线结果(转化率),所有数据按时间线自动排列。
飞书项目的「项目全景页」是数据的「总地图」:从需求提出(文档)→任务分配(研发、设计)→里程碑交付(原型、测试报告)→上线结果(转化率),所有数据按时间线自动排列。
比如想找「需求变更」的节点,点一下时间线里的「2024-03-15 需求变更」,就能看到:
- 当时的文档版本;
- 沟通记录;
- 任务调整记录。 不用再翻5个工具,10秒就能找到所有数据。
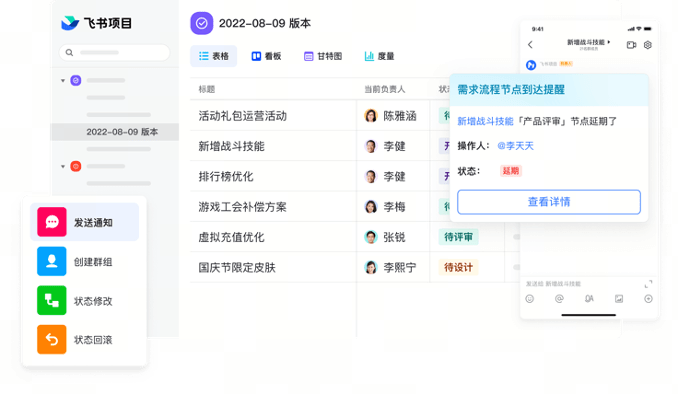
「过程资产库」:会议纪要、任务反馈、文档版本一键关联项目节点
以前会议纪要存文档、任务反馈存群聊、文档版本存本地,现在飞书项目把这些都「绑」在项目节点上:
- 会议纪要:开完项目例会,直接关联到「需求评审」节点;
- 任务反馈:研发在任务里写「这个BUG需要前端配合」,自动同步到资产库;
- 文档版本:文档修改后,自动保存版本并关联到对应的任务。
要找「需求评审」的所有资料?点一下资产库的「需求评审」节点就行,不用再打开3个工具。
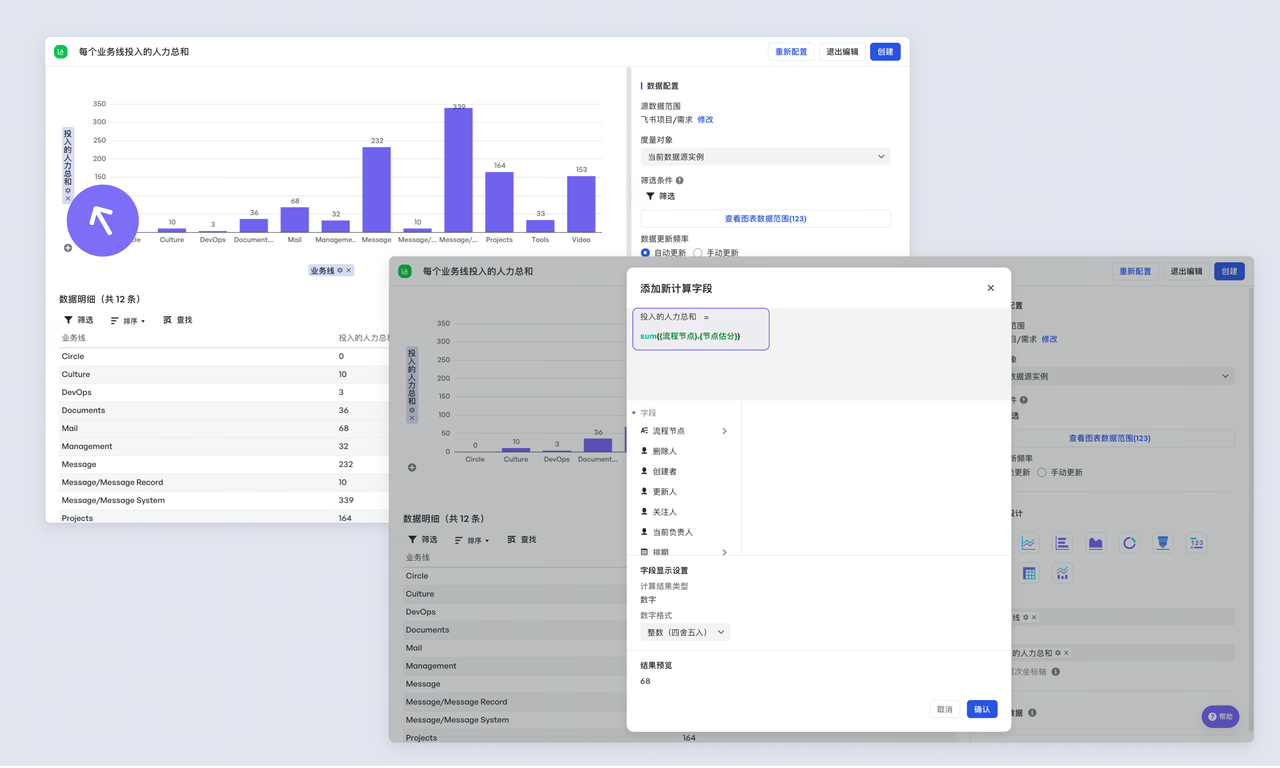
「复盘模板库」:自动提取关键数据,生成带数据支撑的复盘报告
 以前写复盘报告,要手动填「项目进度」「延期原因」「优化点」,还要翻各种数据——飞书项目的「复盘模板库」能自动做这些:
以前写复盘报告,要手动填「项目进度」「延期原因」「优化点」,还要翻各种数据——飞书项目的「复盘模板库」能自动做这些:
- 项目进度:自动生成「实际 vs 计划」的对比图;
- 延期原因:统计「第三方接口延迟」「需求变更」等占比;
- 优化点:从上一个项目的复盘里提取「提前确认第三方工期」等建议。
比如做「内容运营项目」的复盘,模板会自动拉取「文章阅读量」「转化率」「留言数」等数据,直接生成带图表的报告——比人工整理快3倍。
❓ 相关FAQs
飞书项目能整合外部工具的数据吗?比如Jira、Excel?
 能!飞书项目支持整合Jira、Excel、钉钉等外部工具:
能!飞书项目支持整合Jira、Excel、钉钉等外部工具:
- Jira:同步Jira任务到飞书项目,实时更新进度;
- Excel:导入Excel表格,自动关联到对应任务/节点;
- 其他工具:通过开放API整合更多数据。 不用切换工具,就能在飞书项目里看到所有数据。
团队用惯了群聊传文件,切换飞书项目会不会增加学习成本?
不会!飞书项目的设计「贴合用户习惯」:
- 操作和飞书一致:上传文件和群聊一样简单,只是自动关联项目节点;
- 引导式操作:第一次用会提示「把文件关联到节点」「把任务关联到文档」;
- 培训支持:免费提供操作指南+专属顾问解答。 根据用户反馈,团队切换的学习成本平均只要1天。
🌟 从「数据留存」到「价值放大」:项目管理的下一个进化方向
不是「存数据」,而是「让数据会说话」——飞书项目的价值逻辑
 飞书项目不是「数据仓库」,而是「数据翻译官」:
飞书项目不是「数据仓库」,而是「数据翻译官」:
- 风险提醒:当「第三方接口延迟」超过预警值,系统自动发通知;
- 决策指导:项目进度落后时,推荐「优先解决关键路径任务」;
- 经验复用:上一个项目的「优化点」自动同步到下一个项目模板。 比如做「软件研发项目」,系统会提醒「上次这个模块延期是因为测试没跟上,这次要提前安排」——这才是数据的价值:帮你做决策,而不是躺在硬盘里。
用系统沉淀代替人工整理,把团队精力放回「创造价值」上
以前团队花30%的时间整理数据,现在用飞书项目后,这个时间降到5%:
- 不用找文件:数据都在全景页/资产库;
- 不用整理版本:文档自动保存版本;
- 不用写复盘报告:模板自动生成。
团队能把精力放回「优化产品」「提升用户体验」这些创造价值的事上——毕竟,项目管理的核心不是「管数据」,而是「管价值」。
从「数据分散」到「系统沉淀」,不是工具的变化,而是项目管理思维的进化。飞书项目用系统能力把数据「串起来」「绑起来」「用起来」,让复盘不再是「找数据大赛」,让团队精力放回「创造价值」。
如果你也想终结「数据孤岛」,不妨试试飞书项目—— 欢迎联系我们,飞书效能顾问将为您提供全力支持