很多自媒体人、企业内容团队都需要紧跟热点或时事。热点跟得上,内容才更容易被看见;热点判断慢了,选题就容易变成“别人已经写过的新闻”。
但追热点这件事,过去很大程度上只能靠人肉搜查:每天打开官网、社媒、媒体、社区、榜单和各种群聊,一条条翻,一条条判断。费时费力不说,还很容易漏掉真正有价值的线索。
AI 可以帮忙抓取和总结信息,但它不能自动消除信源复杂度。以 AI 行业热点为例,同一件事可能同时出现在企业官网、官方 X、媒体报道、社区讨论和开发者测评里。官网发了 release note,官方账号转述一次,媒体写成新闻,社区又开始讨论迁移、接入和体验问题。看起来每条都重要,但继续往下查才会发现,有些只是同一事件的不同版本,有些是二次传播,有些热度很高但事实来源并不稳。
如果没有一个稳定的承接层,热点追踪最后很容易变成:
最近,飞书增长团队把这件事做成了一套可持续运行的内容选题工作流:Agent 负责扩大信息面,飞书 CLI 负责把结构化结果写入飞书,多维表格负责承接证据、状态、视图和人工判断,飞书aily 则可以基于这些历史记录继续辅助选题判断和内容生成。
这个实践很有启发,所以我们把它整理出来分享给更多飞书用户。如果你的团队也需要长期追热点、定选题、沉淀判断,可以参考这套做法。
一、系统架构:Agent 抓信息,飞书承接数据与协作
在这套工作流里,Agent 和飞书的分工很清楚。
这套流程的核心承接点是多维表格。它既不是本地 JSON 的替代品,也不是一个单纯展示数据的页面,而是自动化采集和人工判断之间的工作台。
二、如何搭建完整的热点抓取及选题系统?
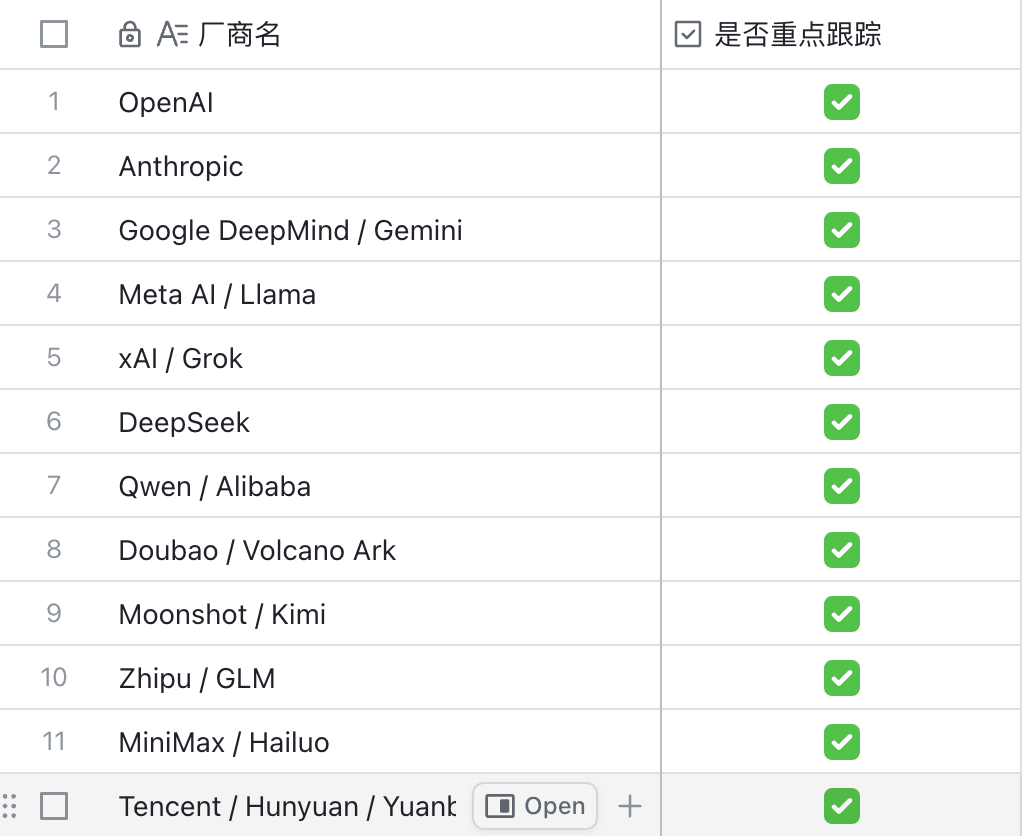
第一步:先把信源分层,不要直接追热词
很多热点抓取系统失败,不是因为抓得太少,而是因为一开始就把“热度”当成了“事实”。
更稳的做法,是先把信源分层。不同信源回答不同问题:
这样做的好处是,系统不会因为某个关键词热度高就直接把它推成选题。
官方源回答“这件事到底有没有发生”;社区和媒体回答“大家为什么关心”;内容团队最终要判断的是“这件事能不能自然转成自己的内容方向”。
250px|700px|reset
250px|700px|reset
第二步:把链接变成可判断事件
热点追踪最容易出现的噪声,是同一事件重复进入系统。
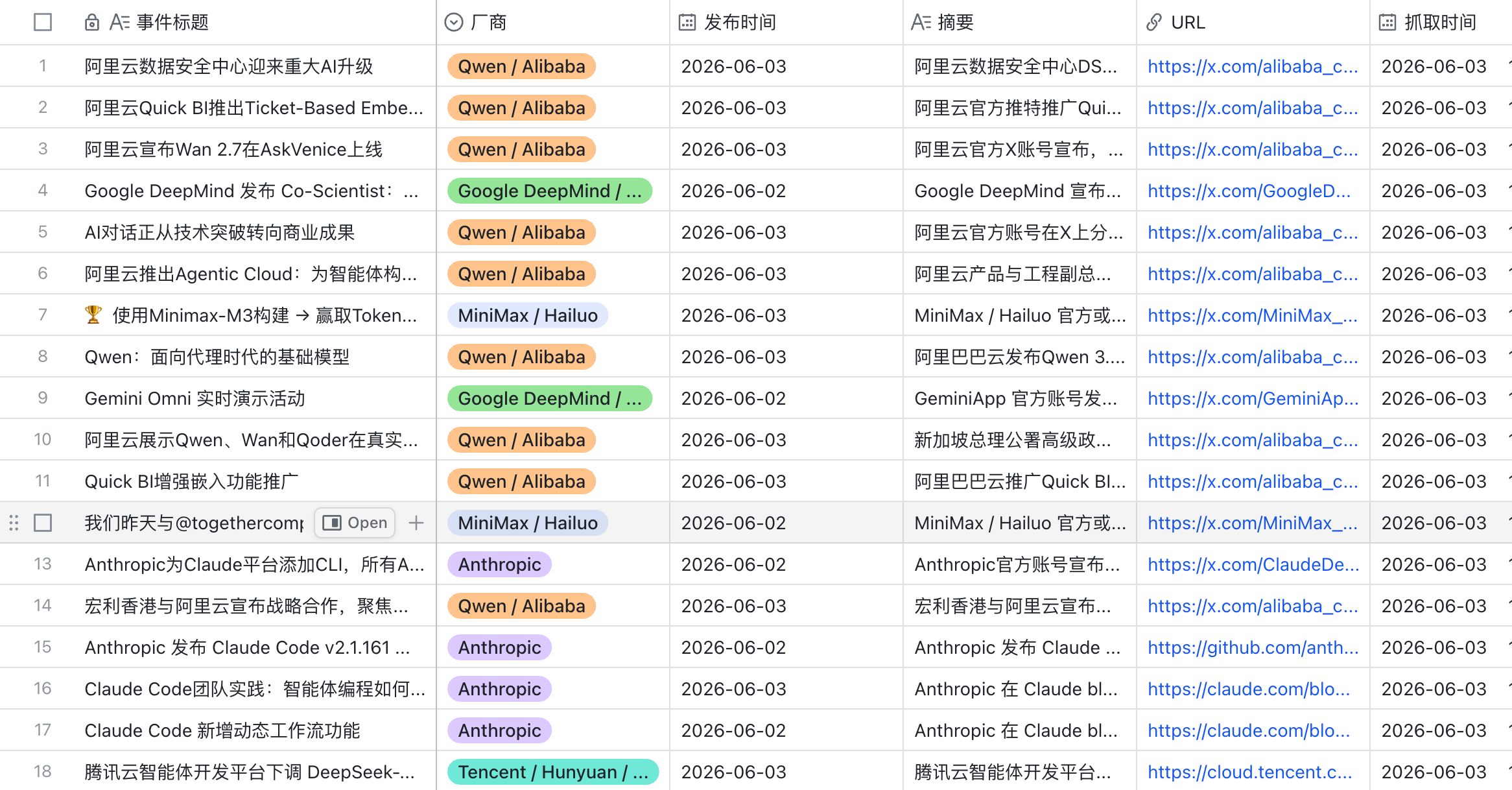
比如一个AI模型的更新资讯,可能会同时出现在官方博客、官方 X、媒体报道和开发者社区里。如果系统只保存链接,最后会得到四五条看似不同的线索;但对内容判断来说,它们可能只是同一个事件的不同证据。
因此,这套系统把信息分成三层:
数据层 | 保存什么 | 作用 |
原始信号 | 标题、URL、发布时间、来源层级、厂商、摘要、抓取时间 | 保证每条线索都能回查 |
更新事件 | 同一事件的多条线索、主 URL、合并来源、来源数量 | 避免重复热点进入判断池 |
热点候选 | 事件强度、讨论势能、摘要、选题上下文 | 让机器先整理可判断对象,再交给人复核 |
这里的关键判断是:Agent 不直接替人下结论,而是先把信息流整理成“可判断事件”。
这比“抓到一堆链接”更有用。因为内容团队真正需要的不是更多入口,而是能判断每条候选是否可信、该不该跟进、下一步怎么处理。
第三步:用飞书多维表格承接复核、筛选和协作
当 Agent 把信息整理成结构化候选后,还需要一个地方承接后续动作。
Excel 或本地表格适合临时整理,但字段容易漂移,自动写入、关联、去重和复盘都不稳定。数据库适合存储,但对内容团队来说,查看、筛选、补充判断和分享给别人看都需要额外界面。
飞书多维表格刚好处在中间:它能承接结构化字段,也能像普通表格一样直接打开、筛选、补充判断,还能通过视图、权限、评论和卡片预览进入团队协作。
这套系统里,多维表格主要承接五类表:
表 | 定位 |
信源表 | 管理抓什么、怎么抓、信源是否健康。 |
原始信号表 | 保存每条抓到的证据,保留 URL、来源层级和复核状态。 |
更新事件表 | 聚合同一事件,形成热点候选主表。 |
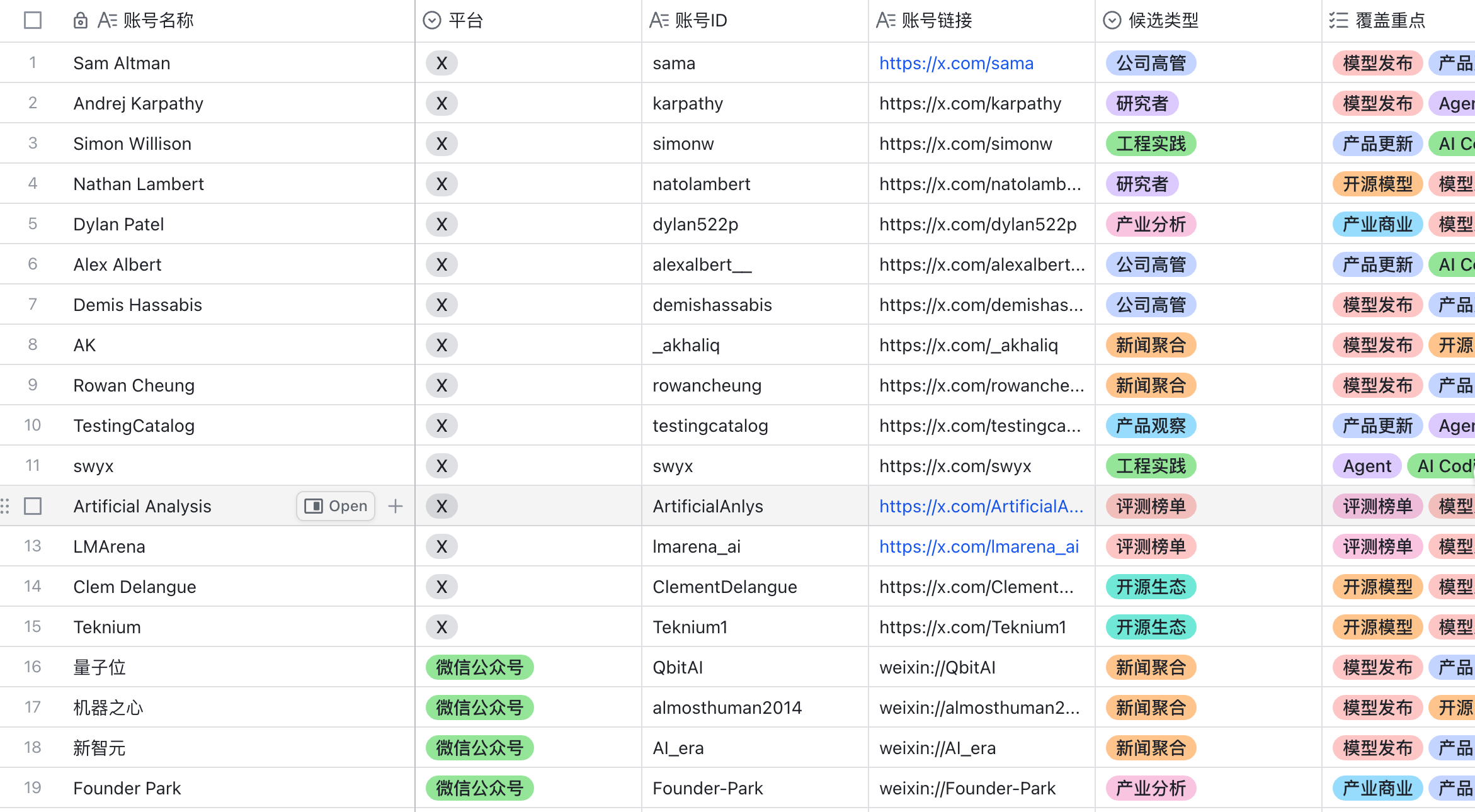
KOL 候选评估表 | 管理外部补充源准入,区分内容机会与官方事实。 |
抓取运行表 | 记录每轮抓取状态、失败原因和健康结论。 |
在这个结构下,用户可以在多维表格里回答几个关键问题:
判断问题 | 多维表格如何承接 |
这件事发生了吗 | 看主 URL、关联新闻 URL、来源层级、摘要 |
是否重复出现 | 看合并来源、来源数量、关联原始信号 |
外部是否在讨论 | 看外部讨论方向、热度分 |
和自己的产品或业务有什么关系 | 看产品/业务相关性分、关联强度、选题上下文摘要 |
这件事能写成什么 | 看选题方向和选题判断 |
250px|700px|reset
第四步:把重点候选推到群里,让团队先看到
如果所有判断都停留在表格里,团队成员仍然需要主动打开表格查看。
所以这套系统还可以把每日重点候选生成卡片,推送到选题群里。卡片不替代多维表格里的完整证据链,只负责把最需要被看到的候选先推到人面前。
一张卡片里可以包含:
- 热点标题
- 厂商或产品对象
- 核心摘要
- 推荐理由
- 证据状态
- 多维表格记录链接
这样,团队可以先在 IM 里快速浏览,再回到多维表格里做复核、补充判断和选题讨论。
如果多维表格已经基于数据表生成了仪表盘,也可以在聊天框以卡片形式预览,让团队先看趋势或重点候选,再进入具体数据表查看证据。

250px|700px|reset
第五步:让飞书aily 基于历史选题记录继续辅助判断
热点追踪系统最终服务的不是“自动抓到更多新闻”,而是让写作者更稳定地产生可写、可复盘、可迭代的内容选题。
在这套工作流里,多维表格沉淀的是一套可追溯的判断过程:历史事件、信源表现、选题结果和复盘记录都被保存在表里,飞书aily 这样的智能体,可以基于这些记录继续辅助判断:
这一步不能理解成让智能体“自动替人判断一切”。更准确地说,是让智能体站在已有字段和复盘标准上,帮助用户把判断过程做得更稳定。
当一条候选已经通过复核,飞书aily 可以继续生成标题、段落大纲、案例切入点和初稿。这样一来,内容生产不再是从零开始问 AI“今天写什么”,而是让 aily 站在一套已有选题记录和复盘标准上,帮助用户完成从热点判断到文章生成的下一步。

250px|700px|reset
三、一个热点从线索变成选题的完整案例
以一条「Anthropic 发布了团队成员认为HTML将取代Markdown」的热点为例,整个链路可以这样跑:
- Agent 从 Claude Blog 抓到更新,形成原始信号,保留标题、发布时间、厂商、来源层级和摘要。
- 系统发现社区里也出现相关讨论,例如开发者附和 HTML 更适合用于展示,但很多用户认为 HTML 比 Markdown 更消耗 token 。
- 系统把这些线索合并成同一事件,写入更新事件表。主 URL 优先选择官方源,外部讨论进入“外部讨论方向”。
- 运营在多维表格里看到这条候选:它有官方事实,有开发者讨论,也能落到我们自己的产品或内容工作流场景。
- 如果判断通过,飞书aily 可以基于已有字段继续生成标题、大纲或初稿。
这条热点最后被转成一个飞书能给出的答案:
这就是自动化抓取和内容判断结合的价值。
Agent 帮人把线索找出来,飞书多维表格帮团队把线索变成可讨论、可筛选、可复盘的选题资产。
四、这套系统适合迁移到哪些内容团队
这套方法不只适合 AI 行业热点,也适合所有需要长期监控外部信号、再转成内部选题判断的团队。
团队类型 | 可以监控什么 | 最终沉淀什么 |
AI 内容团队 | 模型发布、工具更新、开发者讨论、榜单变化 | AI 热点选题库 |
产品增长团队 | 竞品发布、用户反馈、社区讨论、渠道素材 | 增长机会库 |
行业研究团队 | 政策变化、公司动态、投融资、专家观点 | 研究线索库 |
客户案例团队 | 用户投稿、社群实践、业务案例、模板复用 | 案例素材库 |
共同点是:这些团队都不缺信息源,缺的是把信息源变成可复核判断的工作流。
结语:把热点追踪变成可复用的内容资产
回看这套用户实践,它真正解决的不是“怎样更快刷到 AI 新闻”,而是把热点追踪变成一套可以持续运行的内容工作流,持续管理事实、讨论、判断和选题结果。
Agent 负责扩大信息面,把分散在官网、官方账号、社区和媒体里的内容机会先抓回来;飞书 CLI 负责把结构化结果写入飞书;多维表格负责承接证据、来源、状态、视图和历史判断;飞书bot利用 IM 功能把重点候选推到团队面前;飞书aily则可以基于已经沉淀的选题记录继续辅助判断和写作。
这样一来,热点数据就不再是每天清空一次的信息流,而会逐渐变成团队的内容资产:可复核、可分享、可复盘,也能在下一次选题判断时继续发挥作用。
FAQ
1. AI 热点抓取为什么不能只看关键词热度?
因为关键词热度只能说明有人提到,不一定说明事件真实发生,也不一定说明它值得写。更稳的做法是先确认官方事实源,再看社区和媒体是否形成讨论,最后判断这件事能否自然转成内容方向。
2. 飞书多维表格适合做自动化数据采集的承接层吗?
适合承接轻量数据工作流,尤其是团队既要自动写入数据,又要人工复核、筛选、补充判断、分享给别人看时。它不替代数据库,但能把结构化数据变成可筛选、可复核、可协作的工作台。
3. Agent 抓取到的信息如何避免重复和误判?
系统需要保留 URL、外部 ID、厂商、标题、摘要、发布时间和来源层级,并通过 canonical URL、事件 key 和同事件合并规则降低重复。外部信号只能作为扩散和讨论证据,不能单独证明官方发布事实。
4. 飞书 CLI 在这套系统里起什么作用?
飞书 CLI 是外部 Agent 与飞书原生协作场景之间的桥。Agent 可以先完成抓取、清洗、合并和初筛,再通过 CLI 把结果写入多维表格、云文档、知识库、任务或 IM 等场景,让自动化结果进入团队日常工作流。
5. 飞书aily 在这里是不是替代人工选题?
不是。更合理的定位是辅助判断和生成。多维表格先沉淀事实来源、讨论方向、选题状态和复盘记录;飞书aily 再基于这些记录辅助判断选题价值、补充证据缺口、生成标题大纲或初稿。