在知识问答中,提供了「标准问答库」的功能。可用于沉淀业务场景的高频问题及其答案,用于提升高频问题的问答速度、答案一致性,或降低 LLM 的 Token 消耗。

250px|700px|reset
标准答案库下面两种场景:
- 标准问答对:(一个或多个)问题对于一个标准答案,可用于
- 前置拦截:按照问题进行匹配,找到匹配的问答对则直接输出对应的答案。
- LLM 生成:在数据问答环节中,召回相关的标准问答对,作为上下文给 LLM 进行生成。
- 数据查询模板:结构化数据查询的 SQL 模板。在数据问答的运行链路中,若匹配到对应的数据查询模板,替换 SQL 模板中的相关变量便可直接用于 SQL 查询。
下面分别介绍下这两者。
标准问答对
问答对的配置入口
在 知识问答->标准问答库->标准问答对 提供了标准问答对的配置和管理入口。
- 知识问答->标准问答库

250px|700px|reset
- “标准问答对”页签

250px|700px|reset
问答对的配置、维护
问答对的新建、编辑或删除
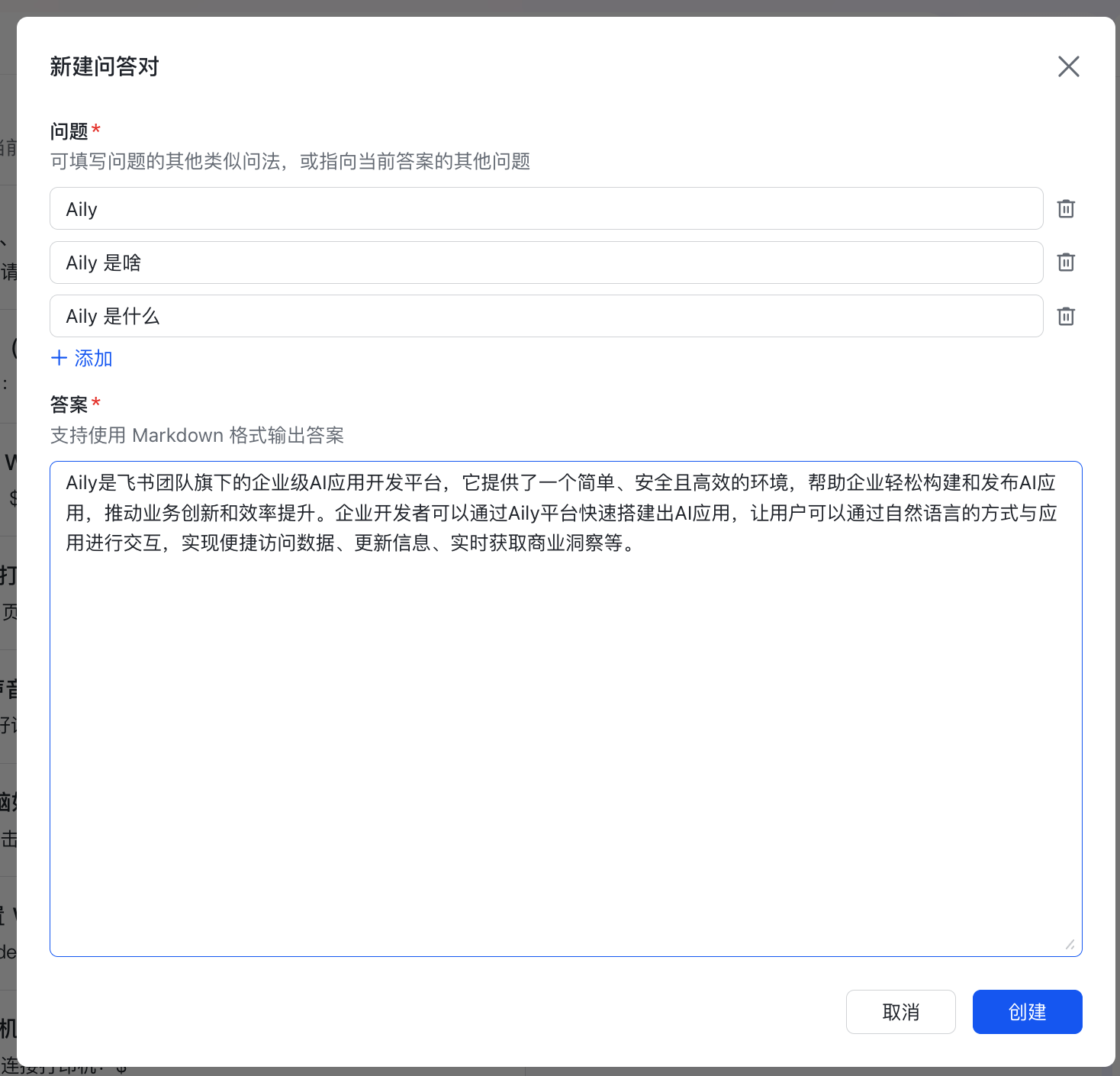
每个问答对由两部分组成:
- 问题
- 可填写一个或多个问题。
- 每个问题最大长度 200 个字符。
- 答案
- 最大长度 2000 个字符。
250px|700px|reset
问题应该如何配置才能更好匹配?
在本系统中,主要通过语义匹配增加泛化性。对于这类的 Q(问题),配置有一定的要求,才能使得在后续的检索、模型计算中,达到预期的效果。
配置要求总结起来就是:
配置的 Q(包括标准问以及对应泛化出的相似问题)需要是语义清晰、表述完整的一句自然语言。
问答对的前置拦截
标准问答对可用于 AI Bot 的前置匹配。
若 AI Bot 开启了“标准问答对匹配”,则用户问题会先跟标准问答对中的问题进行匹配,找到匹配度超过阈值(注:现阶段为了保障拦截的准确率,暂不开放阈值配置能力)的标准问答对,则直接输出匹配度 Top1 的标准问答对的答案。
标准问答对的前置匹配可解决提升高频问题的响应速度和答案的稳定性,同时避免每次均需要 LLL 处理而产生的 Token 消耗。
250px|700px|reset
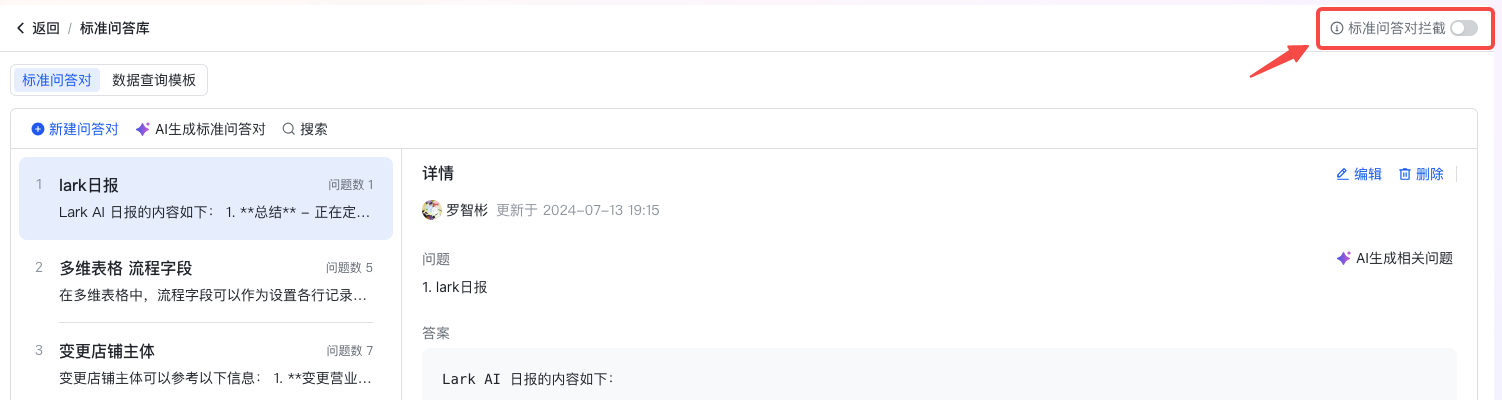
前置匹配的开启与关闭
在标准问答库右上角提供一个标准问答对前置匹配的功能开关。
- 可选择开启或关闭 FAQ 拦截。
- 默认是关闭的。
- 注:前置匹配的功能开关的开启或关闭,区分开发环境与线上环境,有变更需要 AI Bot 重新发布下,才会对线上环境生效。
250px|700px|reset
前置匹配逻辑
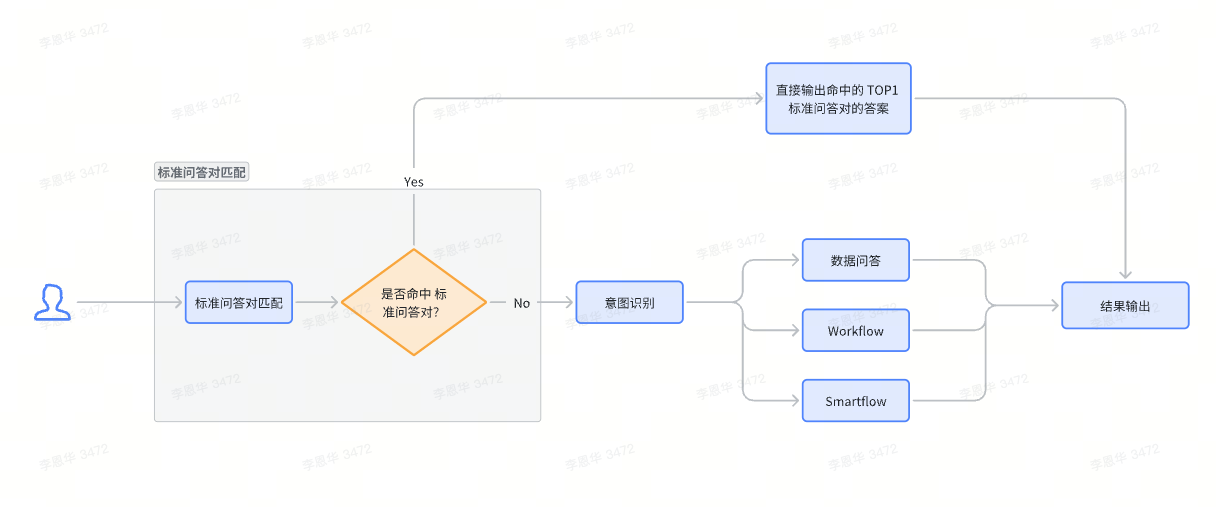
运行链路
若开启了标准问答对拦截,那么在一个用户问题进来后,
- 先与标准问答对中的所有问答对的问题进行相关性匹配。
- 若找到相关性匹配度比较高的标准问答对,则直接将该问答对的答案直接输出给用户。
- 否则,执行后续的意图识别+技能执行的流程。
匹配逻辑
- 将用户问题与标准问答对中所有问答对的问题进行相关性匹配(综合关键字或语义相似性匹配)。
- 若某个问答对存在某个问题与 用户问题 相似度比较高,则表示命中了该问答对。
注:为了保障准确率,阈值内置,暂不支持配置。
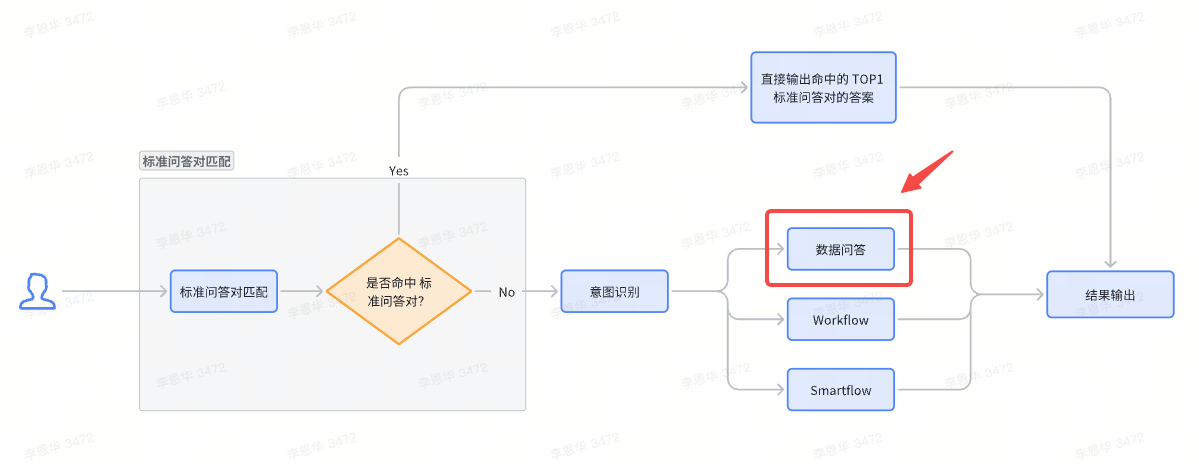
问答对的召回与 LLM 生成
在数据问答环节,会检索与用户问题相关度符合阈值条件的知识内容,然后组装成上下文,给到 LLM 来进行总结提炼,生成问题的答案。
在知识检索阶段,除了数据资产中的非结构化数据之外,也会从标准问答对中检索相关知识。
250px|700px|reset
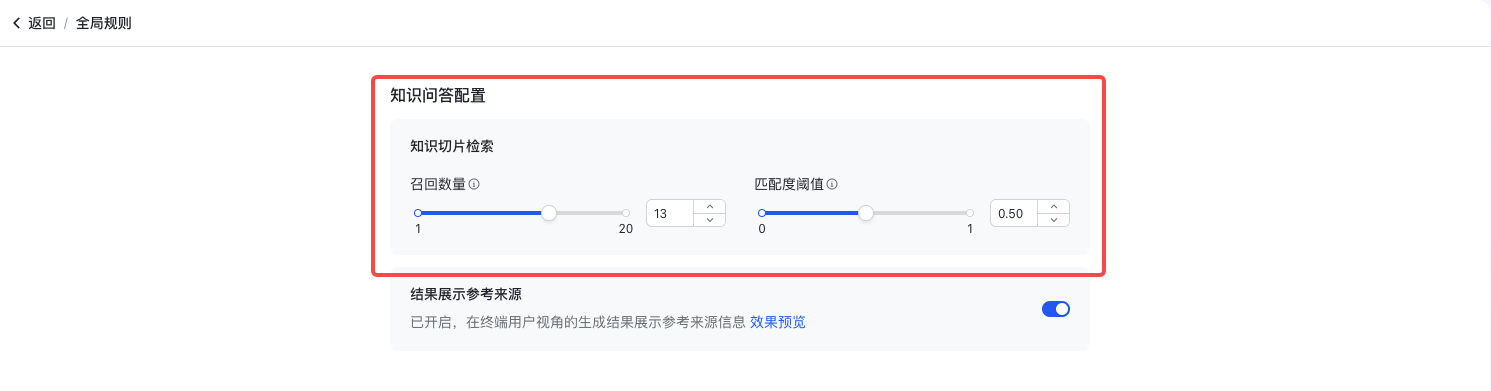
检索参数
标准问答对的检索参数共用了 知识问答->全局规则 中的“知识问答配置” 中的 召回数量 和 匹配度阈值。
250px|700px|reset
检索匹配
匹配逻辑
- 标准问答对的索引:问题 + 答案
- 每个标准问答对的主问题(第一个问题) + 答案 拼接成一个完整知识切片,并建立索引。
- 标准问答对的匹配:混合检索
- 全文检索 + ES 关键词检索
- 语义相似度检索
检索效果
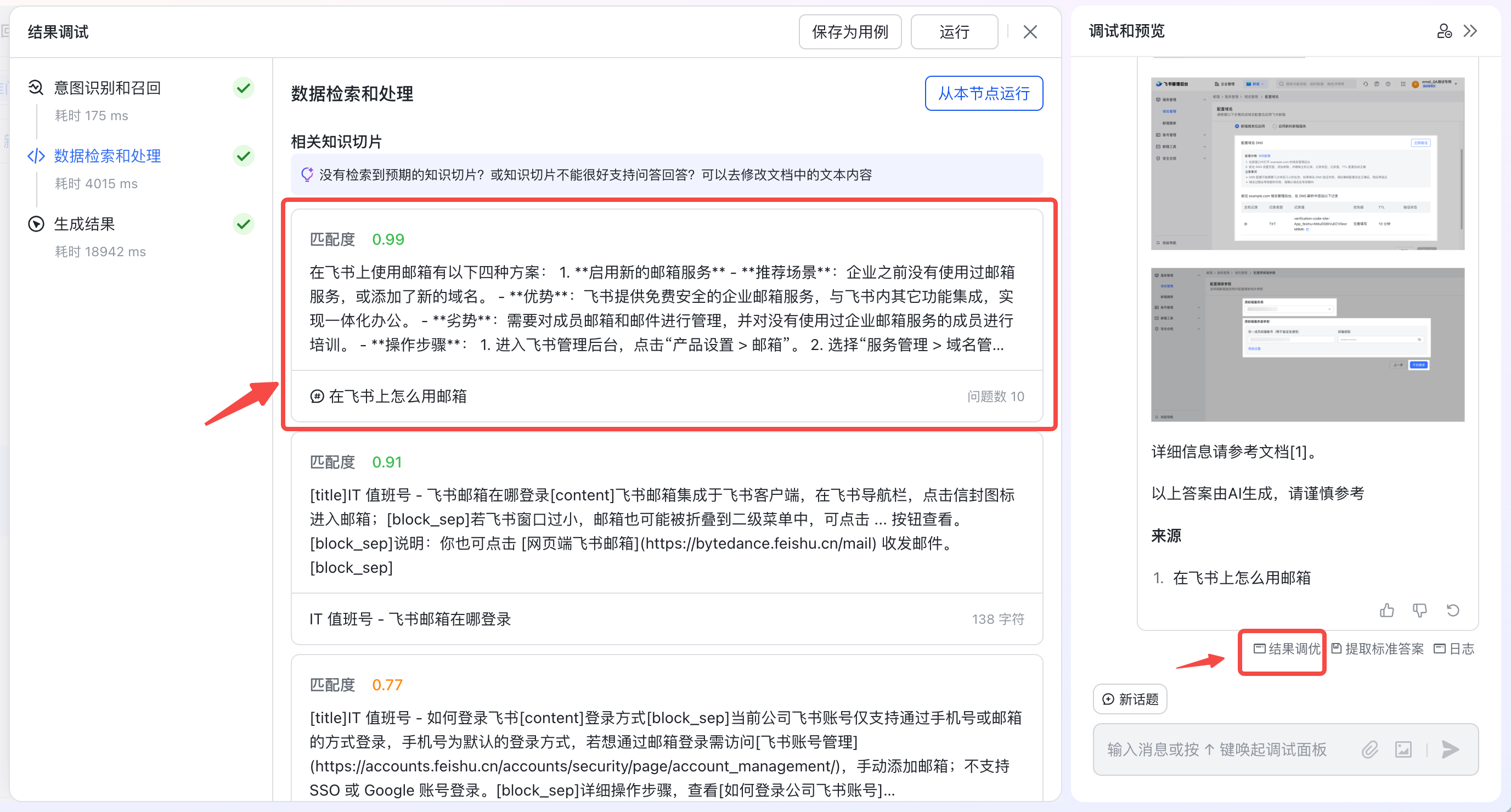
在知识问答调试预览时,可以通过以下两个途径来查看检索到的标准问答对数据。
- 点击「日志」按钮,展开运行过程的”获取数据“环节的输出中,可以查看到匹配的标准问答对数据。
- 点击「结果调优」按钮,在调优台的”数据检索与处理“环节,查看到匹配的标准问答对数据(可快捷修改标准问答对数据)。
250px|700px|reset
问答对数据与配置的发布
在 知识问答->标准问答库->标准问答对 中更新的问答对数据、前置匹配开关的开启/关闭 等配置,默认只会在 AI Bot 开发环境生效。需要点击右上角的「发布」,将 AI Bot 的变更发布后,才会在该 AI Bot 的线上环境生效。

250px|700px|reset