前言
使用「飞书低代码平台」这样的 aPaaS 平台搭建应用时,可以轻松在无代码搭建的部分配置出非常复杂的查询条件。然而,数据量大 + 查询条件复杂 = 查询超时。
通过阅读本文,你可以了解:
- 哪些功能比较影响性能?
- 在零代码和低代码场景下,如何优化性能?
用 Excel 比喻数据存储模型
一个对象对应一张工作簿,一条记录对应一行,一个字段对应一列。
每条记录都有唯一的 ID (即系统字段 ID),这是一个整数,可以理解为 “行号”。
一个对象的全部记录按照 ID 排序存储在工作簿中,“关联对象” 列存储的就是所关联的记录 ID。
ID 的顺序与创建时间大致一致 (短时间内创建多条记录时,ID 顺序和创建时间不保证完全一致)。
根据 ID 查询记录是非常快的,就像告诉你找工作簿中的第 998 行内容一样,你可以飞快地拉到那里。
一个对象即一张存储在关系型数据库中的数据表。五个系统字段(ID、创建人、更新人、创建时间、更新时间)都是默认建立索引的
哪些功能比较影响性能
有些功能用起来挺容易、挺方便,但在后端系统运行的过程是更复杂的,体现在终端用户就是影响页面加载性能。如果你搭建的应用预期的数据量比较大 (几十万上百万),那么要谨慎使用如下功能:
- 指标卡、数据表格末尾页、排序条件
- OR 条件
- 为空、不等于、不属于、不包含
- 关联查询 (又称下钻查询,比如 “用户.部门.管理员.邮箱 属于 [邮箱列表]”)
- 层级查询 (包含所有上级)
- 公式中的 FILTER 函数
- 多角色数据权限 (一个用户在一个页面上拥有多个角色,这些角色有各自的数据权限,这时各自的数据权限之间是 OR 关系)
- 通讯录范围同时配置部门和指定人 (本质也是 OR 条件,部门条件和指定人条件之间的 OR)
并不是说这些功能不能用,只是说用到这些功能的时候,需要注意:
- 数据总量不要太大,建议在 100 万以内,否则可能因性能问题而无法正常使用。
- 如果有复杂的查询条件 (OR 条件、关联查询、公式 FILTER 函数一起出现),则建议在 10 万以内,或者需要有专业的开发者来优化对象模型、索引配置和查询条件。
这些功能可能会产生如下影响:
- 导致全表扫描
- 需要额外关联表
- 导致优化器难以选择最优计
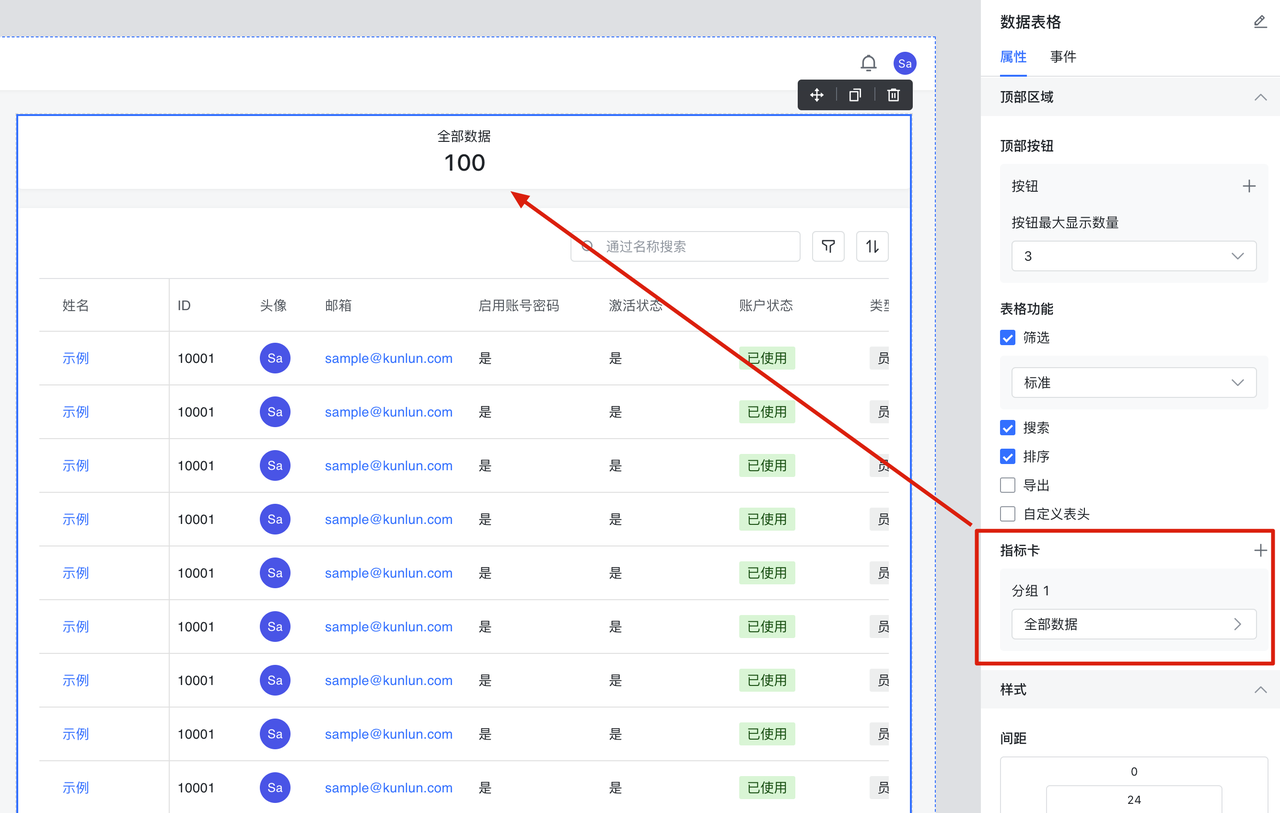
指标卡、末尾页、排序条件
这三样性能差的原因是相似的:它们都需要查找整个工作簿。与之相对的,我们打开数据表格的第一页时,只需要在工作簿中查找符合条件的 20 条记录,即便我们把分页调到最大 100 条,性能区别也不大。
- 指标卡:展示满足条件的记录数量,需要查找整个工作簿,数一下满足条件的有多少记录。
- 末尾页:假如一共有 10000 条记录,其中符合条件的记录有 5000 条,平均分布。获取第一页的 50 条只需要查找前 100 条记录,而获取最后一页 (第 100 页) 的 50 条记录,则需要查找全部的 10000 条记录,获取第 90 页的 50 条记录,则需要查找前 90 * 50 * 2 = 9000 条记录。
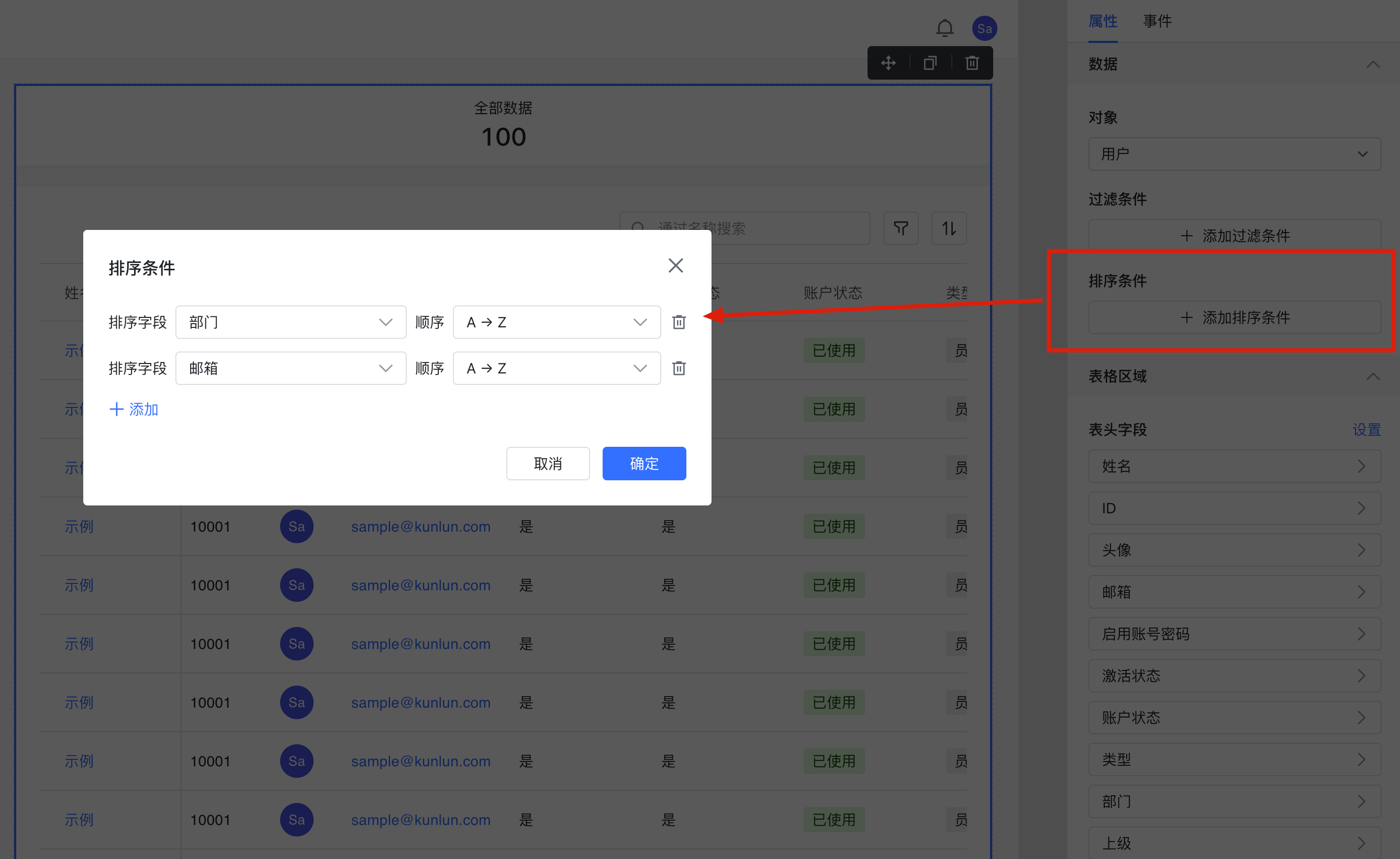
- 排序条件:如果我们设置了排序条件,那么无论翻到的是第几页,都需要查找整个工作簿,拿到所有符合条件的记录之后进行排序,然后再找到对应页的记录。不过,按照 ID、创建时间、更新时间排序是例外,因为本身记录在工作簿中就是按照 ID 排序的,不需要额外进行排序。但这仅限于按照单字段排序,如果设置了多个排序字段,那么还是要查找整个工作簿。
250px|700px|reset
250px|700px|reset
创建时间、更新时间排序和 ID 排序相似,因为有索引,所以不需要全表扫描。
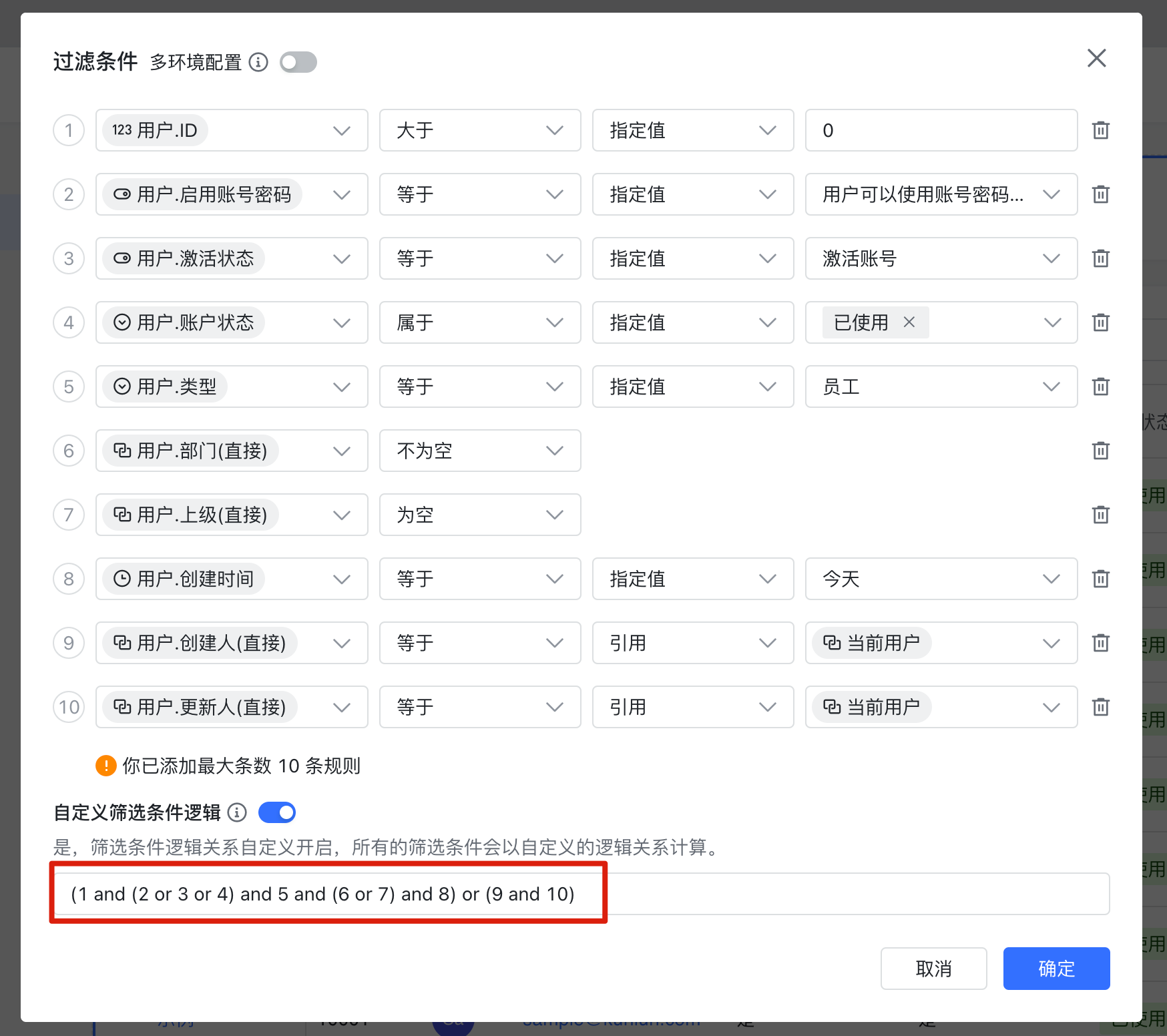
OR 条件
单从性能角度考虑,我们更喜欢 AND 条件,而不喜欢 OR 条件。举个例子就很容易明白了:
- 查询 ID 属于 [1, 2, 3] AND 部门 等于 X 的记录
- 查询 ID 属于 [1, 2, 3] OR 部门 等于 X 的记录
想象我们在工作簿中查找条件 1 的记录,只需要根据 ID 定位到 1, 2, 3 然后看一下这三条记录的部门是否为 X 即可 (还记得我们说过,根据 ID 查询记录非常快吗?);但是查找条件 2 的记录,我们需要查找过整个工作簿,看看是否满足部门为 X 或 ID 为 1, 2, 3 —— 不能仅仅找到 1, 2, 3 这三条记录啦。
250px|700px|reset
不过,OR 条件也不是任何时候都会使性能变差 (但肯定不会更好),如果原本的单个条件就必须要查找整个工作簿了,那么无论加多少个 OR 也还是查找整个工作簿。比如 “查找性别为男的员工” 和 “查找性别为男或天秤座的员工” 都是一样的要查找整个工作簿。
非等值运算符
查询数据的时候,不同的运算符性能也是不同的。按照性能从好到差,可以大致认为:
- 等值运算符,等于、属于
- 比较运算符,大于、小于、早于 (其实就是日期类型的小于)、晚于
- 判空运算符,为空、不为空
- 其他运算符,包含、包含任一、不包含、不属于、不等于
这个其实也很好理解,比如在工作簿中找到第 13 和 999 行数据 (“属于” 运算符),和找到行号大于 500 的数据 (比较运算符),和找到行号不等于 666 的数据,这三类查询的运算量明显一个比一个大。
本质还是能否利用索引,以及如何利用索引。上述 1 对应索引查找,2 对应索引扫描,3 对应全表扫描,4 对应全表扫描或子查询/关联表。
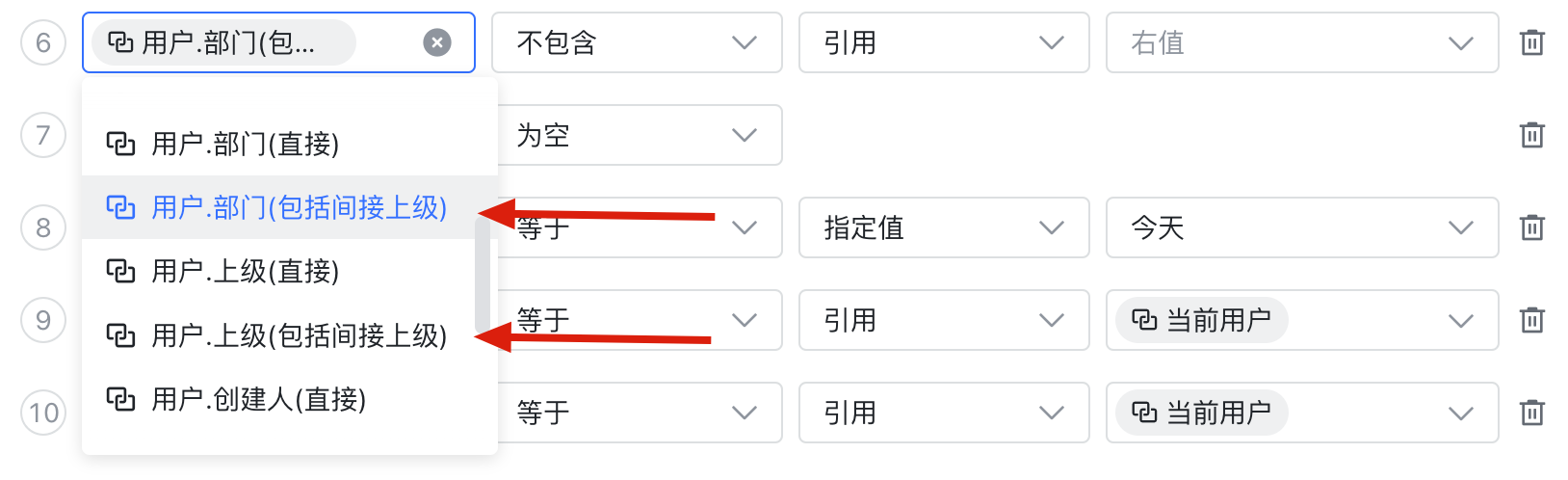
层级查询
当查询条件的左值带有 “包含所有上级” 时,就是层级查询了。
250px|700px|reset
比如查询 “部门 (包含所有上级部门) 等于 X” 的员工,就是查询部门 X 以及其所有下属部门中的员工。
这个场景,我们的工作簿可能长这样:
员工 | 部门 |
A | X |
B | Y |
C | Z |
(员工的工作簿)
部门 | 上级部门 |
X | |
Y | X |
Z | X |
(部门的工作簿)
这一个上面那个查询实际上会查出 A, B, C 三个员工,系统后台是怎么做到的呢?是不是想想就挺复杂的。所以层级查询也是一个略吃性能的功能。
对于开启了层级的字段,我们会将层级信息额外存储到一张数据表中,在查询时关联这张表。
这张表的关键列是 (record_id, parent_id, distance),表示 parent_id 是 record_id 的祖先,距离为 distance. 上面部门的例子将会存储成 (X, X, 0), (Y, Y, 0), (Y, X, 1), (Z, Z, 0), (Z, X, 1)
关联查询
关联查询指的是使用关联对象上的字段进行查询,有时候我们也叫成 “下钻查询”。

250px|700px|reset
比如用户对象上有关联字段 “部门”,关联到部门对象:
- 查询 “用户.部门 等于 X” 的用户不是关联查询,因为在实际查询时,部门 X 会被转换成 ID 然后只需要在用户对象的工作簿上查找
- 查询 “用户.部门.管理员 等于 Y” 的用户是关联查询,因为在用户对象的工作簿上找不到部门的管理员,管理员是属于部门对象的工作簿的字段。所以这个查询需要在两张工作簿上查找。实际过程可能是先到部门工作簿查找到所有管理员为 Y 的部门的 ID,然后再到用户工作簿上查找到属于这些部门的用户;也可能是先在用户工作簿中查找用户,每找到一个用户就去部门工作簿查找这个用户的部门的管理员,判断是否为 Y.
总结就是:关联查询一定会涉及两张及以上工作簿。
飞书低代码平台的易用性使得我们点点鼠标就能配置出很多级的关联查询,比如线上一个真实的查询是 “项目.用户扩展信息.用户.部门 (包含所有上级部门) 包含任一 X”,这样的一个查询会涉及很多很多张工作簿,这就意味着性能风险。看前面那个简单例子,只有两张工作簿时,我们都有两种不同的查询方案 —— 这是底层查询引擎需要决策的地方,要选出最优的查询方案,而工作簿比较多时,备选方案数也就会变多,选出最优的方案也就变难了。
查询优化器需要决策关联表顺序和索引等。
有时我们还会产生子查询,这时就更难选出最优计划了。
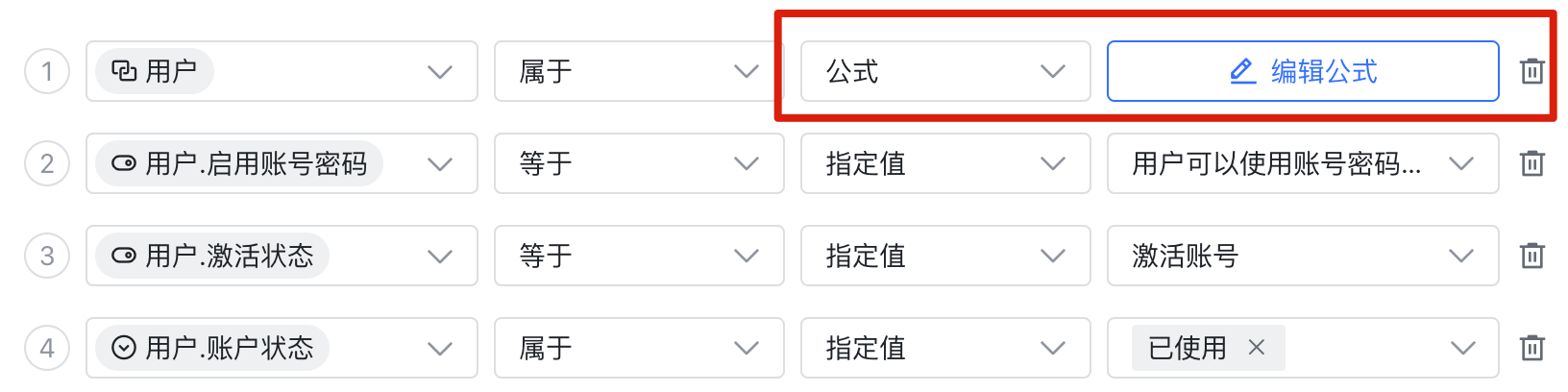
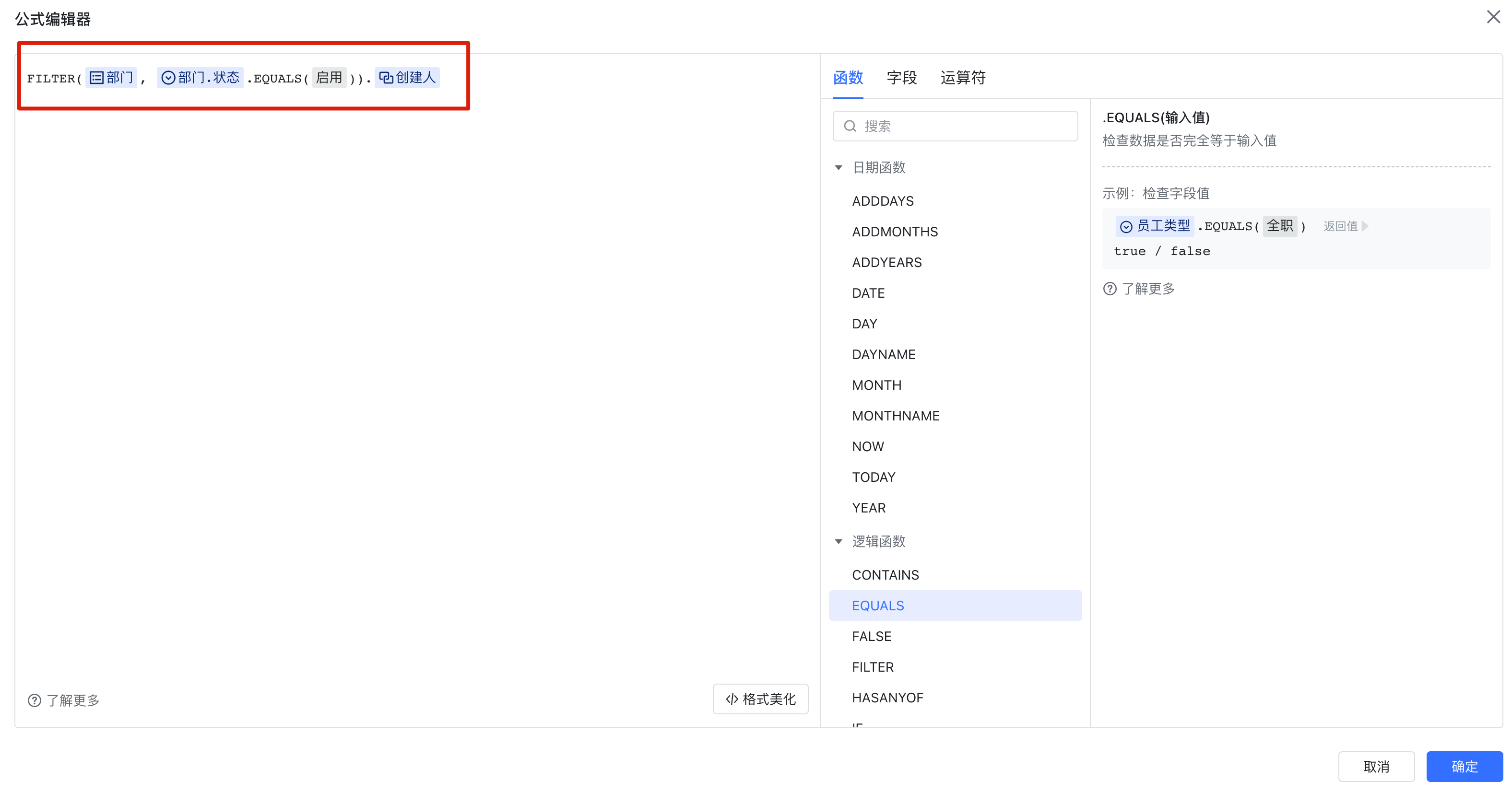
FILTER 函数
250px|700px|reset
250px|700px|reset
FILTER 函数和关联查询类似,都是涉及多张工作簿的查询。但 FILTER 函数比关联查询更吃性能,因为针对 FILTER 函数的优化方案更少。举个例子:
- 用户.部门.管理员 等于 X
- 用户.部门 属于 FILTER(部门, 管理员 等于 X)
这两个查询是等价的,但是前者,关联查询,在前面我们提到了有两种查询方案;而后者,FILTER 函数只有一种查询方案,就是先查出来管理员为 X 的部门,然后再去用户工作簿中查询属于这些部门的人。如果 FILTER 函数结果集较小,那么还好;如果 FILTER 函数结果集较大,想一想,这时即便是 ID 查询,查询 ID 属于 [一个长度为一万的 ID 列表] 的记录,是不是也很痛苦。
所以如果 FILTER 函数对应的对象记录数较多,或者 FILTER 函数中的查询条件能匹配的记录数较多,那么就要当心性能风险了。
数据库可以把子查询优化成 Semi-Join, 但不是所有时候都会。
关联查询涉及多值 Lookup 时则可能产生子查询而不是关联表。
FILTER 函数一定会产生子查询
No Code 优化方式
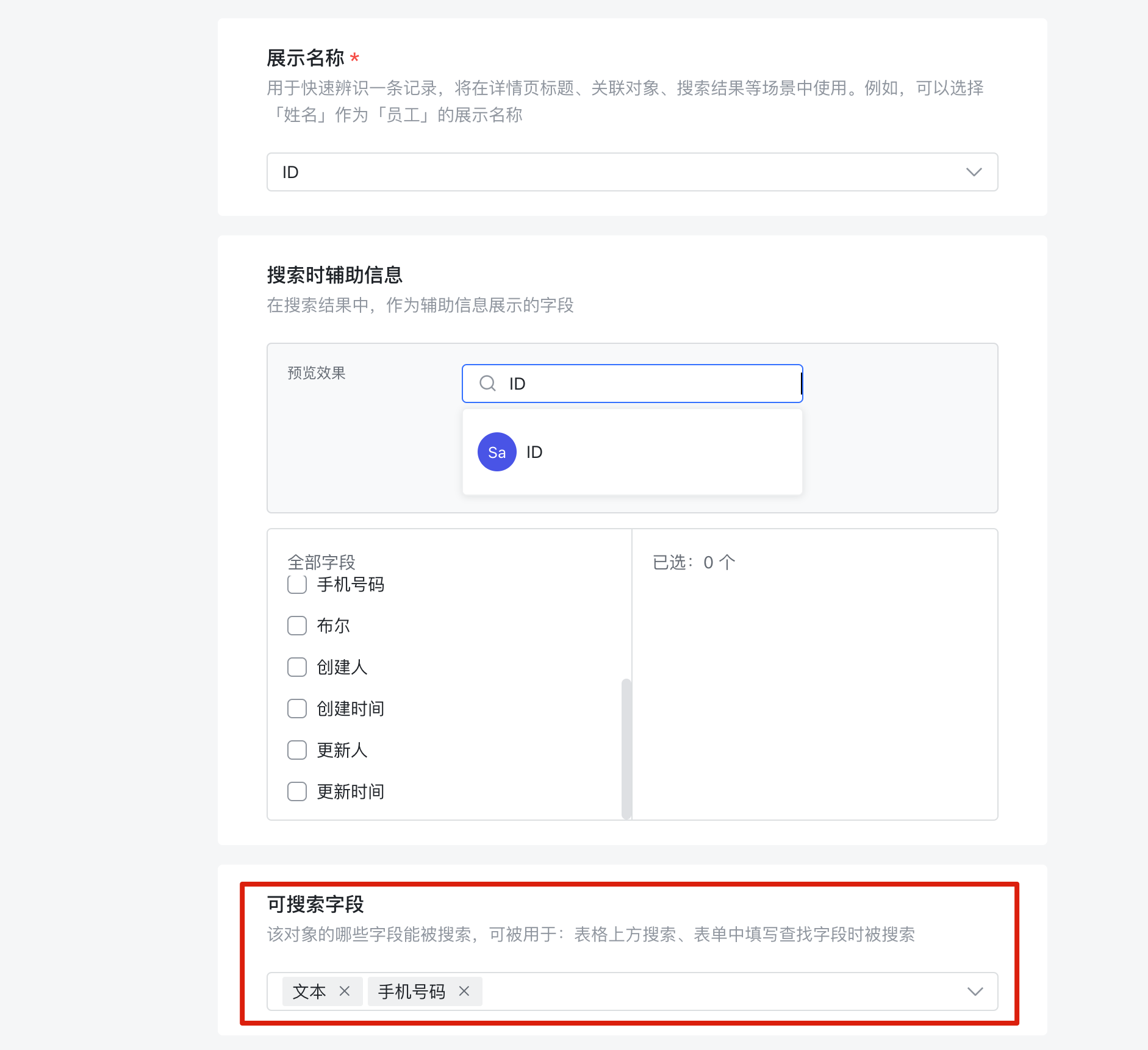
高频查询字段设置为可搜索
在 “数据模型-对象-设置” 中,可以把一个对象的部分类型的字段设置为 “可搜索字段”。
比如很多应用包都在 “用户” 对象上新增了 People ID 字段表示工号,然后配置有大量的 “People ID 等于 X” 和 “People ID 属于 [A, B, C]” 这样的查询。按照之前说的存储模型,需要查找整个工作簿才能找到符合要求的所有记录,性能较差。但当我们添加到 “可搜索字段” 后,服务端会做一些优化以提高查询性能,这时性能可以比肩 ID 查询,非常棒。
250px|700px|reset
目前系统逻辑是:添加为可搜索字段后,会在数据库为这个字段创建索引,并且还会将这个字段值接入 ElasticSearch 搜索服务,等值/比较运算符会利用索引,模糊搜索会利用 ES 搜索。
优先使用系统字段
系统字段上的查询效率一般比自定义的字段的查询效率高。这里主要指三个:
- ID: 不用多说,这是查询效率最高的字段了
- 创建时间、更新时间:这两个时间比我们自定义的时间类型查询效率要高很多
比方说有一个 “订单” 对象,在它上面有一个 “下单日期” 的字段表示哪天下单的。其实这个字段值就是记录创建的日期。那么在用作查询条件或排序条件时,这个字段可以换成系统字段 “创建时间”,查询效率就会更高。
系统默认为 ID、创建时间、更新时间这三个字段创建索引。
使用沙箱多环境配置减少关联查询
沙箱中的数据和线上环境的数据是隔离的,所以当我们要引用具体记录时,其实引用到的是不同的记录。比如我们搭建了一个页面,展示部门 UX-1-1 的员工,如果直接配置 “用户.部门 = UX-1-1” 你会发现在沙箱中无法运行,因为默认配置引用的是线上环境的记录,沙箱中是找不到的。
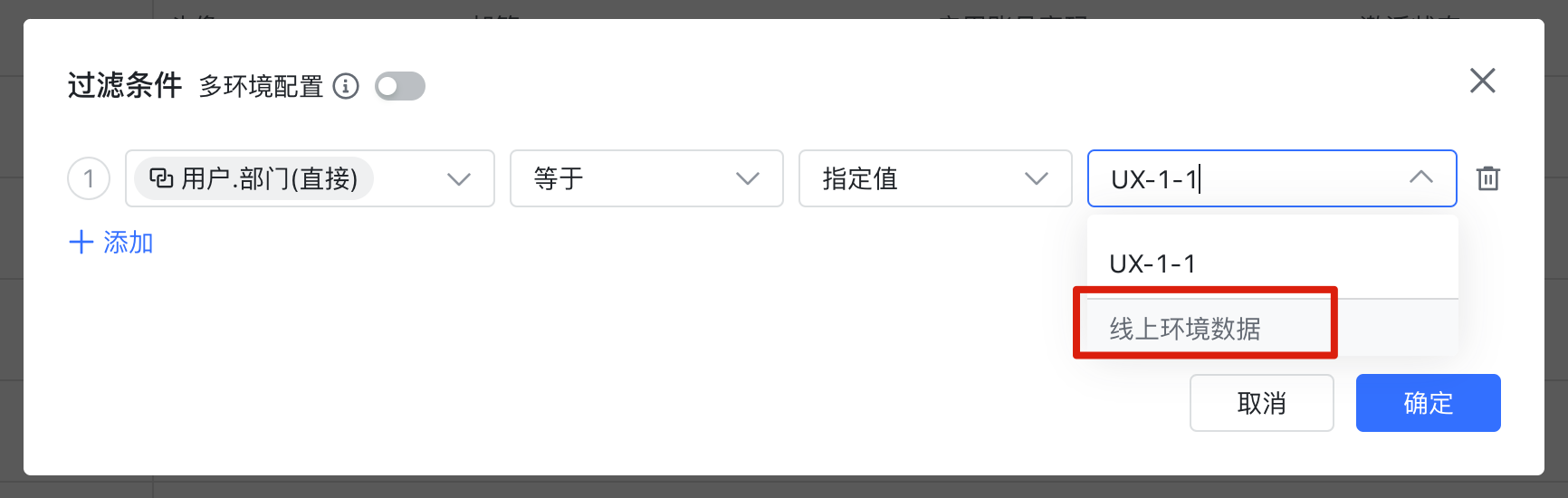
250px|700px|reset
这时你可能想到,配置 “用户.部门.名称 = UX-1-1” 就好了嘛,部门名称是一个文本,不需要引用记录。
只要你能保证没有重名的部门,这个方案确实可以。但最佳解决方案是打开 “多环境配置”:
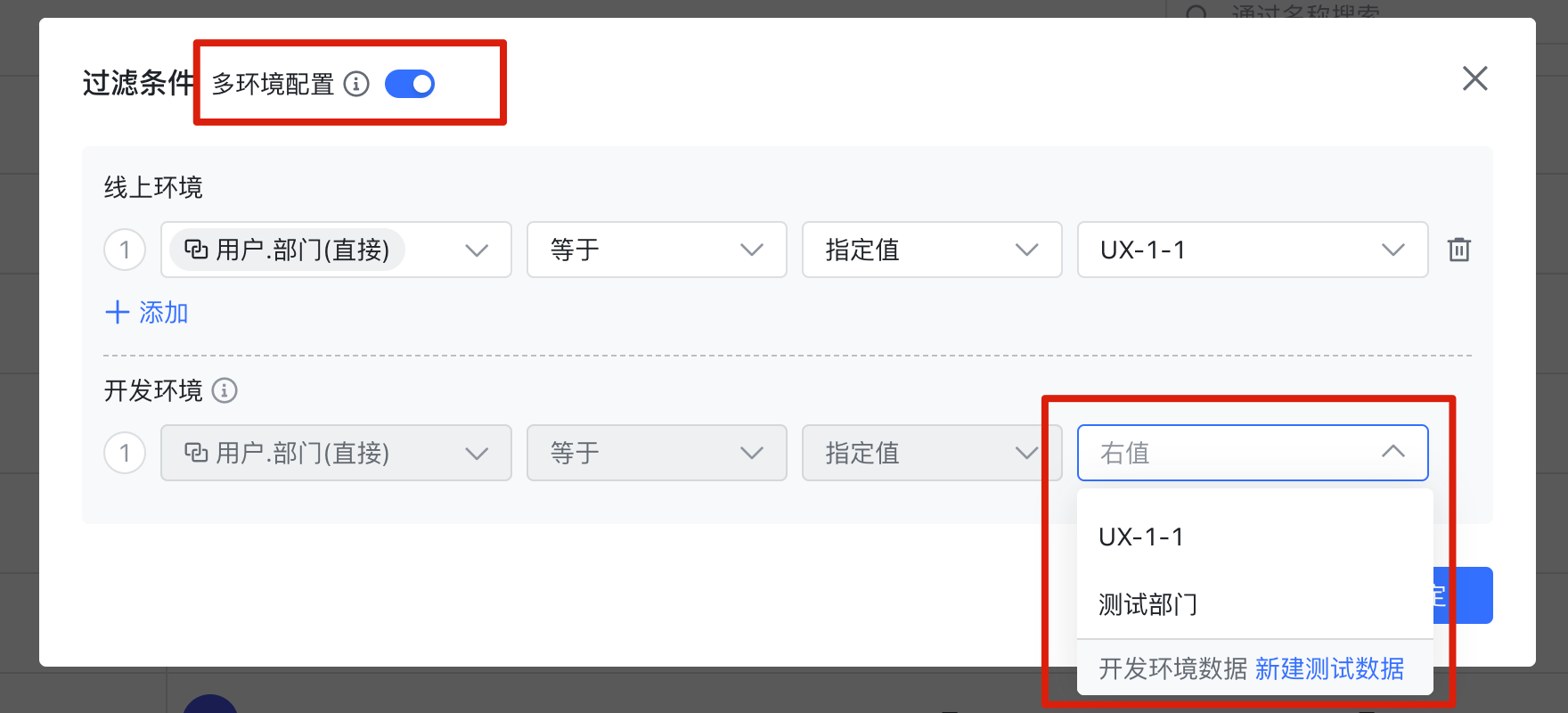
250px|700px|reset
这样一来,在沙箱中引用的就是沙箱中的记录了。不仅更准确 (避免了重名问题),而且效率更高 (减少了一次下钻)。
使用公式字段减少关联查询
公式字段不是实时计算的,而是提前算好、储存下来,有需要的时候再更新的。
除非你用到了 NOW() 这样的函数,包含这种函数的公式字段只能实时计算。
不过这一段文字涉及的场景就是简单的下钻字段,不包含任何奇怪的函数。
也就是说,公式字段会在工作簿中占用一列,储存公式计算的结果。
也就是说,公式字段使得我们有机会把其他工作簿中的列储存到当前工作簿中。
比如配置查询 “用户.部门.名称 等于 X”,这个查询条件有一次关联 —— 涉及两张工作簿的查询。我们可以在用户对象上新增公式类型的字段,并配置公式的值为 “部门.名称”,如图:
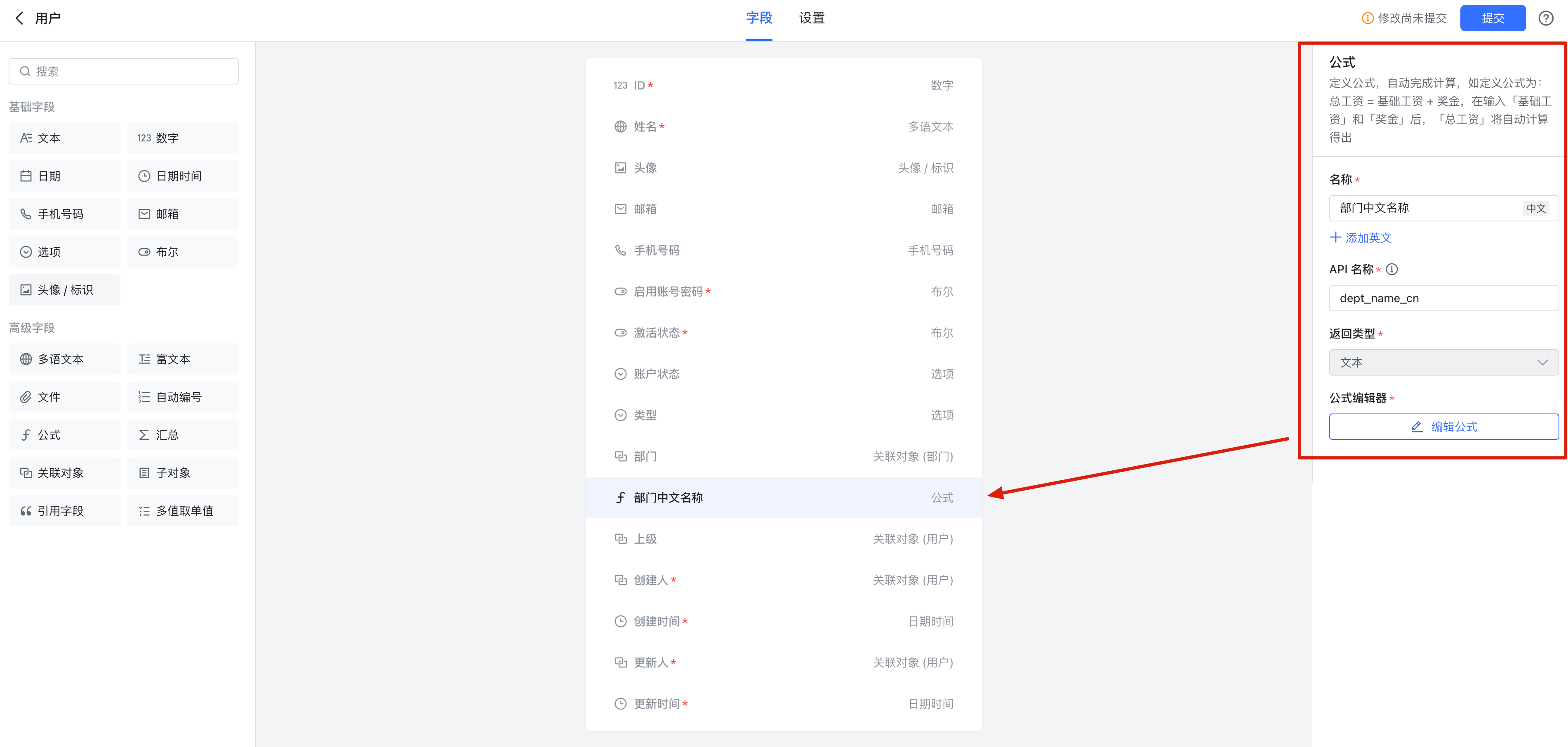
250px|700px|reset
250px|700px|reset
这样处理之后,部门名称就被存入到用户的工作簿了,我们直接配置 “用户.部门名称 等于 X”,这个查询条件就不涉及关联了。
公式字段是有效减少关联查询关联次数的手段。
但是这么做有前提:能接受公式值的更新延迟,并且公式中涉及的字段不能频繁更新。
上图的配置,当用户的部门发生变化,或者用户的部门的名称发生变化时,“部门名称” 这个公式字段的值也会随之变化。但这个变化不是实时的,会有百毫秒到秒级的延迟。所以如果公式结果会频繁更新,这也会导致查询结果不稳定。
建议:部门、部门名称这种几乎不会变,或者说变化频率低于一周一次的值,可以考虑用公式字段减少关联次数。
另外注意,如果一个对象已经有了很多记录,新建公式字段时,需要等待较长的时间才能计算完成。
公式值的更新是异步的,通过消息队列实现的。
避免同一个页面有多角色的数据权限
一个用户可能拥有多个角色,这没问题。我们需要避免的是同一个页面有多个角色可以查看,尽量做到每个页面都有一个专门的角色有权限查看。
如果说同一个页面有多个角色有权限查看,同时每个角色又配置了权限数据范围(指对象记录范围中的按规则指定范围),如下图:

250px|700px|reset
这时一个拥有多角色的用户访问这样的页面时,多个角色的权限数据范围是 OR 关系,落到查询上就会比较吃性能。
所以,在碰到这种情况导致的慢查询时,我们可以对页面进行拆分,或者干脆复制几个页面出来,单独配置给不同的角色,以减少拥有同一个页面查看权限的角色的数量。
尽量使 FILTER 函数匹配记录数少
道理很简单嘛,FILTER 函数匹配的记录数少,意味着我们到另一张工作簿查出来的记录少,那么我们拿着这些记录,也就更容易在当前工作簿查询了。如果说在另一张工作簿查出来几万行,你是不是会非常头大?如果只有几行,那就很简单了嘛。
建议 FILTER 函数匹配记录数不要超过一千。
FILTER 一定会被翻译成子查询。如果我们判断出这个子查询的结果集较小,就会拆分出去单独执行。相当于把一条复杂的大 SQL 拆成了多条简单的小 SQL 以提高查询性能。
Low Code 和 OpenAPI 优化方式
使用 ID 游标分页拉取全量数据
在外部系统通过 OpenAPI 拉取数据时,由于限制了一次 HTTP 请求最多获取 200 条记录,所以在符合条件的记录数较多时,需要多次请求来分批获取。
大家可能最自然想到的就是每次把 offset 参数增加 200,直到某次调用返回数量不足 200. 但回顾前面说过的 “末尾页”,这种 OFFSET 分页方式性能非常差。假如工作簿有 1000 行,那么第一次访问会查找 1 ~ 200 行,第二次访问会查找 1 ~ 400 行 (然后舍弃前 200 行得到 offset = 200 的记录),第三次访问会查找 1 ~ 600 行,第四次访问会查找 1 ~ 800 行,第五次访问会查找 1 ~ 1000 行,即我们实际上一共查找过 3000 行。
当工作簿有 N 行时,我们需要查找 N*N/400 + N/2 条记录。是 N 的平方级别的复杂度。这是很恐怖的,当 N 为 10 万时,一共需要查找过两千多万条记录。
应该使用 ID 游标分页拉取全量数据,而非 OFFSET 分页。
使用 ID 游标分页拉取数据时,有 N 条数据我们就只会查找 N 次,一次多余的都没有。因为 ID 游标分页是按照 ID 顺序,每次拉取 200 个,通过 ID > minID 条件,我们可以直接在工作簿中找到 minID 的位置,然后查找 200 个,下一次调用时更新 minID 即可。
伪代码示例如下所示。
❌ OFFSET 分页:
let offset = 0;let limit = 200;let result = []while (true) { let resp = query(offset, limit); // 按照 offset, limit 查询数据 result.extand(resp); if (resp.length < limit) { break; } offset += limit;}}
✅ ID 游标分页:
let minID = 0;let limit = 200;let result = [];while (true) { let resp = query(limit, id > minID, order by id); // 查询 id > minID 的数据,并根据 id 排序 result.extand(resp); if (resp.length < limit) { break; } minID = resp[limit - 1].id}}
使用缓存减少 DB 调用次数
- 一次 ID 查询,耗时在 50~100ms
- 一次 Redis 访问,耗时在 10~30ms
- 一次本地 Map 访问,耗时在 1ms 以内
对于一些比较固定的记录的查询,我们可以用缓存减少 DB 调用次数,本地缓存、Redis 缓存都用上。
但前提是这个记录不能经常变,并且能够接受缓存导致的变更延迟,即数据更新了,但是通过缓存读到的还是旧值。
const cacheExpire = 600/** @type {Map<String,[any, Number]>} */ const cache = new Map()/** * @param {String} object * @param {String} uniqueField * @param {any} value * @param {Context} context * @param {Logger} logger * @returns {any} */async function getRecordByUniqueFieldWithCache(object, uniqueField, value, context, logger) { const now = new Date().getTime() const key = `${object}_${uniqueField}_${value}` // read local cache if (cache.has(key)) { let resp = cache.get(key) if (now < resp[1]) { return resp[0] } } // read redis let redisResp = await kunlun.redis.get(key) if (typeof redisResp === 'string' && redisResp.length > 0) { let resp = JSON.parse(redisResp) // write local cache cache.set(key, [resp, now + cacheExpire * 1000]) logger.info(`getRecordByUniqueFieldWithCache got from redis, cost: ${new Date().getTime() - now}ms`) return resp } // read db let dbResp = await context.db.object(object).where({ [uniqueField]: value }).findOne() // write cache cache.set(key, [redisResp, now + cacheExpire * 1000]) await kunlun.redis.set(key, JSON.stringify(dbResp)) await kunlun.redis.expire(key, cacheExpire) logger.info(`getRecordByUniqueFieldWithCache got from db, cost: ${new Date().getTime() - now}ms`) return dbResp}}
合并查询条件 & 避免循环拼接 OR 条件
避免使用 _id eq 1 OR _id eq 2 OR _id eq 3 这样的查询条件,可以合并成 _id in (1, 2, 3)
不要在 Low Code 或 Open API 中使用 OR 循环拼接查询条件,这不仅导致查询性能低,也有可能直接被拦截,因为查询条件过于复杂。
按需 select
在 Low Code 中调用 context.db.object().find() 时,尽量传入 select() 参数。
不传则表示查询全部字段值,这不仅导致网络传输的开销变大,还可能会导致底层有额外的查询。因为有一些高级字段比较复杂,无法和其他基础字段一起存储在同一张工作簿中,所以查询这些高级字段的值需要额外地查询其他的工作簿。