

功能上新
计算公式字段编辑器全新升级!优化计算字段编写界面,提升公式编写体验。
功能点 | 新版 | 旧版 |
调整布局与样式,支持编辑器全屏放大 | 250px|700px|reset 250px|700px|reset | 250px|700px|reset |
公式输入支持原地搜索
| 250px|700px|reset 250px|700px|reset | 不支持 |
关联工作项可搜索,提升可读性 | 250px|700px|reset | 250px|700px|reset |
支持站外文本公式复制 | 公式:SUM(FILTER(${流程节点},each.${节点状态} == $option{已完成}).${节点估分}) 复制后: 250px|700px|reset | 不支持 |
支持公式格式美化 一键对公式结构进行换行和缩进 | 250px|700px|reset | 不支持 |
支持快捷键 | 上键、下键、左键、右键:移动光标 回车键:确认选择/换行 TAB 键:公式缩进 Ctrl+Z:取消上一步操作 | 不支持 |
介绍
度量场景复杂多变?飞书项目可自定义灵活敏捷的公式计算字段,应用于进度汇总、风险预警、资源投入计算等多种业务场景,直观查看关键指标。
功能入口
字段的添加需要管理员前往对应的工作项进行配置,具体路径为:空间配置 - 工作项管理 - 工作项(需求、缺陷等)- 字段管理 - 新建字段 - 其他 - 选择“公式计算”类型添加计算公式字段。
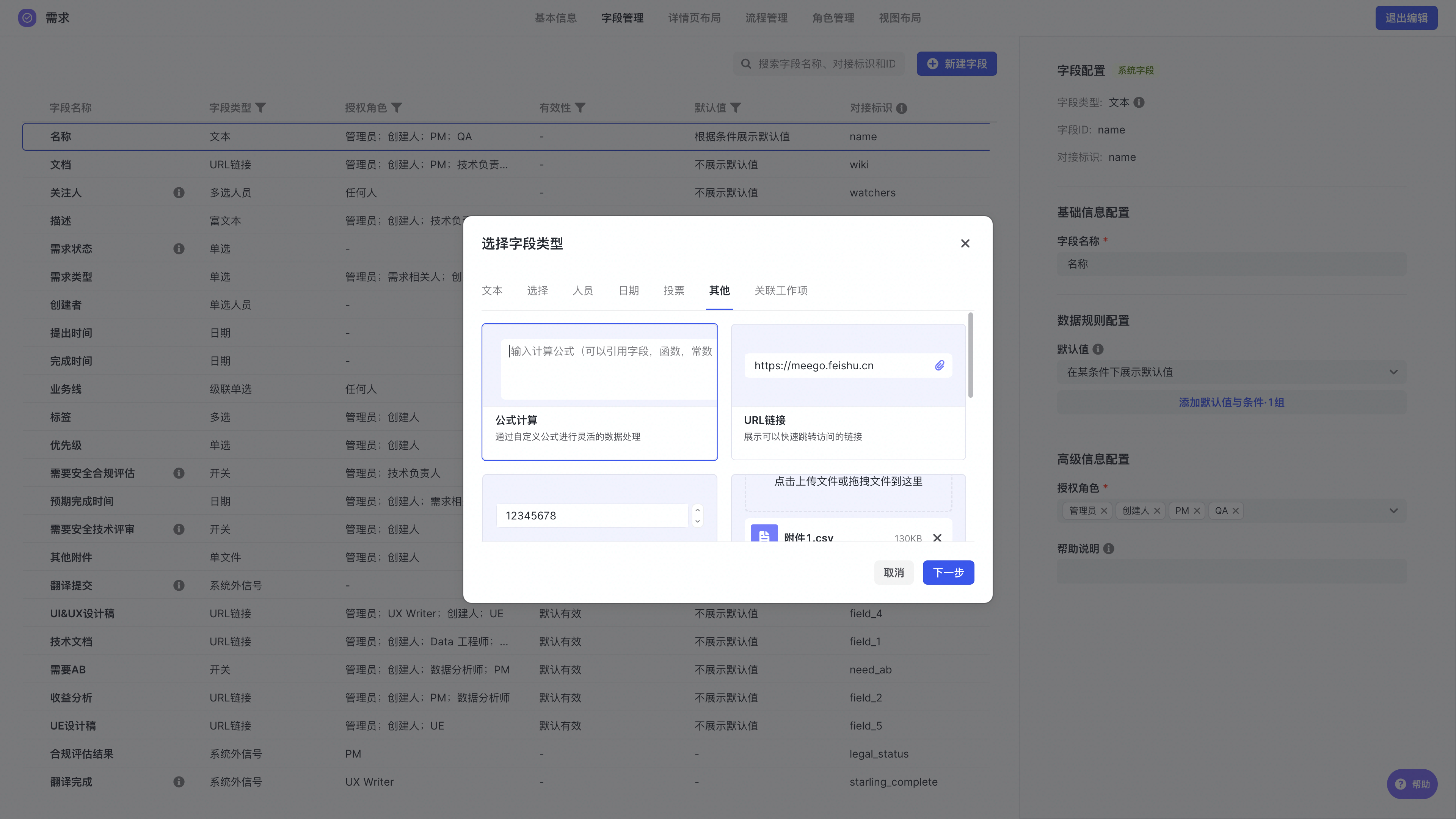
250px|700px|reset
学习准备
一个案例认识计算公式
在开始学习使用计算公式前,我们先来了解一个简单例子:如果我们要算一个周期,是不是首先应该有日期?这里我们假设计算距离今年春节还有多少天,也就是春节的日期减去今天的日期,再得到一个天数。简化公式为:
春节日期 - 今天日期 = 天数数数数数
那么在飞书项目计算公式中提供了一个叫 daysBetween() 的函数,来计算两个日期的天数间隔,上述公式可以这样写:
daysBetween(今天日期,春节日期) //等价春节日期 - 今天日期 = 天数数数数数
那再进一步,我们需要取得距离今年春节还有多少天工作日?人工数日期?但是有了计算公式,这个数的动作就变成了函数自动解析。
顺着上面思路,借助 workdaysBetween() 的函数,可以将两个日期中的工作日提取出来,得到“距离今年春节还有多少天工作日”的结果。
workdaysBetween(今天日期,春节日期) //等价春节日期 - 今天日期且去除非工作日的天数。。。。。
以此类推,我们要计算个数,用 COUNT()、求和用 SUM()、计算平均用 AVG()。具体使用参考函数部分,按照指定格式书写即可。
理解计算公式
再回到我们计算公式,逻辑和上述案例一致,首先要知道取什么数据,然后怎么处理这些数据,最后输出一个结果。比如直接取某个字段的值,提出时间、销售额字段。接着是怎么处理这些取得的数据,比如筛选上面取得的数据,用筛选后的数据来求和、求差、求数、求占比等等。
- 筛选:条件筛选数据,取属于某个节点的确认时间,获取某个需求的完成时间等;
- 求和:估分之和、金额之和、日期之和等;
- 求差:时间周期、人力之差等;
- 数量:需求数量、缺陷数量
- 平均:平均周期
- 占比:完成节点占比,完成缺陷占比
- 大小值:最大日期、最小日期
- 组合:两个字段值重新组合成一个新的字段
处理后的数据会输出一个值,这个值输出格式可以是数字、日期、字符串或者布尔值。最终根据我们字段配置展示在视图、详情页、节点表单上。
新建计算公式字段
添加计算字段
进入计算公式界面后,有三个区域:公式编辑区、字段与函数选择区、字段与函数示例区和输出结果设置区。
- 计算公式编辑区:书写计算公式的区域,可以使用类似count(filter({流程节点},each.{节点状态}=="进行中").{KEY})来表示进行中节点的数量。
- 字段函数选择区:选择如拉群方式、名称与业务线等字段,也可以选择如参与人员、流程节点、终止原因等对象数组;还可以手动选择计数count()、求和 sum() 等函数。
- 字段与函数示例区:在本区域内可以了解字段与函数的介绍与使用示例,方便快速上手使用。
- 计算结果显示区:根据字段输出的结果类型提示展示类型,一般有:字符串、数字、布尔、日期等。注意,字段类型一旦输出确认后,不能做变更,需要变更请重新新建一个公式计算字段。
全屏
支持点击【全屏】放大公式编辑区,点击【退出全屏】即可恢复至编辑框初始状态。
格式美化
支持一键美化格式,自动对公式结构进行换行和缩进,公式编写更具可读性和逻辑性。
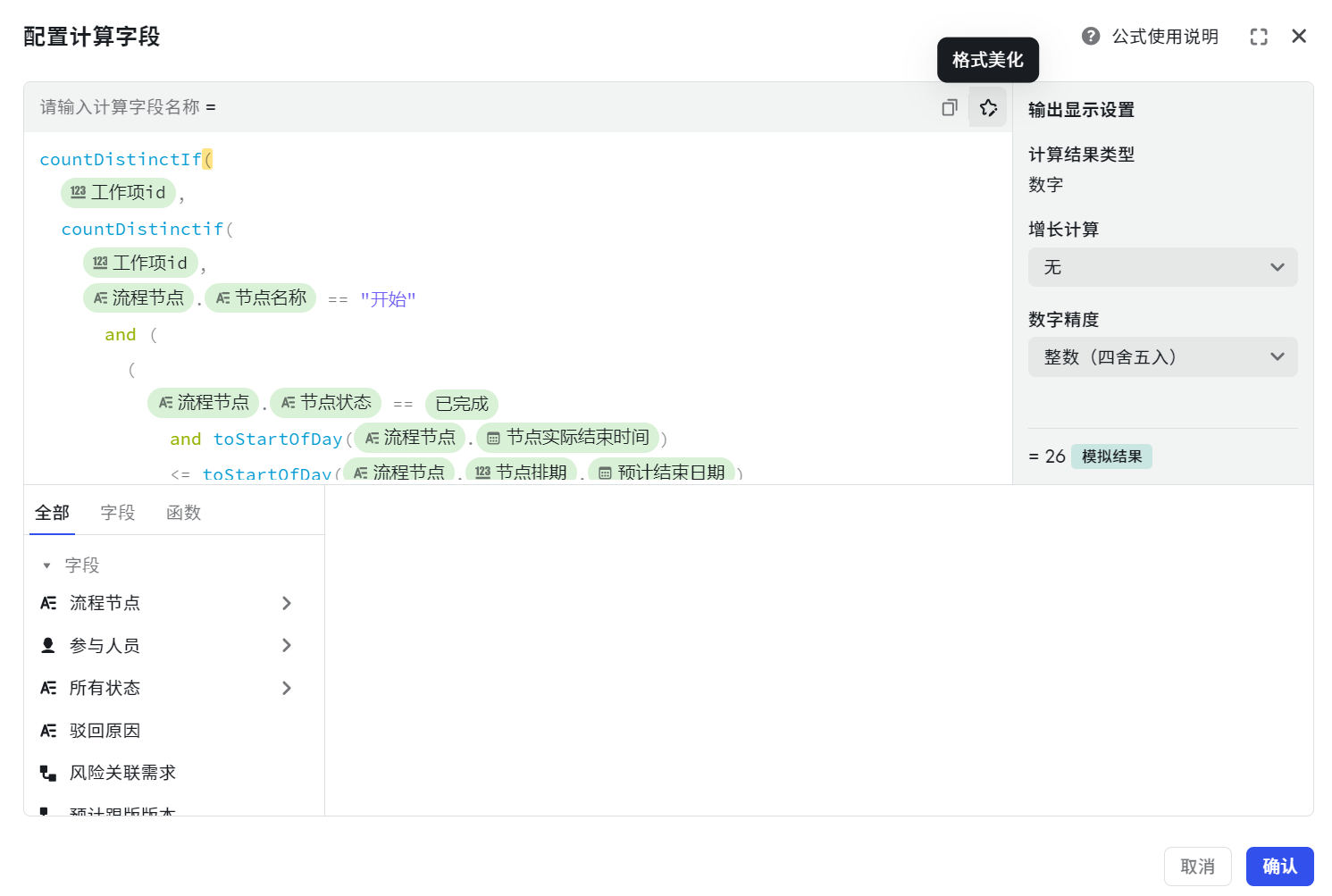
250px|700px|reset
复制公式
支持站外公式复制,即按格式要求带有前缀信息的公式,可从文档、聊天框等位置,复制到【度量-计算字段编辑区】并自动匹配相关字段。
- 使用范围:如仅在计算字段编辑器内编写公式,无需书写前缀。如需要将公式从编辑器复制到文档,系统会自动匹配相关前缀。如需要从文档将公式复制到计算字段编辑器,公式需带有相关前缀才能最大化的复制并匹配成功。
- 复制格式要求:为了更好的对公式进行匹配,不同的信息需要匹配不同的前缀符号,例如字段【优先级】前需增加$,最终效果为${优先级}。
数据结构
理解数据结构在计算公式中至关重要。数据结构本质对数据类型的分类,分类为数值、字符串、布尔、日期、数组以及对象类型。具体清单可以参考下方表格。
运算符
运算符与小时候学习数学一致,适用于数值类型的字段使用。而比较运算符适用于数字与日期之间的比较。
函数
函数可以理解为封装了运算能力的合集,每个函数都有特定的功能。比如 COUNT() 计算个数,SUM() 用来求和,string() 用来转换其他类型为字符串类型等等。
公式计算字段使用
添加至详情页
空间管理员前往对应工作项“详情页布局”选项中,点击左侧“字段管理”,拖拽相关公式字段至详情页。
添加至表格视图
公式字段也可以配置在表格视图上,方便快捷查看需求进度、关联缺陷数量等字段信息。鼠标移动至表格列中间,点击 +,选择对应计算字段即可。

250px|700px|reset
添加至列表视图
公式字段也可以配置在列表视图上,方便快捷查看关联事项的进度统计。
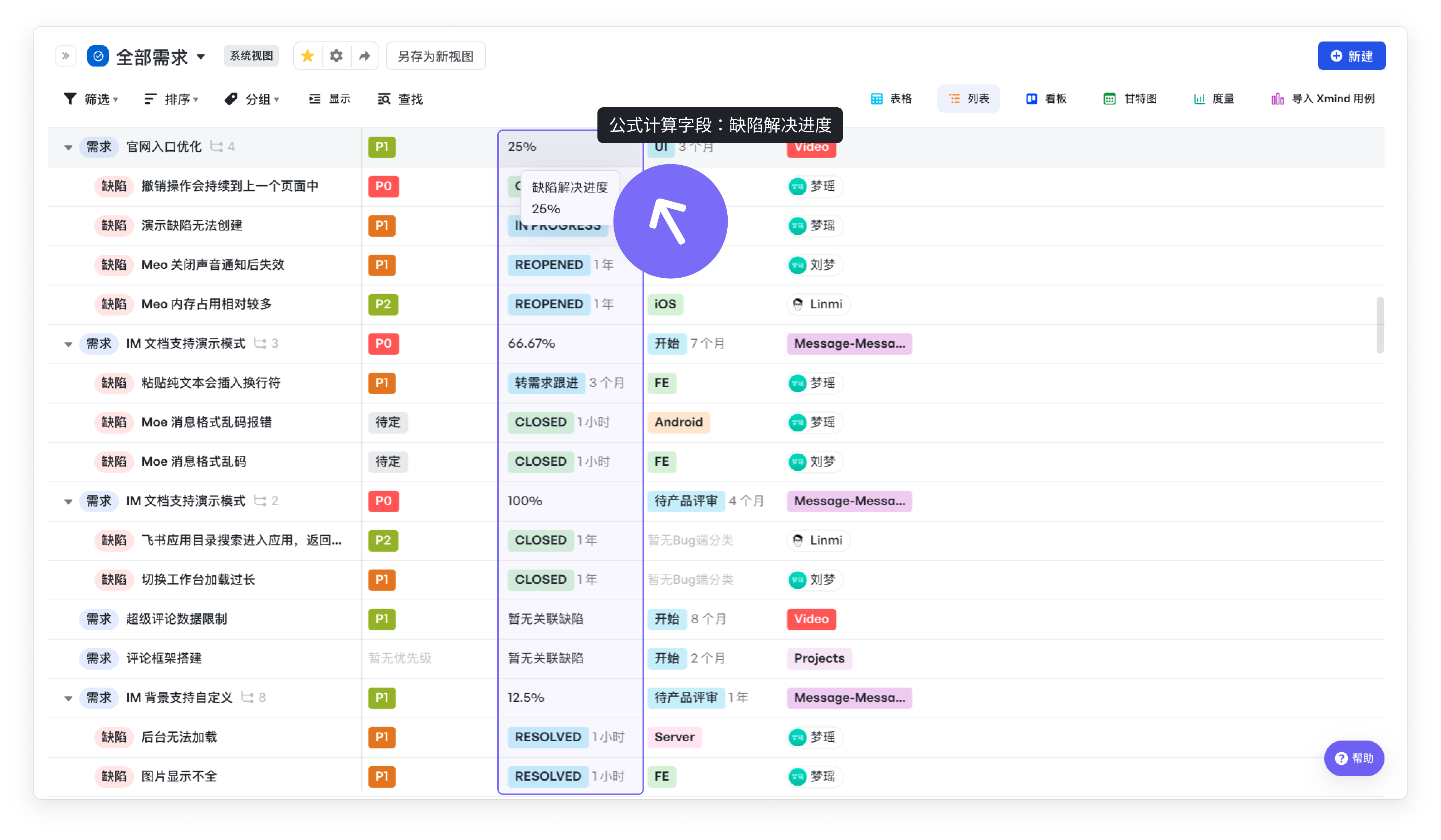
250px|700px|reset
添加至节点表单
参考信号流转部分。
添加至消息通知卡片
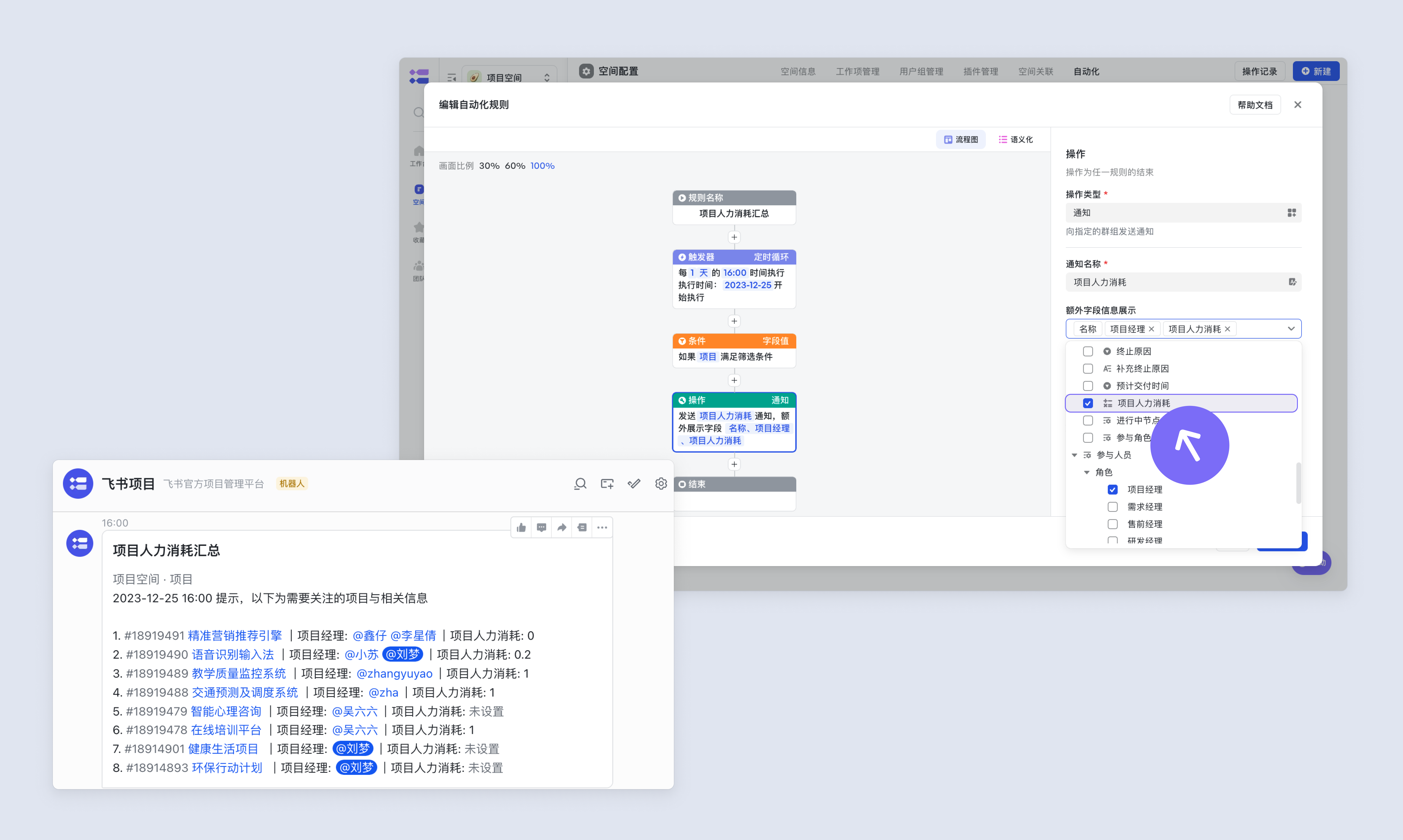
250px|700px|reset
计算字段参与度量
计算字段也可以参与实际度量,比如统计的金额计算。
场景案例
以下场景案例只针对公式的说明与解析,涉及字段如何新建使用请参考新建公式计算字段部分。注意计算公式仅供参考,实际字段因业务场景而异,但是整体逻辑不变。
数量计算
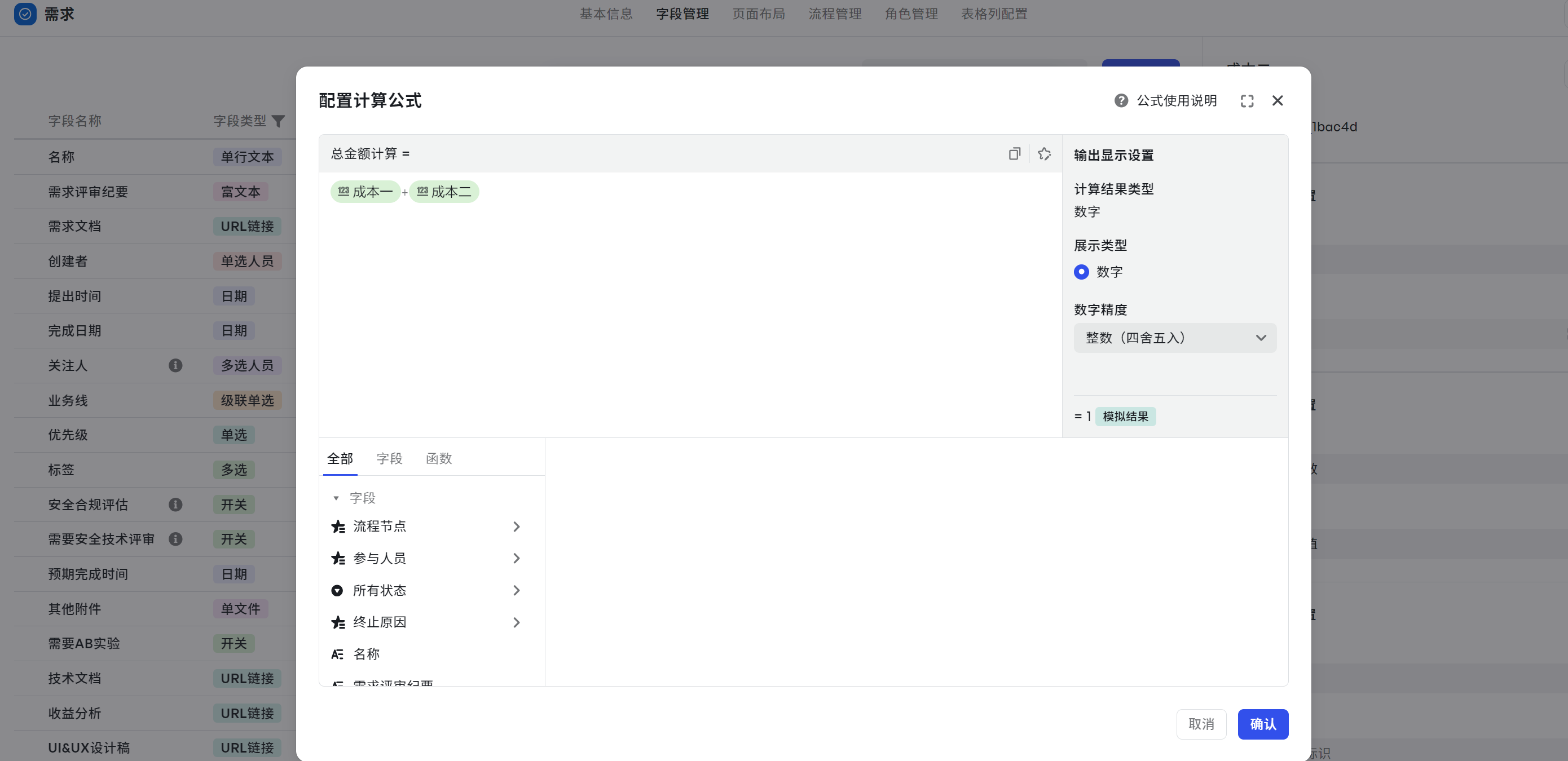
总金额计算
场景:计算两个金额字段的之和,将成本一字段与成本二进行相加,得到一个新的字段。
- 字段:成本一、成本二
- 运算符:+
- 计算公式:{成本一}+{成本二}
- 可复制公式:${成本一}+${成本二}
- 输出结果:总成本,为数字类型。
- 注意事项:支持最多两位小数展示以及负数之间相加。
250px|700px|reset
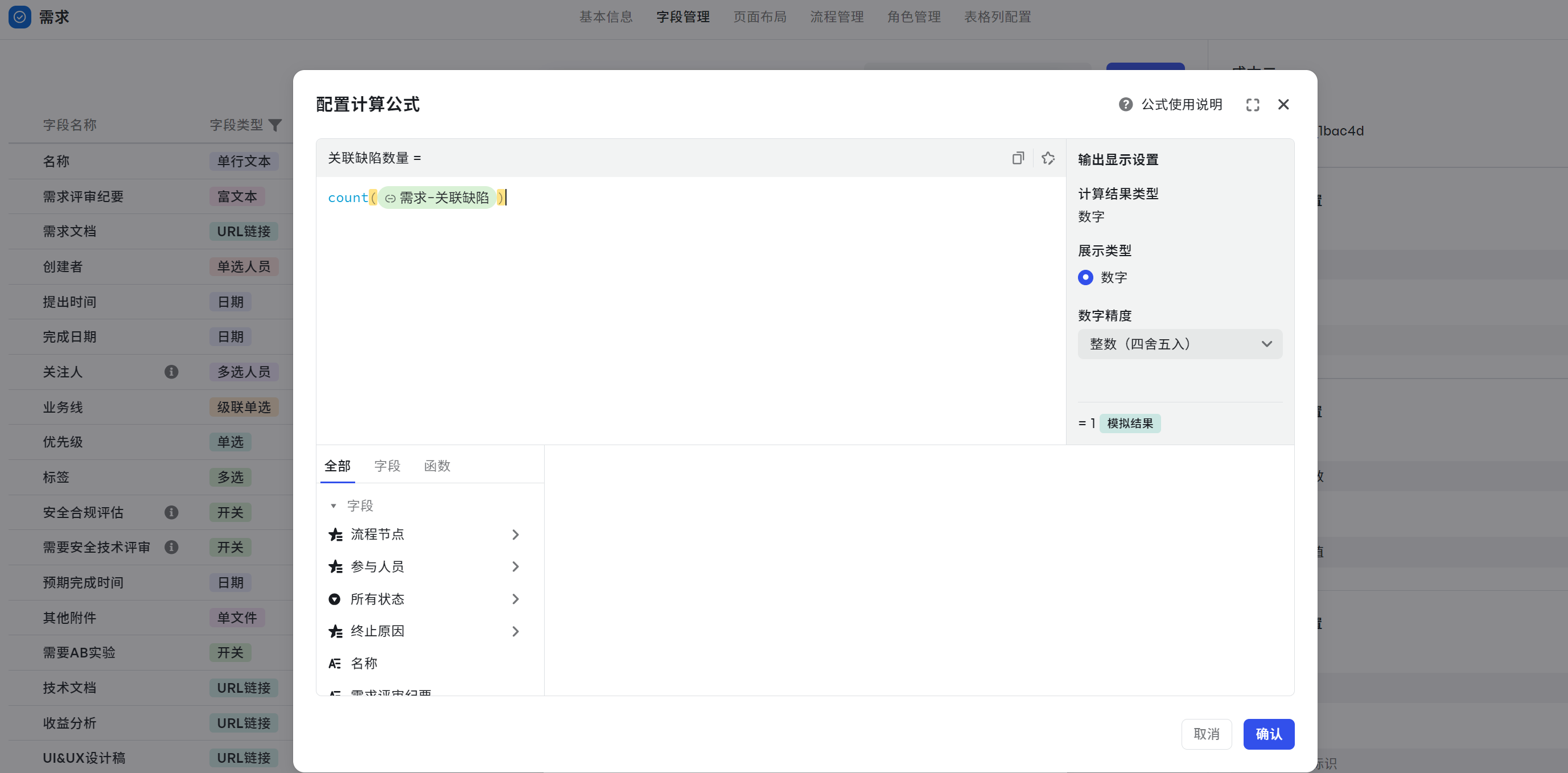
关联缺陷数量
场景:计算某个需求关联的缺陷,找到关联缺陷数量最多的需求,高优修复。
- 字段:关联缺陷数量
- 函数:count()
- 计算公式:count({需求-关联缺陷})
- 可复制公式:count($related{需求-关联缺陷})
- 输出结果:关联缺陷数量,为数字类型。
- 解析:使用 @ 获取关联工作项,通过 count() 计算,得出缺陷数据。
250px|700px|reset
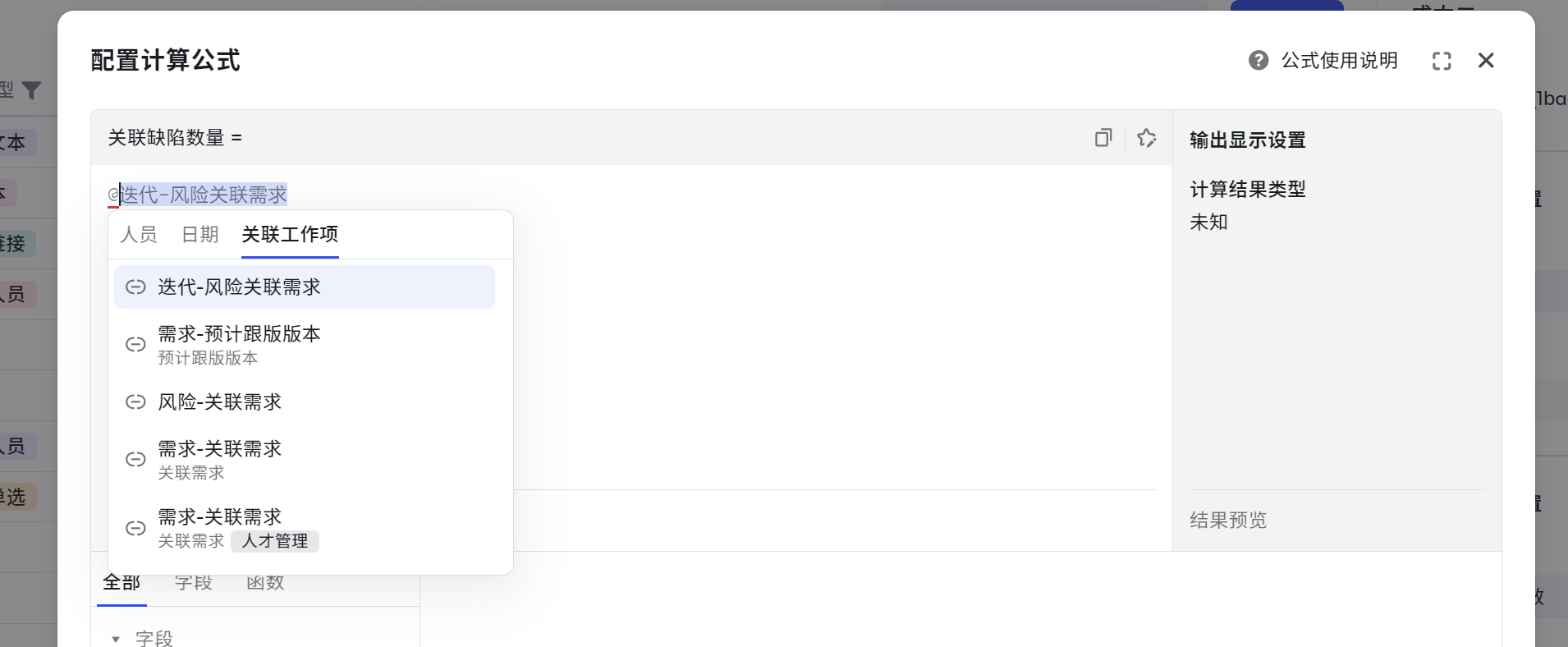
小技巧,@ 获取关联工作项数据。
250px|700px|reset
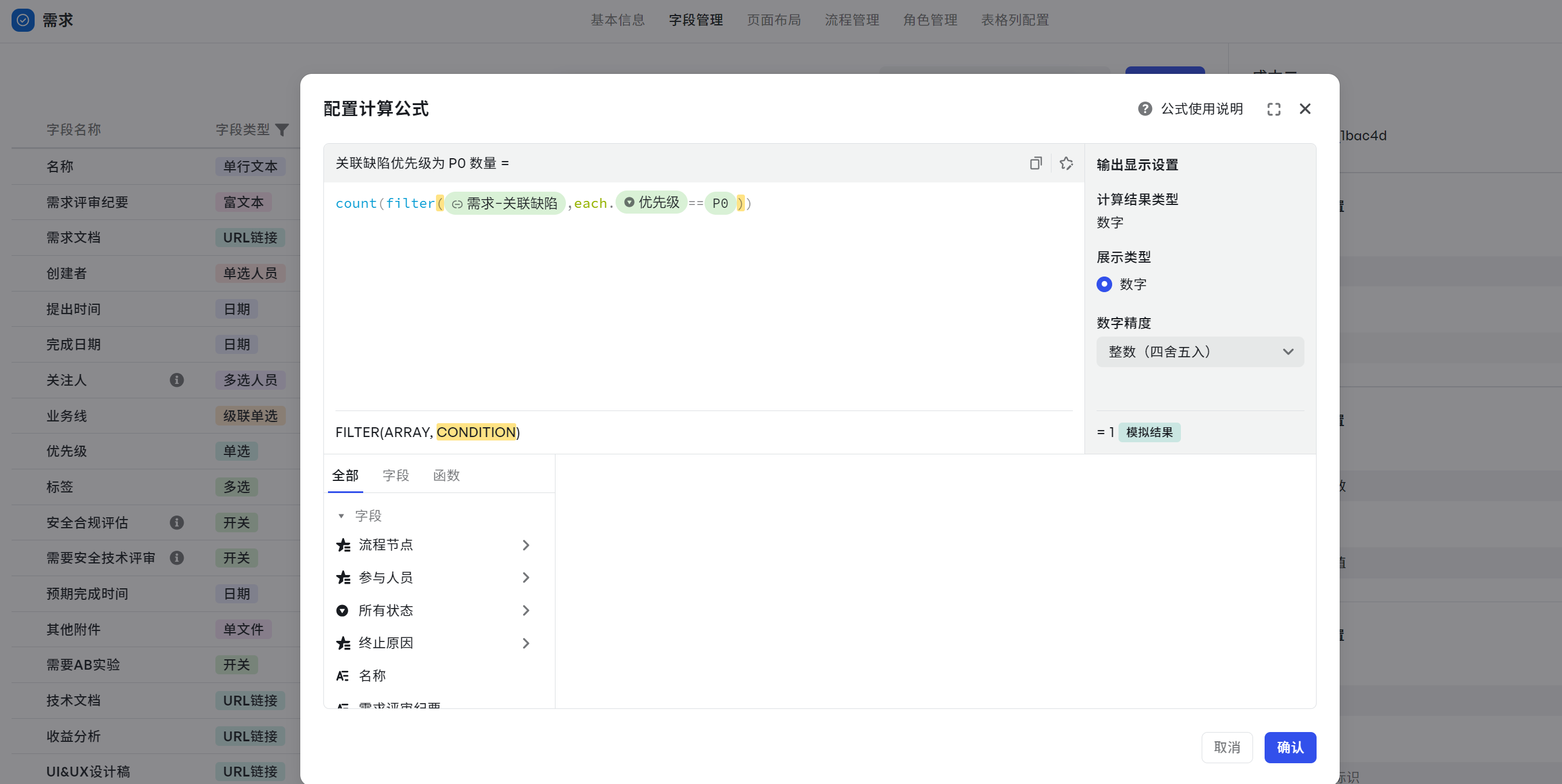
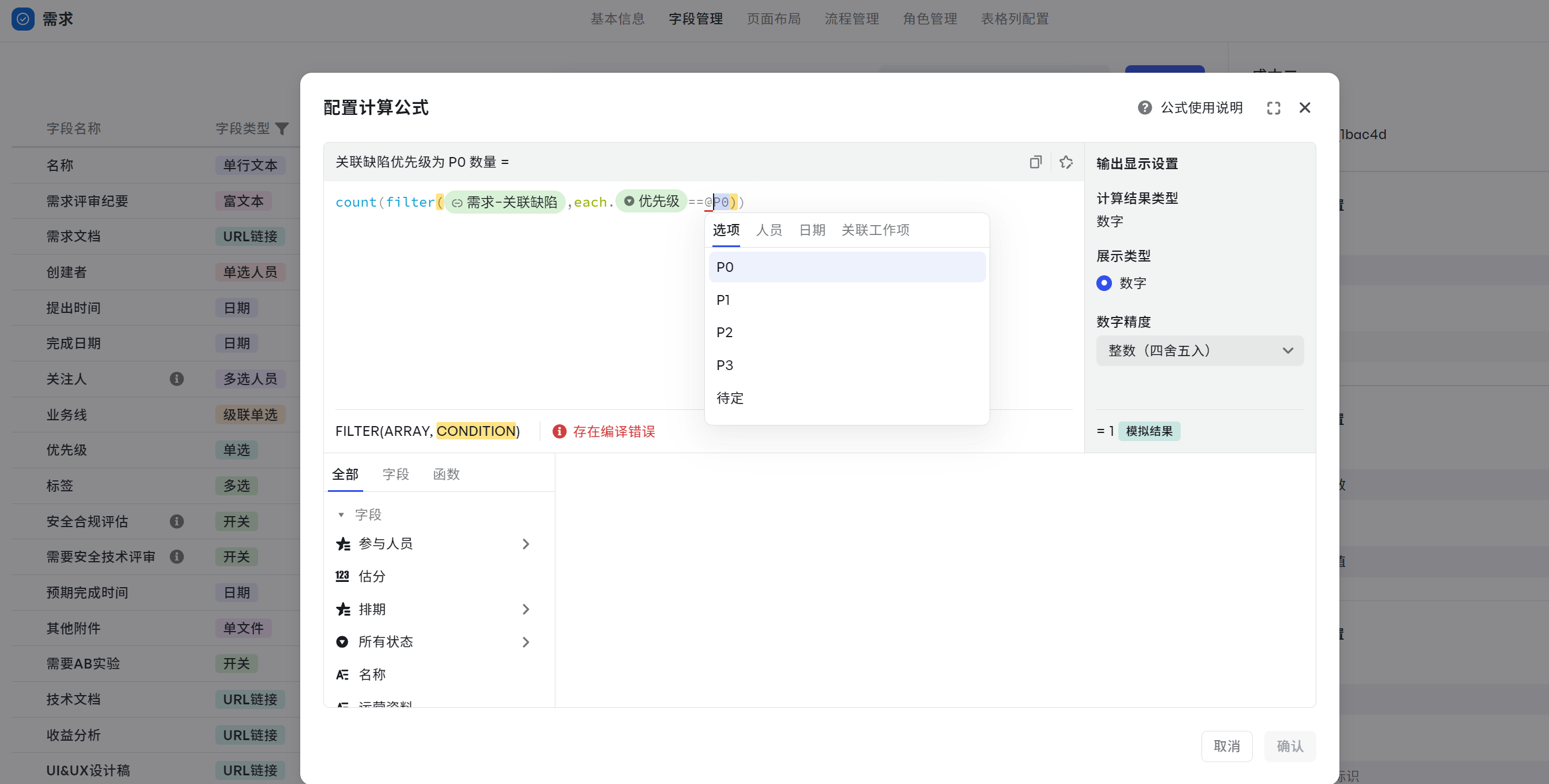
关联缺陷优先级为 P0 数量
场景:计算所有需求下,关联的缺陷且缺陷优先级为 P0 的数量最多的需求有哪些,高优修复。
- 字段:需求-关联缺陷,优先级
- 函数:filter()、count()
- 计算公式示例:count(filter({需求-关联缺陷},each.{优先级}==P0))
- 可复制公式:count(filter($related{需求-关联缺陷},each.${优先级}==$option{P0}))
- 输出结果:关联缺陷数量,为数字类型。
解析如下:
- filter() 找到优先级等于 P0 的关联缺陷:filter({需求-关联缺陷},each.{优先级}==P0)
- 然后通过 count() 计算,然后再得出缺陷数据:count(filter({需求-关联缺陷},each.{优先级}==P0))
250px|700px|reset
注意,可以通过 @ 获取选项值。
250px|700px|reset
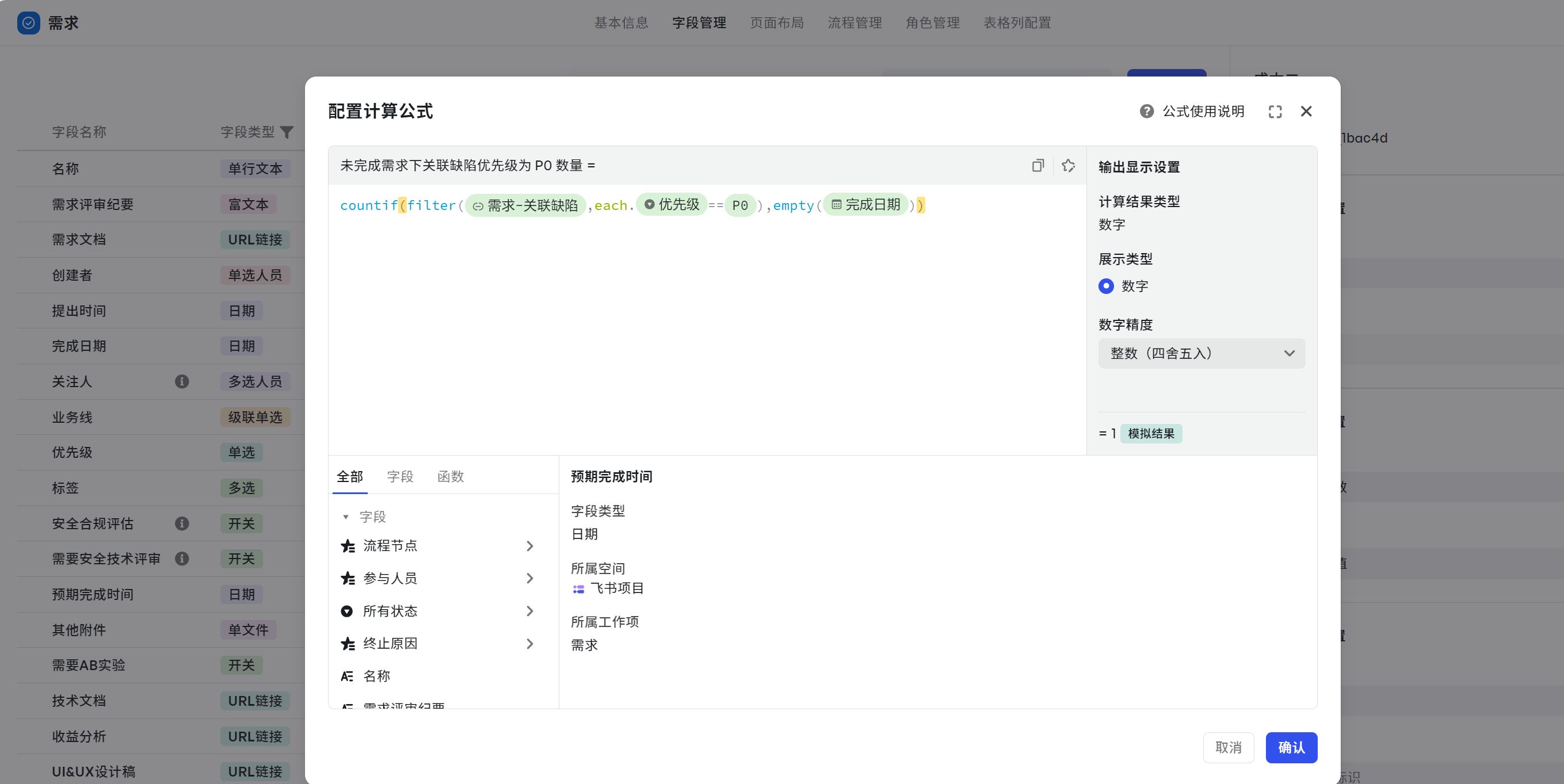
未完成需求下关联缺陷优先级为 P0 数量
场景:计算未完成需求下,关联的缺陷且缺陷优先级为 P0 的数量最多的需求有哪些,高优修复。
- 函数:filter()、countif()、empty()
- 计算公式:countif(filter({需求-关联缺陷},each.{优先级}==P0),empty({完成日期}))
- 可复制公式:countif(filter($related{需求-关联缺陷},each.${优先级}==$option{P0},empty(${完成日期}))
- 输出结果:关联缺陷数量,为数字类型。
解析如下:
- filter() 找到优先级等于 P0 的关联缺陷:filter({需求-关联缺陷},each.{优先级}==P0)
- 这里考虑到是未完成需求,需要判断“完成时间”为空,则为需求未完成,公式为: empty({完成日期})
- 接着通过 countif() 计算数量:countif(filter({需求-关联缺陷},each.{优先级}==P0),empty({完成日期}))
250px|700px|reset
注意,如果是希望判断完成,则公式需要修改为 empty(完成日期) == false,因为需求完成了,所以完成时间不为空。
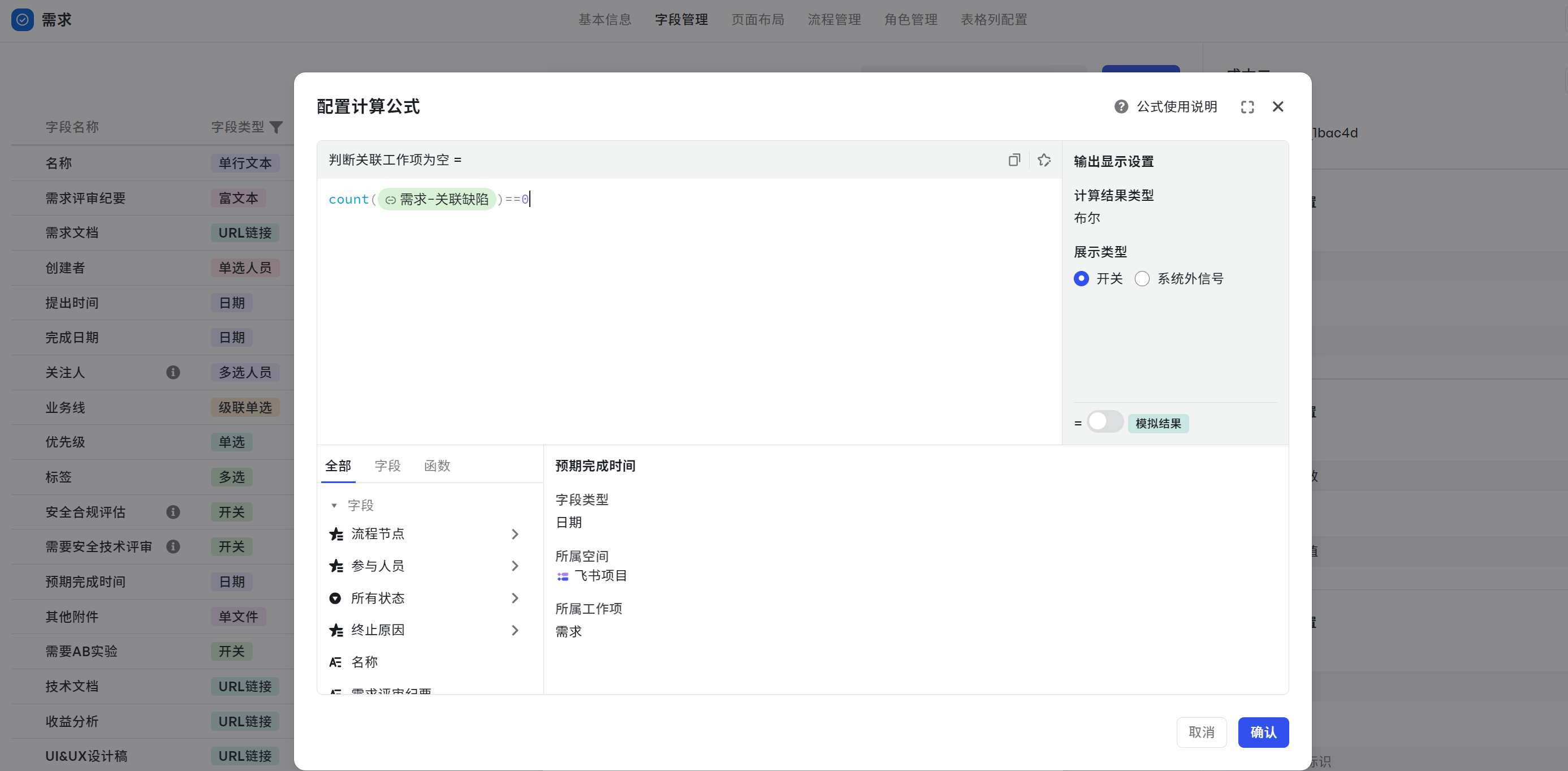
判断关联工作项为空
场景:判断某个关联工作项字段未填写来判断计算公式字段展示内容。
- 计算公式:count({需求-关联缺陷})==0
- 可复制公式:count($related{需求-关联缺陷})==0
解析如下:
如果关联工作项没有值,那么计算出来数据就为 0。类比还可以通过判断总估分不为 0,判断节点是否有估分。
250px|700px|reset
人力计算
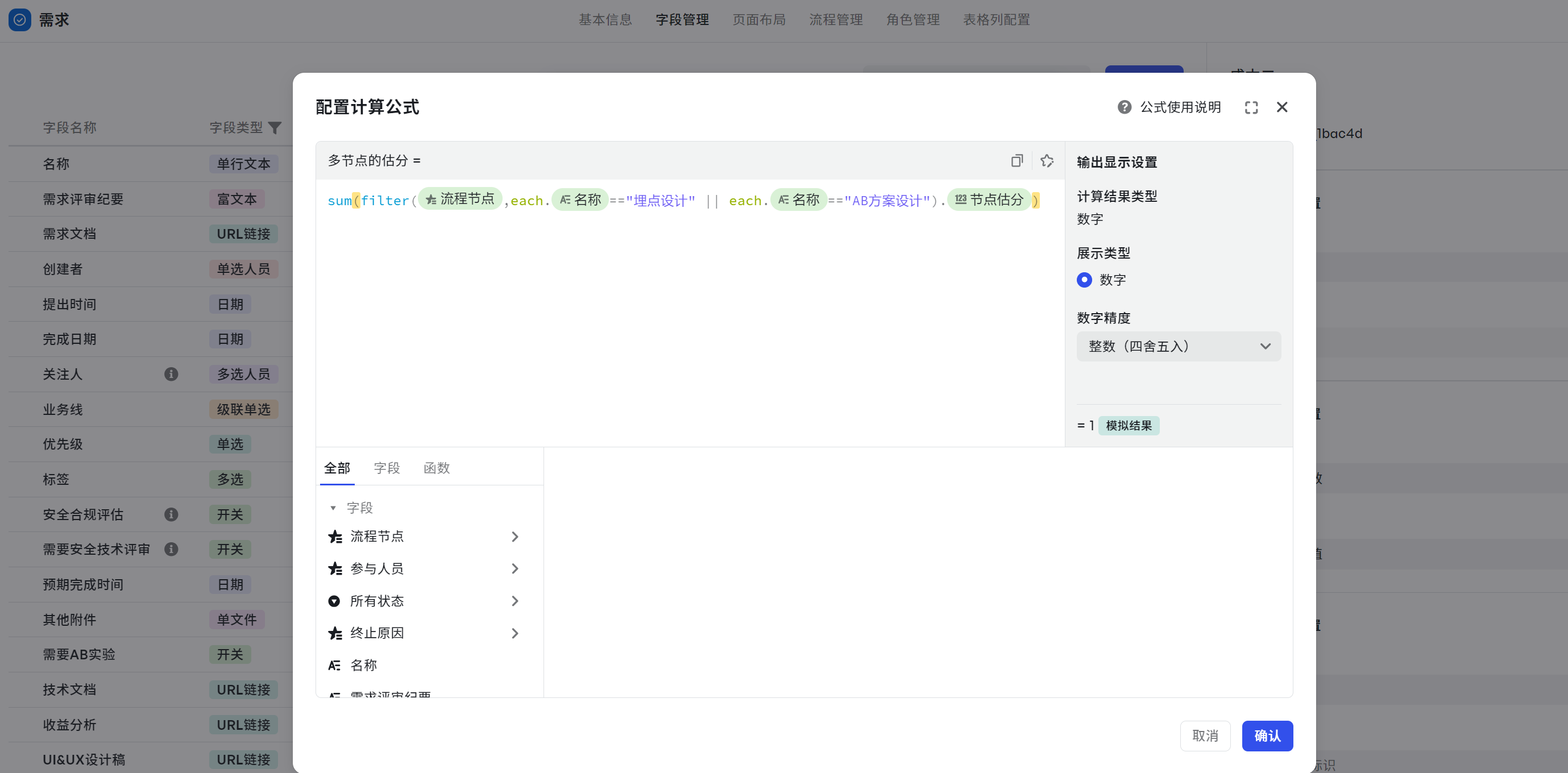
研发节点估分求和
场景:在双月盘点中,按需求研发人力规模需求视图排序。
- 字段:研发节点的估分
- 函数:sum() 、filter()、match()
- 计算公式一:sum(filter({流程节点},match(each.{名称},"开发")).{节点估分})
- 可复制公式:sum(filter(${流程节点},match(each.${名称},"开发")).${节点估分})
- 计算公式二:sum(filter({流程节点},each.{名称}=="埋点设计" || each.{名称}=="AB方案设计").{节点估分})
- 可复制公式:sum(filter(${流程节点},each.${名称}=="埋点设计" || each.${名称}=="AB方案设计").${节点估分})
250px|700px|reset
解析如下:
- 先用使用了 match() 函数匹配开发相关的节点:match(each.{名称},"开发")
- 接着 filter() 函数计算开发节点的估分:filter({流程节点},match(each.{名称},"开发")).{节点估分},这里输出格式为 ["{iOS 开发}.节点估分"," {Android 开发}.节点估分",....]。
- 如果是节点名称不同,用 || 或的关系来分别处理对应节点即可:filter({流程节点},each.{名称}=="埋点设计" || each.{名称}=="AB方案设计").{节点估分})
- 然后使用 sum() 函数求和:sum(filter({流程节点},match(each.{名称},"开发")).{节点估分})
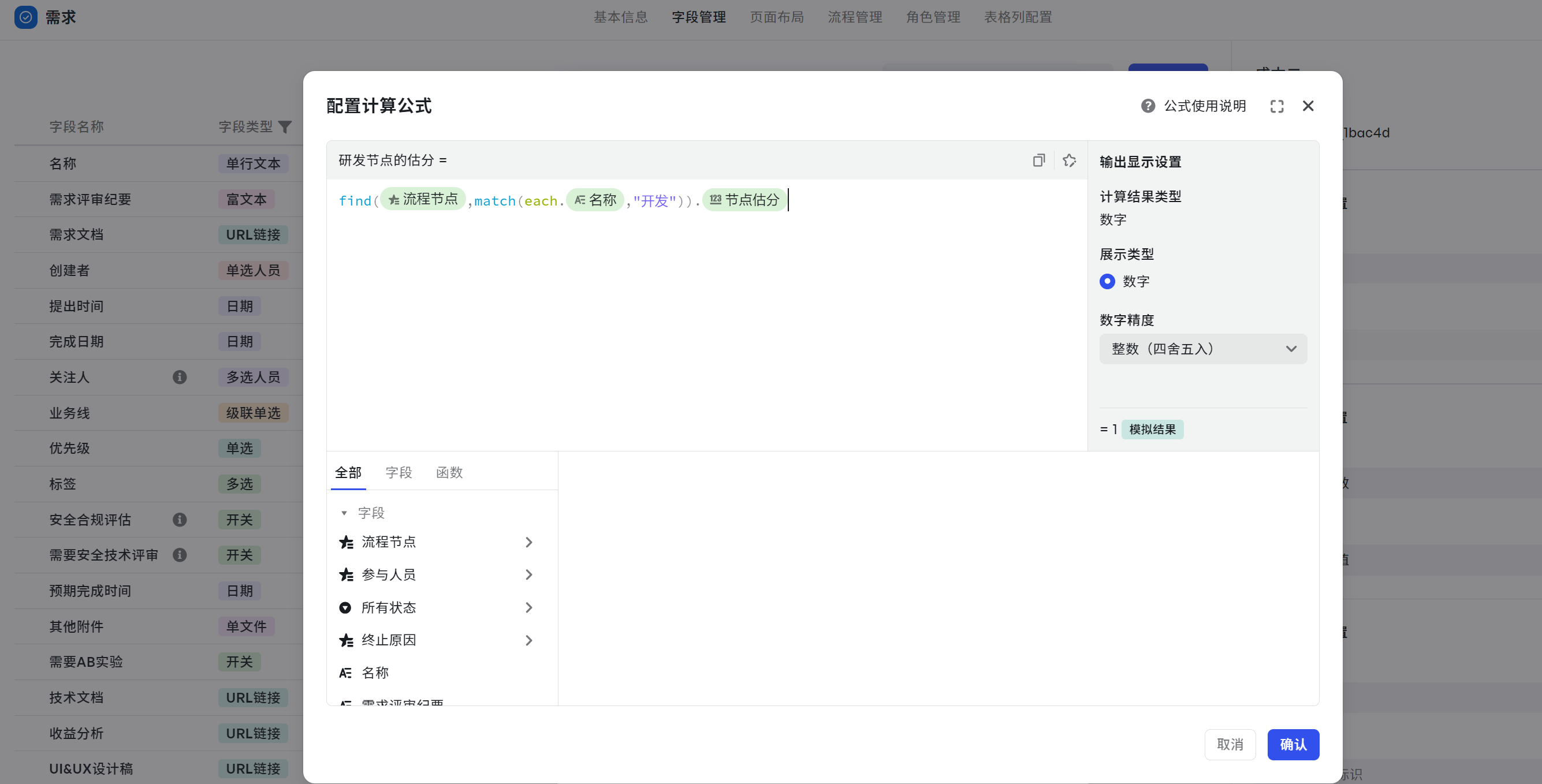
250px|700px|reset
为什么这里不用 find() 函数?
find() 函数输出结果是一个对象值, 且只能输出第一组对象的值,如果这里有 iOS、Android 开发节点,那么 find() 函数只会输出 iOS 开发节点的估分。输出结果可以表示为: {iOS 开发}.节点估分。
而使用了 filter(),则会输出一个数组,输出结果可以表示为:["{iOS 开发}.节点估分"," {Android 开发}.节点估分",....]
所以 find() 函数适合用来计算单个节点的估分。
类似公式还可以衍生出:
- 进行中的节点的估分计算:sum(filter({流程节点},each.{节点状态}=="进行中").{节点估分})
- 可复制公式:sum(filter(${流程节点},each.${节点状态}==$option{进行中}).${节点估分})
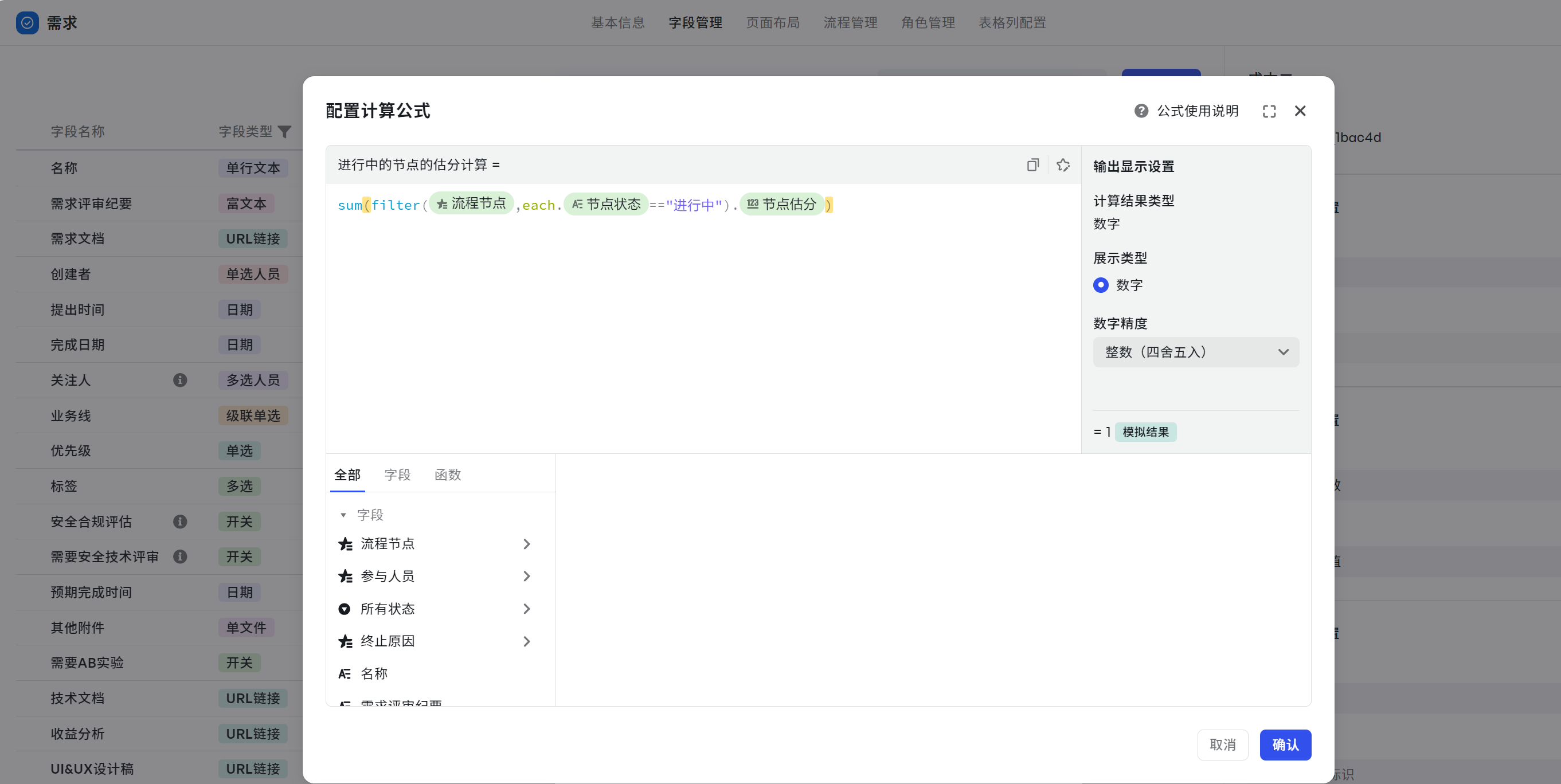
250px|700px|reset
- 某个节点进行中的估分计算:sum(filter({流程节点},each.{节点状态}=="进行中" && match(each.{名称},"开发节点")).{节点估分})。这里还可以等价于:find({流程节点},each.{节点状态}=="进行中" && each.{名称}=="埋点设计").{节点估分}
- 可复制公式:sum(filter(${流程节点},each.${节点状态}==$option{进行中} && match(each.${名称},"开发节点")).${节点估分})
- 在缺陷上展示研发节点的估分:sum(filter({缺陷关联需求}.{流程节点},match(each.{名称},"开发")).{节点估分})
- 可复制公式:sum(filter($related{缺陷关联需求}.${流程节点},match(each.${名称},"开发")).${节点估分})
大小需求判断
场景:研发人力规模大于 50,则为大需求;否则为小需求。
- 字段:研发节点的估分
- 函数:if()、sum() 、filter()、match()
- 计算公式:if(sum(filter({流程节点},match(each.{名称},"开发")).{节点估分}) > 50,"大需求","小需求")
- 可复制公式:if(sum(filter(${流程节点},match(each.${名称},"开发")).${节点估分}) > 50,"大需求","小需求")
解析如下:
- 首先获取到 iOS 开发和 Android 开发节点的总估分:sum(filter({流程节点},match(each.{名称},"开发")).{节点估分}),如果是两个不同节点,参考上述内容判断估分是否大于 50:sum(filter({流程节点},match(each.{名称},"开发")).{节点估分})>50
- 引入 if() 函数,如果大于 50,展示大需求,反之展示为小需求:if(sum(filter({流程节点},match(each.{名称},"开发")).{节点估分}) > 50,"大需求","小需求")
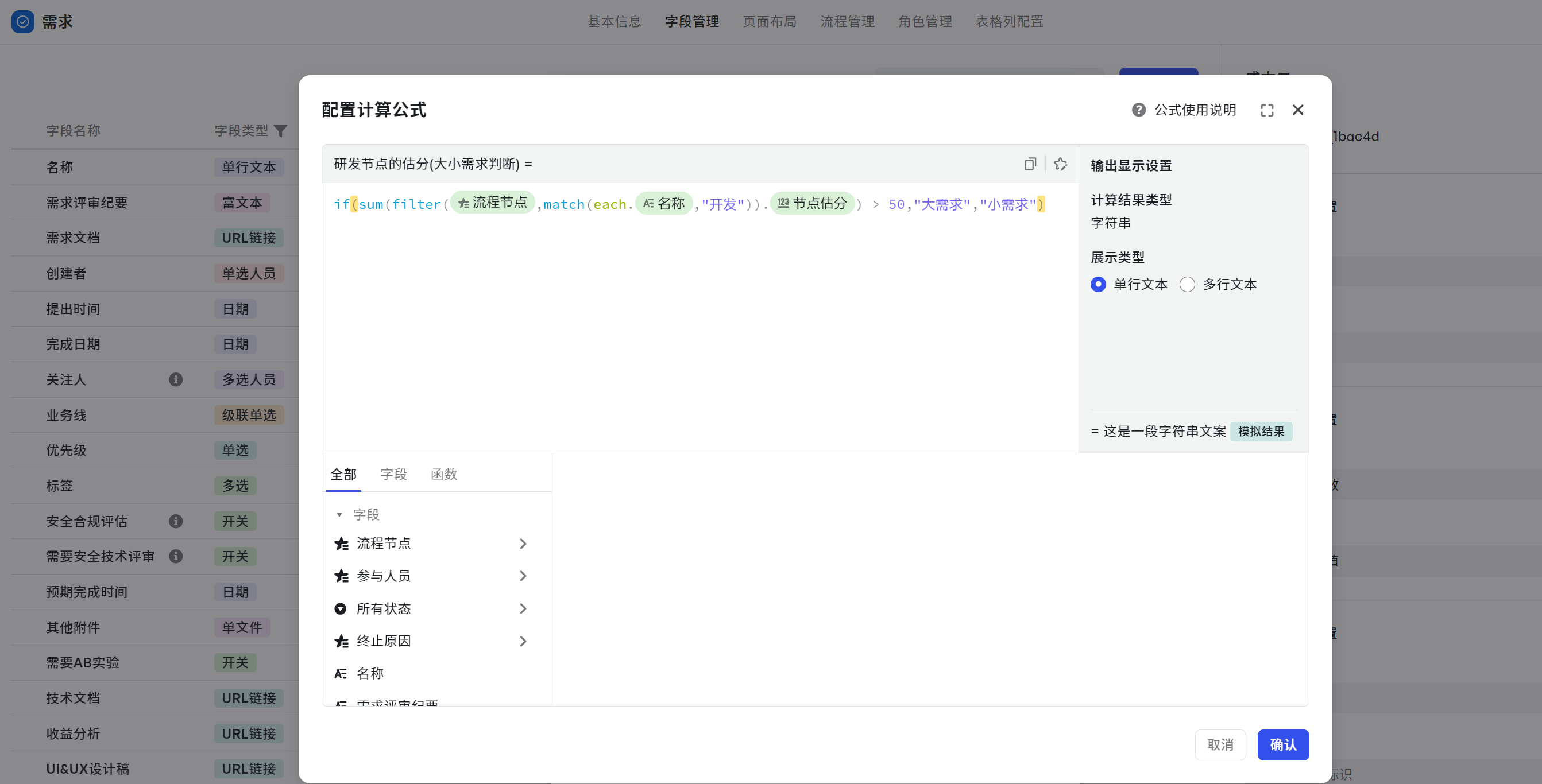
250px|700px|reset
进度占比
需求节点完成进度
场景:查看整体的节点完成情况,已经完成的节点/所有节点。
- 字段:节点状态、节点 ID
- 函数:countIf()、count()
- 计算公式:(countIf({流程节点},each.{节点状态}=="已完成")/count({流程节点}.{节点 ID}))
- 可复制公式:(countIf(${流程节点},each.${节点状态}==$option{已完成})/count(${流程节点}.${节点 ID}))
解析如下:
- 首先获取到已经完成的节点:countIf({流程节点},each.{节点状态}=="已完成"
- 接着获取所有节点:count({流程节点}.{节点 ID})
- 再通过未完成除以所有节点得到进度结果:(countIf({流程节点},each.{节点状态}=="已完成")/count({流程节点}.{节点 ID}))
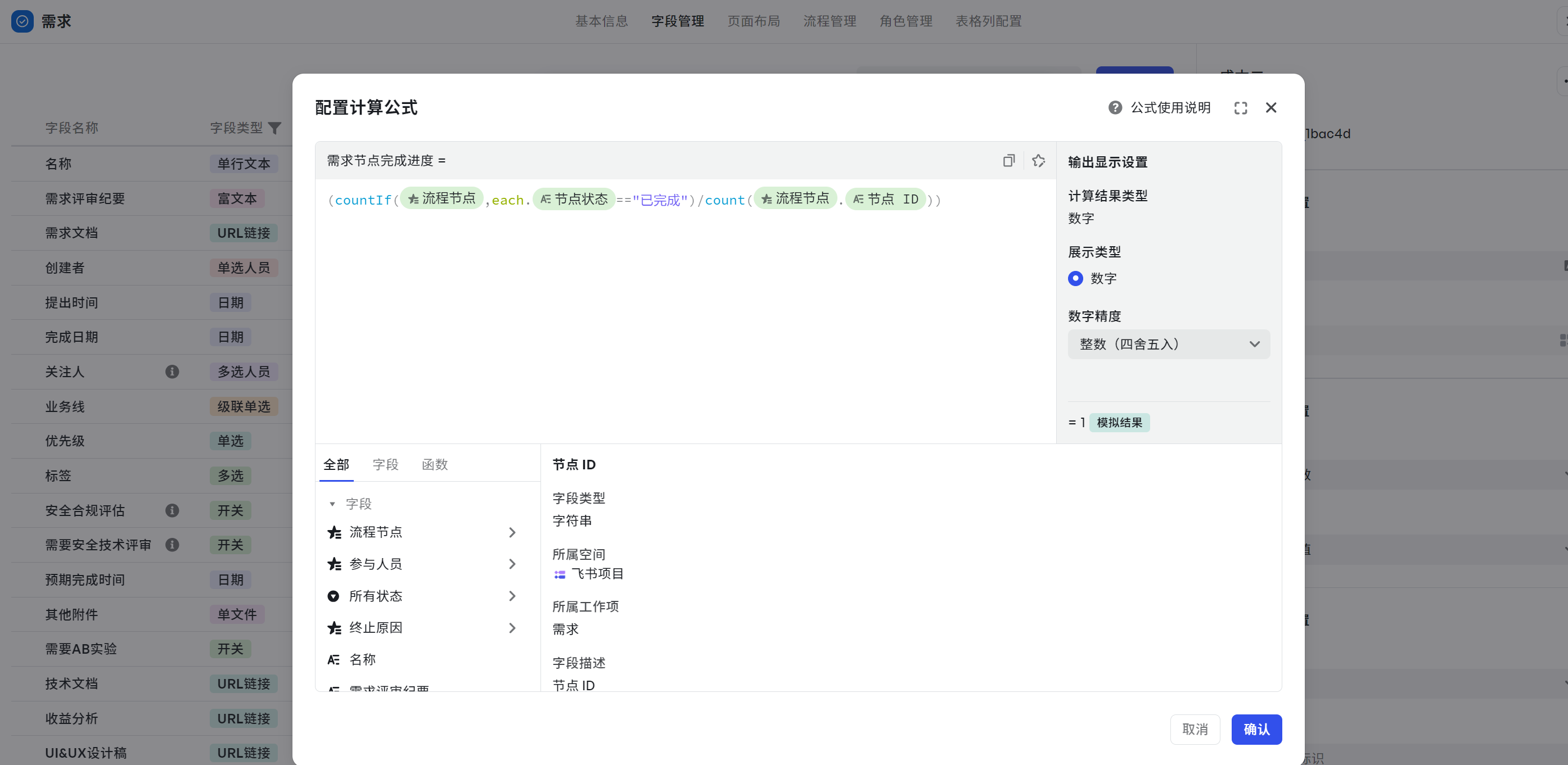
250px|700px|reset
如果希望输出是百分比,需要先乘以 100,然后通过 join 函数拼接 %。join([string((countIf({流程节点},each.{节点状态}=="已完成")/count({流程节点}.{节点状态}))*100),"%"]," ")
需求节点完成进度条效果
同样,在上述场景基础上,还可以制作一些有趣的计算字段,比如进度条。这里需要使用到 join() 函数以及 if() 函数。
- 首先对于整体进度划分 10 份,完成部分使用实心⚫代替,未完成部分使用空心⚪代替。
- 通过 if() 函数判断进度的区间,完成的节点/所有节点 > =1 展示,以此类推
- 使用 join() 函数拼接进度条 + 进度 + 百分比符号
if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=1,join(["●●●●●●●●●●",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.95,join(["●●●●●●●●●◐",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.9,join(["●●●●●●●●●○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.85,join(["●●●●●●●●◐○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.8,join(["●●●●●●●●○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.75,join(["●●●●●●●◐○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.7,join(["●●●●●●●○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.65,join(["●●●●●●◐○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.6,join(["●●●●●●○○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.55,join(["●●●●●◐○○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.5,join(["●●●●●○○○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.45,join(["●●●●◐○○○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.4,join(["●●●●○○○○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.35,join(["●●●◐○○○○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.3,join(["●●●○○○○○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.25,join(["●●◐○○○○○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.2,join(["●●○○○○○○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.15,join(["●◐○○○○○○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),if((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))>=0.1,join(["●○○○○○○○○○",string((countIf(${流程节点},each.${节点状态}=="已完成")/count(${流程节点}.${节点状态}))*100),"%"],""),"○○○○○○○○○○")))))))))))))))))))))))
周期相关
计算两个节点工作日差
场景:需求复盘中,需要盘点的实际耗时。
- 字段:节点名称、节点末次开始时间
- 函数:workdaysBetween()、find()
- 计算公式:workdaysBetween(find({流程节点},each.{名称}=="开始").{节点末次开始时间},find({流程节点},each.{名称}=="技术评审").{节点末次开始时间})
- 可复制公式:workdaysBetween(find(${流程节点},each.${名称}=="开始").${节点末次开始时间},find(${流程节点},each.${名称}=="技术评审").${节点末次开始时间})
解析如下:
- 首先通过 find() 函数找到两个节点的节点末次开始时间;
- 接着使用 workdaysBetween() 计算出工作日。
如果希望包含非工作日,可以使用 daysBetween() 函数。
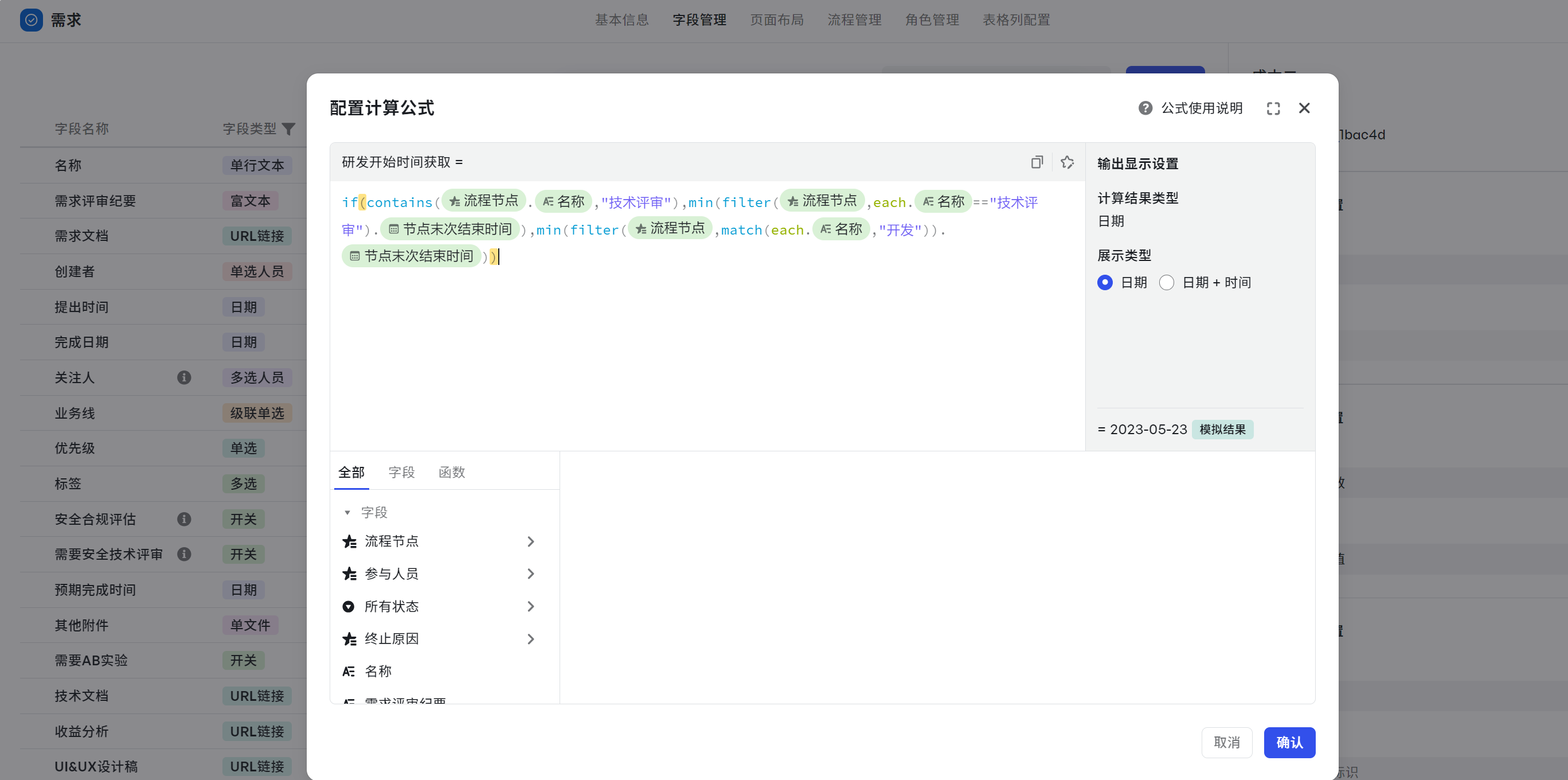
研发开始时间获取
场景:如果需求含有技术评审节点,取技术评审结束时间为开发开始时间;否则取各开发节点最早开始时间为开发开始时间。
- 字段:节点名称、节点时间
- 函数:if()、min()、contains()、filter()
- 计算公式:if(contains({流程节点}.{名称},"技术评审"),min(filter({流程节点},each.{名称}=="技术评审").{节点末次结束时间}),min(filter({流程节点},match(each.{名称},"开发")).{节点末次结束时间}))
- 可复制公式:if(contains(${流程节点}.${名称},"技术评审"),min(filter(${流程节点},each.${名称}=="技术评审").${节点末次结束时间}),min(filter(${流程节点},match(each.${名称},"开发")).${节点末次结束时间}))
解析如下:
- 判断需求是否包含某个节点:contains({流程节点}.{名称},"技术评审")
- 如果包含,取{节点末次开始时间}:filter({流程节点},each.{名称}=="技术评审").{节点末次结束时间}
- 不包含,取开发节点最早的时间,也就是筛选出开发节点,在取最小值:min(filter({流程节点},match(each.{名称},"开发")).{节点末次结束时间})
- 保证输出值统一,包含节点也要套上 min()
- 最后 if() 函数判断:if(contains({流程节点}.{名称},"技术评审"),min(filter({流程节点},each.{名称}=="技术评审").{节点末次结束时间}),min(filter({流程节点},match(each.{名称},"开发")).{节点末次结束时间}))
250px|700px|reset
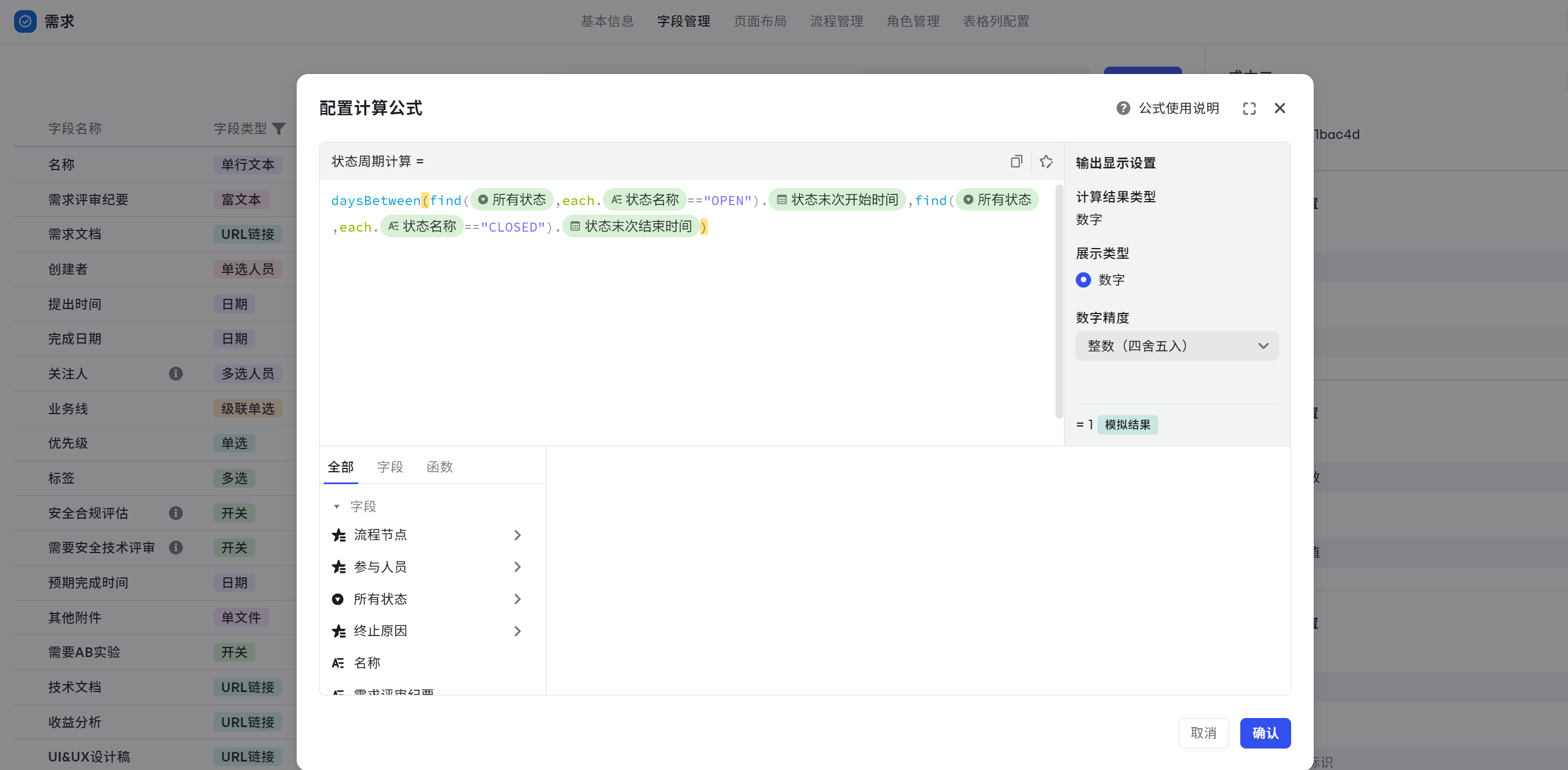
状态周期计算
场景:计算已经完成缺陷的耗时,即 CLOSED 减去 OPEN 的时间。
- 计算公式:daysBetween(find({所有状态},each.{状态名称}=="OPEN").{状态末次开始时间},find({所有状态},each.{状态名称}=="CLOSED").{状态末次结束时间})
- 可复制公式:daysBetween(find(${所有状态},each.${状态名称}=="OPEN").${状态末次开始时间},find(${所有状态},each.${状态名称}=="CLOSED").${状态末次结束时间})
250px|700px|reset
延期相关
计算延期节点数
场景:获取一个需求下有多少延期节点,从高到低在表格中排序,判断需求延期情况。
- 字段:节点状态、节点末次结束时间、预计结束日期
- 函数:countIf()
- 计算公式:countIf({流程节点},each.{节点状态}==已完成 && daysBetween(each.{节点排期}.{预计结束日期},each.{节点末次结束时间})>0 && each.{节点排期}.{周期时长} != 0)
- 可复制公式:countIf(${流程节点},each.${节点状态}==$option{已完成} && daysBetween(each.${节点排期}.${预计结束日期},each.${节点末次结束时间})>0 && each.${节点排期}.${周期时长} != 0)
解析如下:
- 先判断节点是否完成:each.{节点状态}==已完成
- 接着判断节点实际结束时间大于节点排期的结束时间:daysBetween(each.{节点排期}.{预计结束日期},each.{节点末次结束时间})>0
- 注意需要考虑节点没有排期的情况: each.{节点排期}.{周期时长} != 0
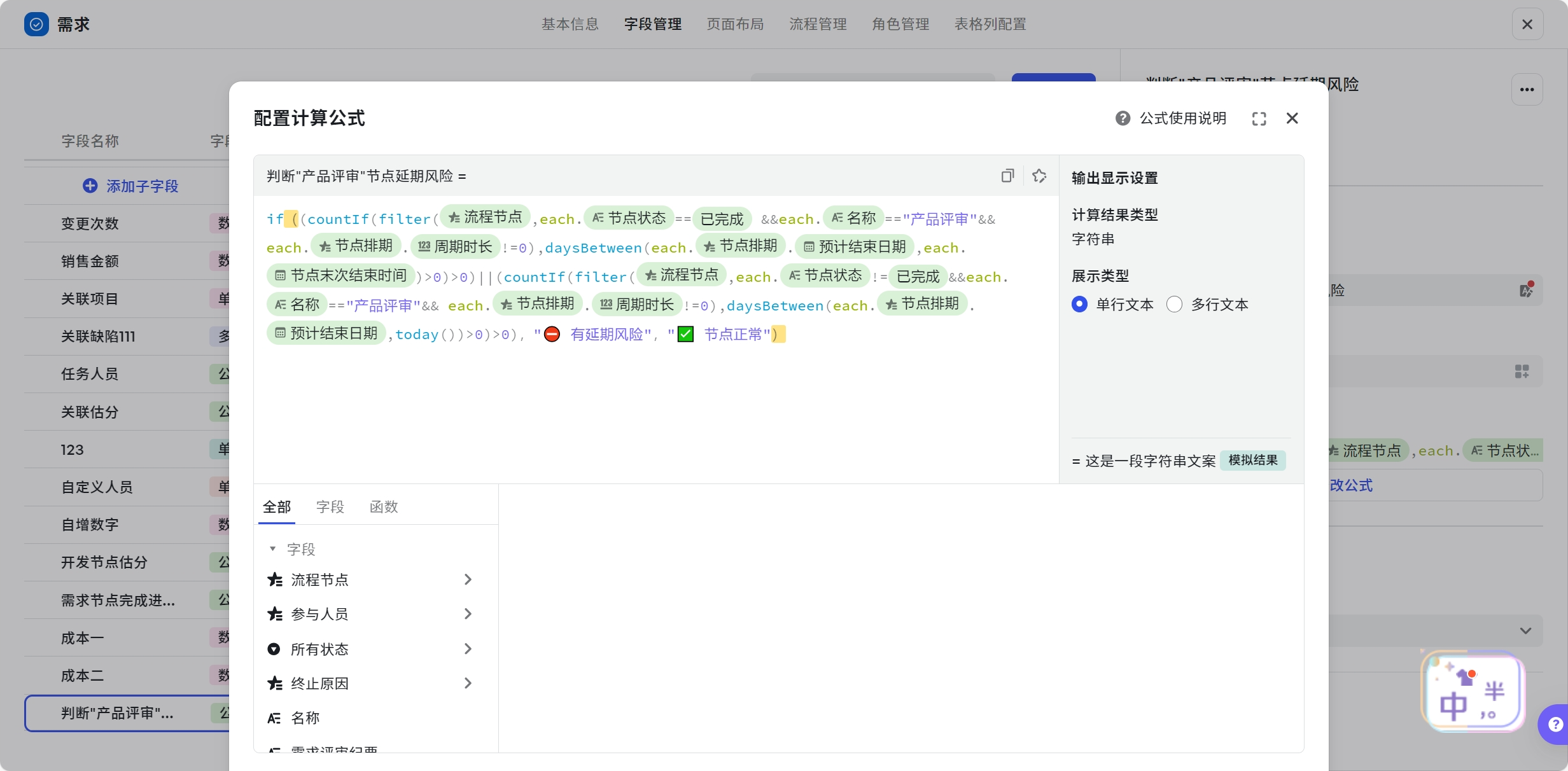
判断某个节点是否延期
场景:判断某个核心节点是否延期,如果延期就展示该节点已经延期,反之展示节点正常。
- 字段:节点状态、节点名称、
- 函数:if()、daysBetween()、countIf()、filter()
- 计算公式:if((countIf(filter({流程节点},each.{节点状态}=={已完成} &&each.{名称}=="产品评审"&& each.{节点排期}.{周期时长}!=0),daysBetween(each.{节点排期}.{预计结束日期},each.{节点末次结束时间})>0)>0)||(countIf(filter({流程节点},each.{节点状态}!={已完成}&&each.{名称}=="产品评审"&& each.{节点排期}.{周期时长}!=0),daysBetween(each.{节点排期}.{预计结束日期},today())>0)>0),"⛔️ 有延期风险","✅ 节点正常")
- 可复制公式:if((countIf(filter(${流程节点},each.${节点状态}==$option{已完成} &&each.${名称}=="产品评审"&& each.${节点排期}.${周期时长}!=0),daysBetween(each.${节点排期}.${预计结束日期},each.${节点末次结束时间})>0)>0)||(countIf(filter(${流程节点},each.${节点状态}!=$option{已完成}&&each.${名称}=="产品评审"&& each.${节点排期}.${周期时长}!=0),daysBetween(each.${节点排期}.${预计结束日期},today())>0)>0),"⛔️ 有延期风险","✅ 节点正常")
解析如下:
- 先判断节点是否完成:each.{节点状态}=={已完成}或者each.{节点状态}!={已完成}
- 接着判断节点名称: each.{名称}=="产品评审"
- 再判断节点排期填写不为空:each.{节点排期}.{周期时长}!=0
- 判断逻辑是:
- 当节点未完成时,比较节点排期的结束时间和今天,结果大于0说明存在延期:daysBetween(each.{节点排期}.{预计结束日期},today())>0
- 当节点已完成时,比较节点排期的结束时间和节点实际结束时间,结果大于0说明存在延期:节点实际结束时间大于节点排期的结束时间:daysBetween(each.{节点排期}.{预计结束日期},each.{节点末次结束时间})>0
- 最后 if() 判断 countIf() 是否大于0 ,大于0,代表有此现象,说明有延期风险,等于0代表没有此现象,说明一切正常。
250px|700px|reset
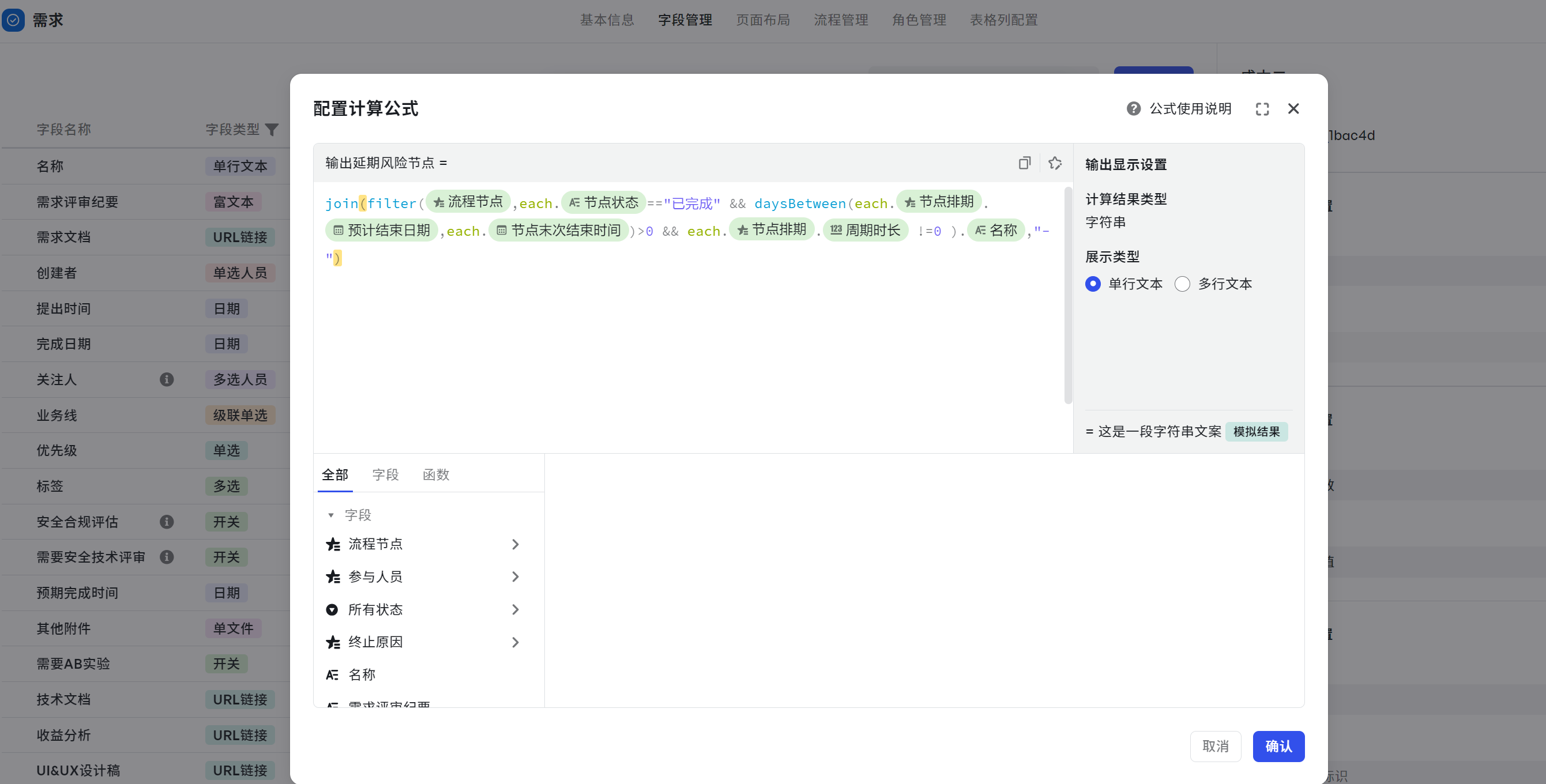
输出延期节点展示在表格中
场景:将所有延期节点都输出在表格上,直观查看。
- 函数:join()、filter()、daysBetween()
- 计算公式:join(filter({流程节点},each.{节点状态}=="已完成" && daysBetween(each.{节点排期}.{预计结束日期},each.{节点末次结束时间})>0 && each.{节点排期}.{周期时长} !=0 ).{名称},"-")
- 可复制公式:join(filter(${流程节点},each.${节点状态}==$option{已完成} && daysBetween(each.${节点排期}.${预计结束日期},each.${节点末次结束时间})>0 && each.${节点排期}.${周期时长} !=0 ).${名称},"-")
解析如下:
- 先判断是否延期,filter({流程节点},each.{节点状态}=="已完成" && daysBetween(each.{节点排期}.{预计结束日期},each.{节点末次结束时间})>0 && each.{节点排期}.{周期时长} !=0 )
- 接着获取到延期的节点名称:filter({流程节点},each.{节点状态}==已完成 && daysBetween(each.{节点排期}.{预计结束日期},each.{节点末次结束时间})>0 && each.{节点排期}.{周期时长} !=0 ).{名称}
- 再用 join 函数进行拼接。
250px|700px|reset
计算某个节点进入次数
场景:计算需求某个节点频繁打回的次数
- 字段:节点名称、节点进入次数
- 函数:find()
- 计算公式:find({流程节点},each.{名称}=="埋点设计").{节点进入次数}
- 可复制公式:find(${流程节点},each.${名称}=="埋点设计").${节点进入次数}
解析如下:
- 筛选节点为埋点设计:find({流程节点},each.{名称}=="埋点设计")
- 接着获取进入次数:find({流程节点},each.{名称}=="埋点设计").{节点进入次数}
计算某个状态进入次数
场景:计算缺陷某个状态打回次数,作为质量的一个判断维度
- 字段:所有状态、状态名称、状态进入次数
- 函数:find()
- 计算公式:find({所有状态},each.{状态名称}=="OPEN").{状态进入次数}
- 可复制公式:find(${所有状态},each.${状态名称}=="OPEN").${状态进入次数}
文本拼接
规则化的名称
场景:拼接优先级和需求名称,直观查看相关数据。
- 字段:优先级、名称
- 函数:join()
- 计算公式:join([{优先级},{名称}],"-")
- 可复制公式:join([${优先级},${名称}],"-")
- 解析:获取到对应的字段值,使用 join 函数进行拼接。
类似可以将终止原因打印在出来:join({终止原因}.{原因},"")
展示关联工作项的字段
场景:需要在需求上展示版本进度,用于确定版本进度。
- 字段:关联版本、版本进度
- 函数:join()、filter()
- 计算公式:join(filter({需求-关联版本},each.{优先级}==P0).{当前状态},"")
- 可复制公式:join(filter($related{需求-关联版本},each.${优先级}==$option{P0}).${当前状态},"")
解析如下:
- 通过 @ 获取到关联工作项
- filter 获取到对应的时间字段值 filter({需求-关联版本},each.{优先级}==P0).{当前状态}
- 使用 join 进行拼接,join(filter({需求-关联版本},each.{优先级}==P0).{当前状态},"")
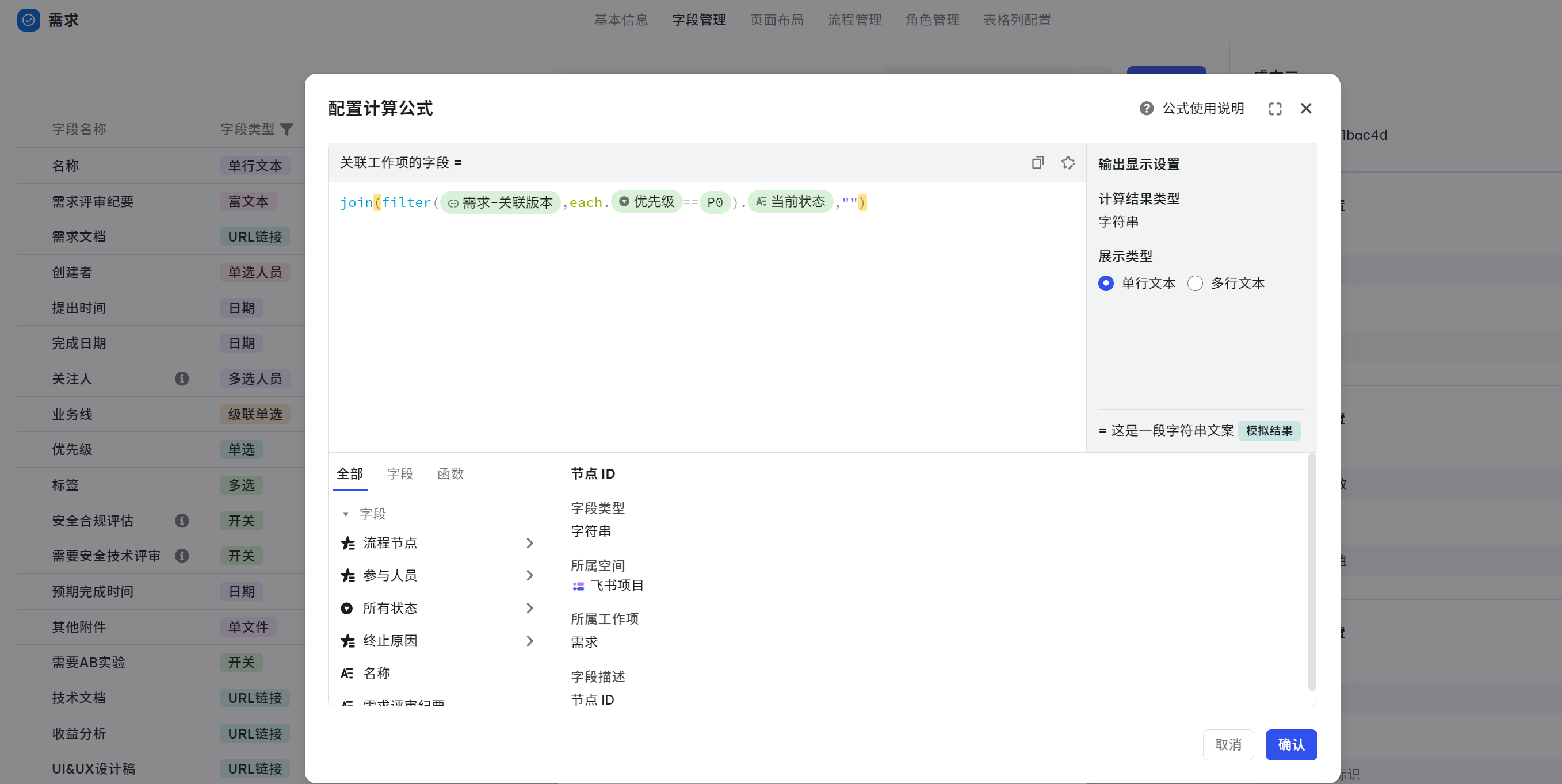
250px|700px|reset
注意时间不支持展示,会报错。
跨级展示关联工作项的字段
场景:需要在缺陷上展示项目的优先级,用于对缺陷优先级进行校准,缺陷和需求关联,需求和项目关联。
- 字段:关联需求、所属项目、优先级
- 函数:find()
- 计算公式:FIND(缺陷-关联需求.需求-所属项目, true).优先级
- 可复制公式:FIND($related{缺陷-关联需求}.$related{需求-所属项目},true).${优先级}
解析如下:
- 通过@获取到一级关联工作项
- 输入"."获取到二级关联工作项
- 用 find 函数获取到二级关联工作项的信息
自定义自增编号规则
场景一:编号是工作项常见信息,可用于工作项实例的身份识别。
- 字段:自增数字
- 函数:format()
- 计算公式:format({自增数字},"0000")
- 可复制公式:FORMAT(${自增数字},"0000")
- 解析如下:
- 通过自增数字获取到工作项编号
- format函数统一位数,对齐美观,format({自增数字},"0000")
- 输出效果:0002、0365、12345(允许数字超出位数限制)
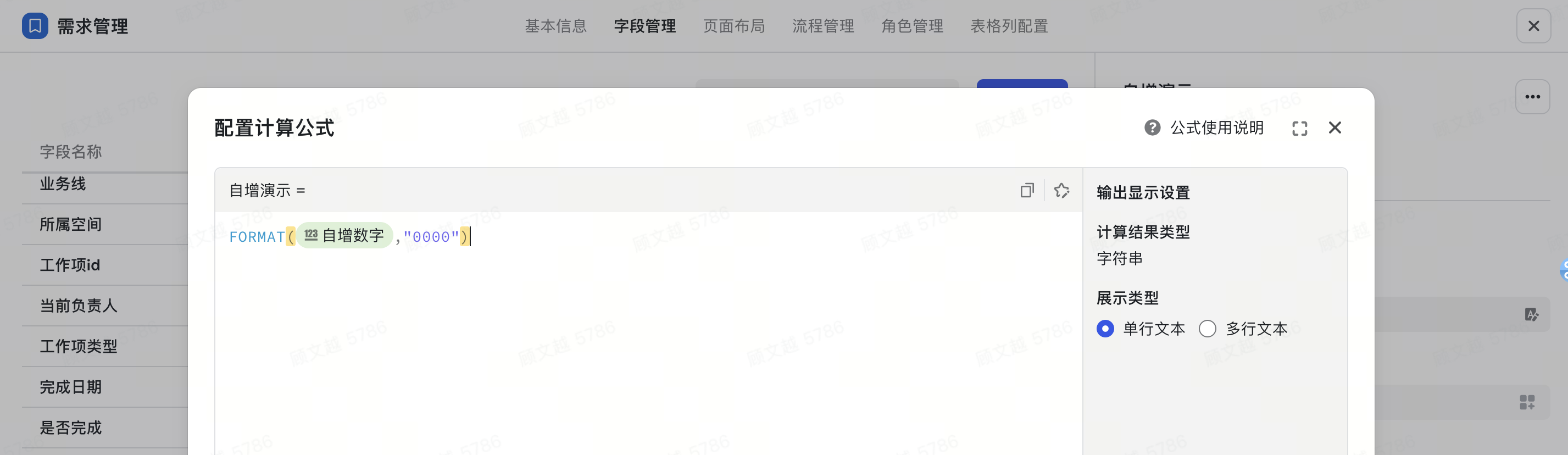
250px|700px|reset
场景二:通过拼接常量、日期、字段等内容,在工作项编号中呈现更多信息。
- 字段:自增数字、优先级、创建时间
- 函数:join()、if()、format()
- 计算公式:join([if({优先级}=="P0","A",if({优先级}=="P1","B","C")),format({创建时间},"YYYYMM"),format({自增数字},"000")],"")
- 可复制公式:JOIN([IF(${优先级}==$option{P0},"A",IF(${优先级}==$option{P1},"B","C")),FORMAT(${自增数字},"0000")],"-")
- 解析如下:
- 通过自增数字获取到工作项编号
- format函数统一位数:format({自增数字},"000")
- format函数统一创建时间格式:format({创建时间},"YYYYMM")
- 判断优先级:if({优先级}=="P0","A",if({优先级}=="P1","B","C"))
- 使用 join 进行拼接,join([if({优先级}=="P0","A",if({优先级}=="P1","B","C")),format({创建时间},"YYYYMM"),format({自增数字},"000")],"")
- 输出效果: A202403001、B202403002、C202403003
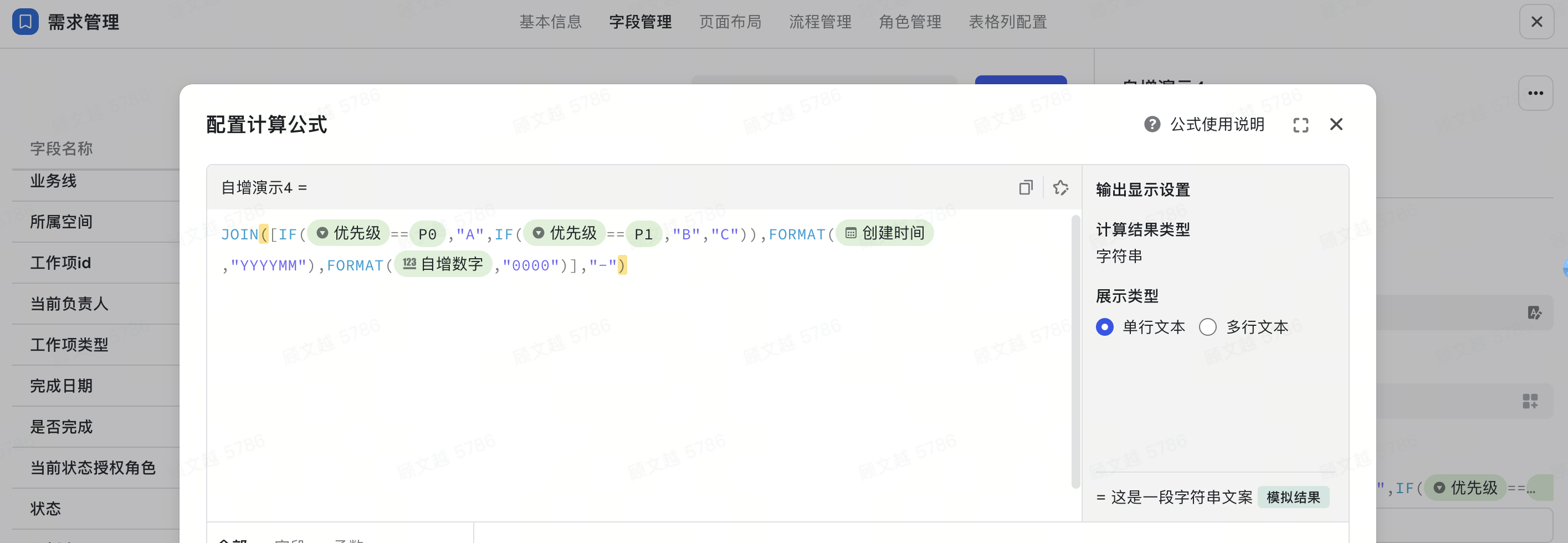
250px|700px|reset
场景三:针对不同条件实行不同编号规则,在企业编号规则变更场景中,实现原记录用老规则,新增记录用新规则定义。
- 字段:自增数字、创建时间、业务线
- 函数:join()、if()、format()
- 计算公式:if({自增数字}<1000,join([format({创建时间},"YYYYMM"),format({自增数字},"000000")],"-"),join([{业务线}.{一级选项},format({创建时间},"YYYYMM"),format({自增数字},"000000")],"-"))
- 可复制公式:if(${自增数字}<1000,join([format(${创建时间},"YYYYMM"),format(${自增数字},"000000")],"-"),join([${业务线}.${一级选项},format(${创建时间},"YYYYMM"),format(${自增数字},"000000")],"-"))
- 解析如下:
- 通过自增数字获取到工作项编号
- format函数统一位数:format({自增数字},"000000")
- format函数统一创建时间格式:format({创建时间},"YYYYMM")
- 判断从第几个工作项开始规则变更 if{自增数字}<1000
- 使用 join 分别进行拼接:join([format({创建时间},"YYYYMM"),format({自增数字},"000000")],"-"),join([{业务线}.{一级选项},format({创建时间},"YYYYMM"),format({自增数字},"000000")],"-")
- 输出效果:
- 前1000条记录,用老规则:202201-000005
- 1000条之后的记录,用新规则:Base-202403-001234
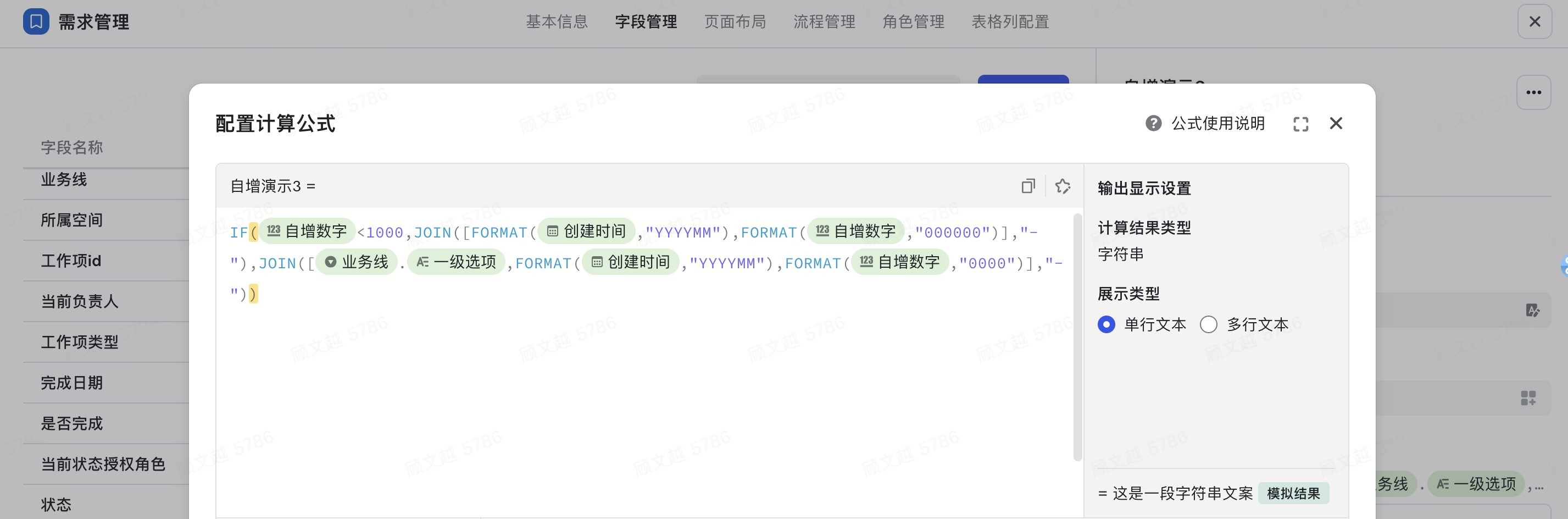
250px|700px|reset
信号流转
限制节点流转
公式字段可以配置为系统外信号类型字段,作为节点准出条件。场景如仅当需求下 OPEN 或 REOPEN 的 P0 BUG 数量为 0,测试节点才可流转通过。
首先创建一个计算公式字段,计算公式如下:
- if(count(filter({[关系]缺陷关联需求},each.{优先级}==P0 && (each.{当前状态}=="OPEN" || each.{当前状态}=="REOPEN"))) == 0,true,false)
- 可复制公式:if(count(filter($related{[关系]缺陷关联需求},each.${优先级}==$option{P0} && (each.${当前状态}==$option{OPEN} || each.${当前状态}==$option{REOPEN}))) == 0,true,false)
在字段显示设置中,选择为信号字段。
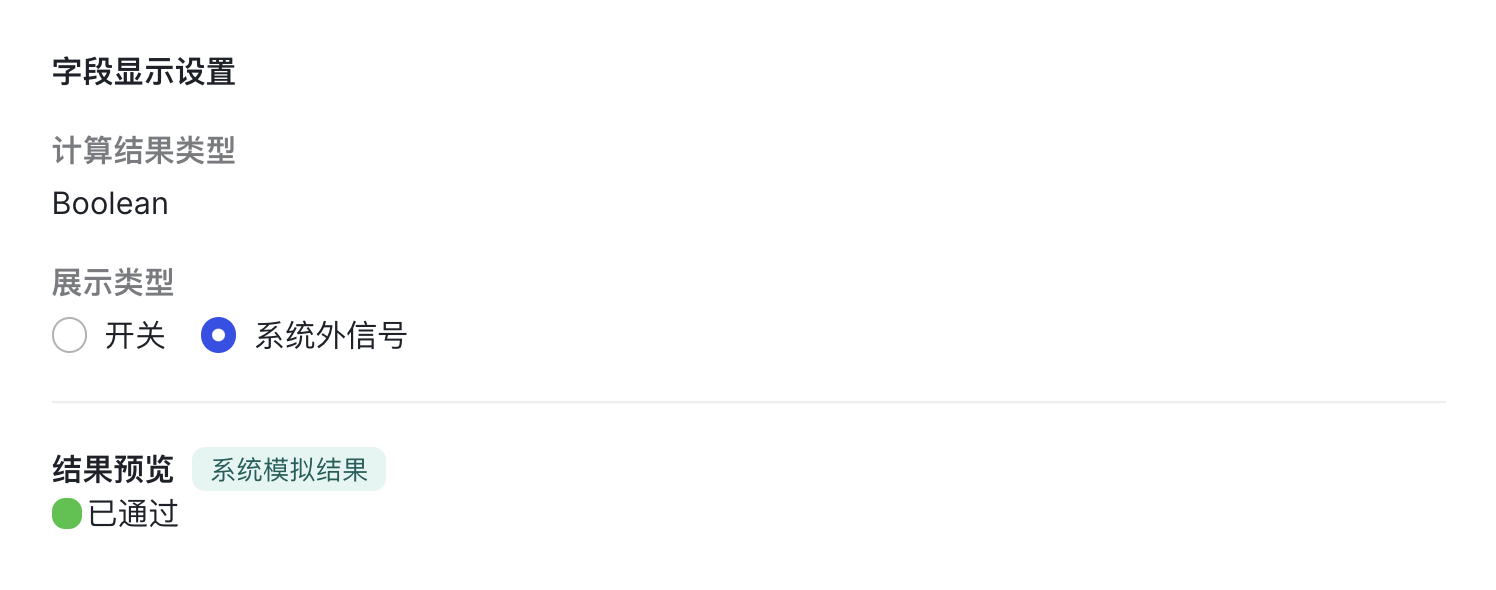
250px|700px|reset
前往流程规则,选择某个流程,将测试节点设置为自动确认节点。
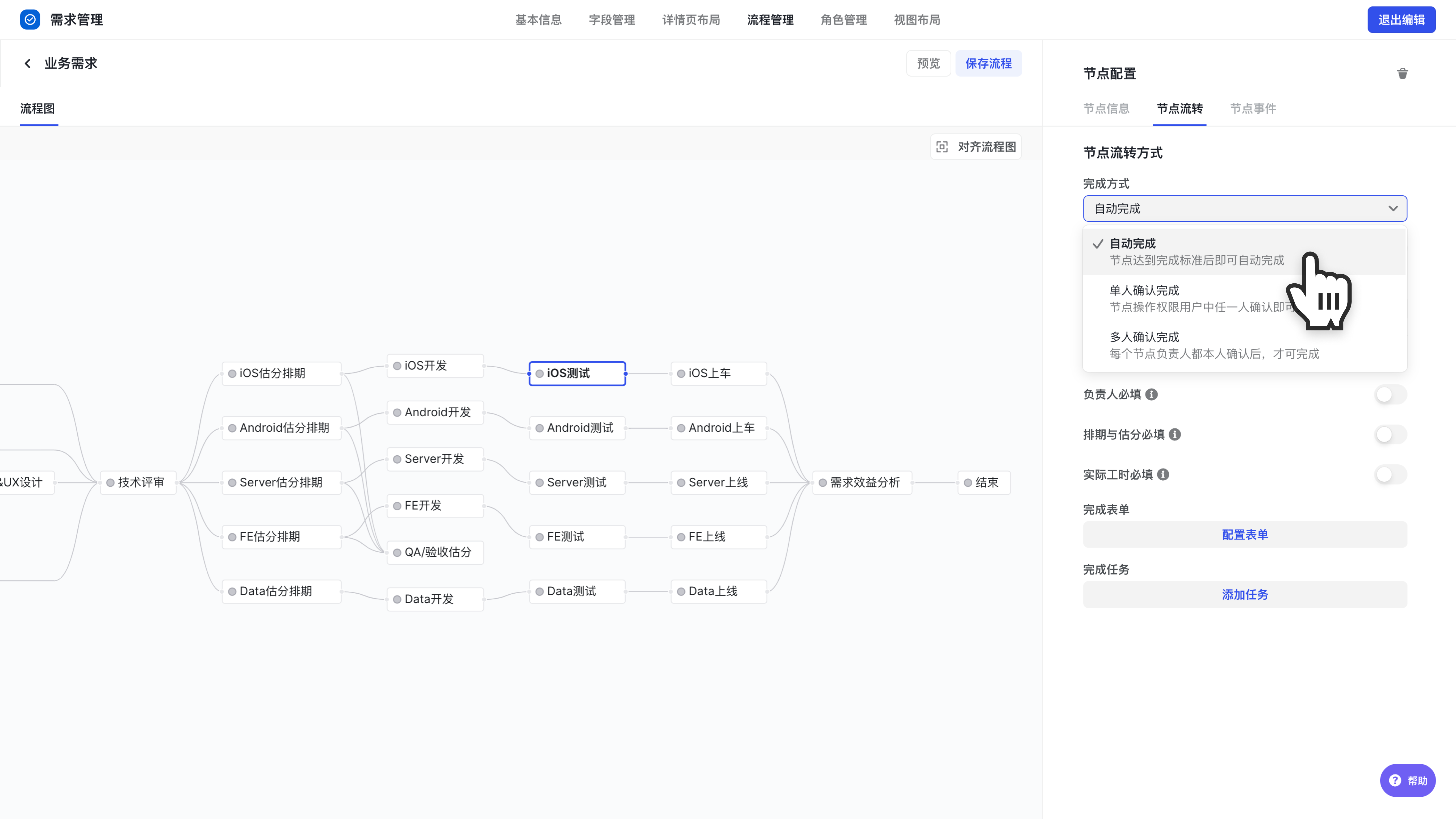
250px|700px|reset
接着点击节点流转选项,找到完成表单配置。
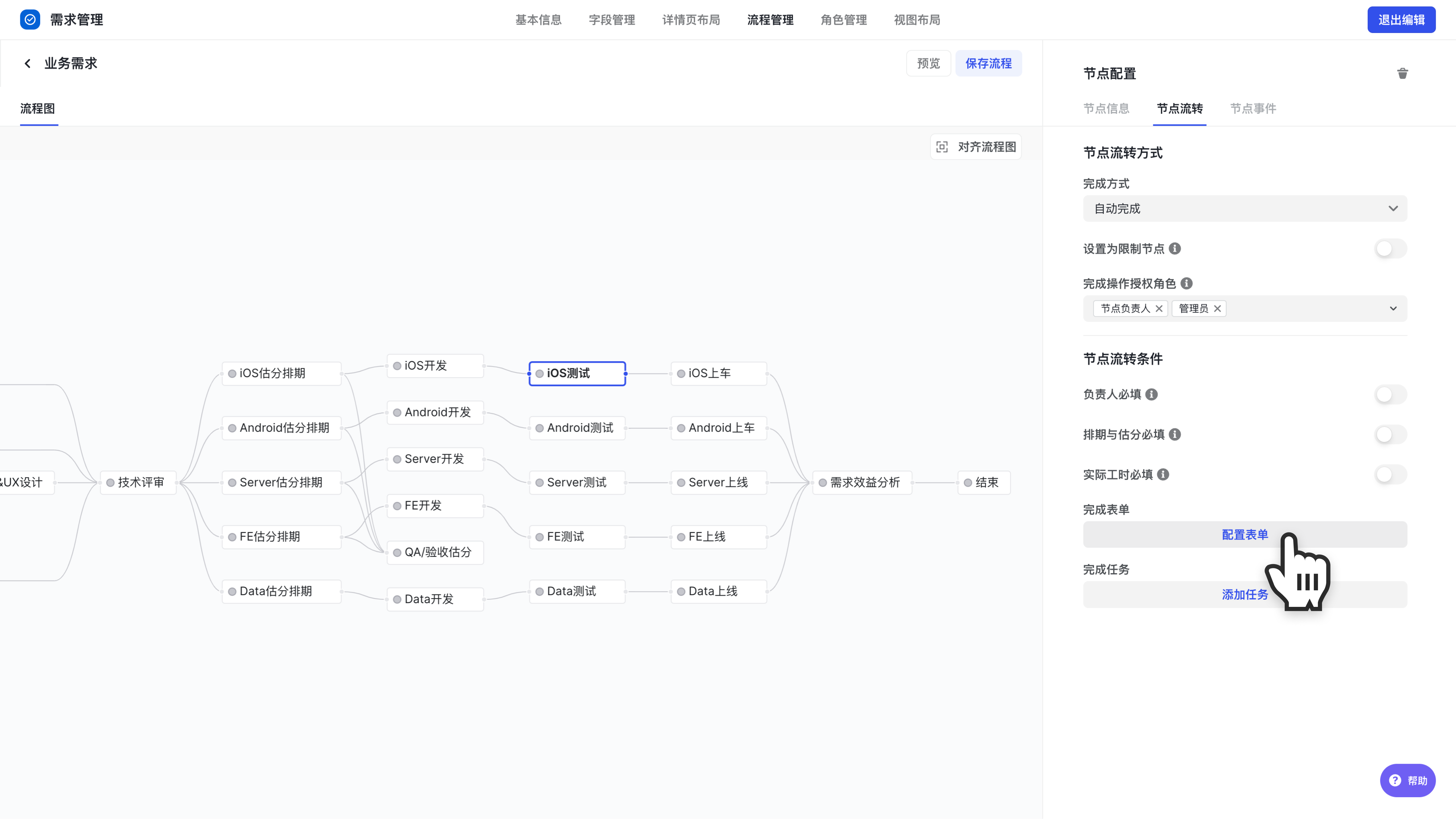
250px|700px|reset
在弹出的界面中,左侧拖拽字段至表单中,设置为必填。
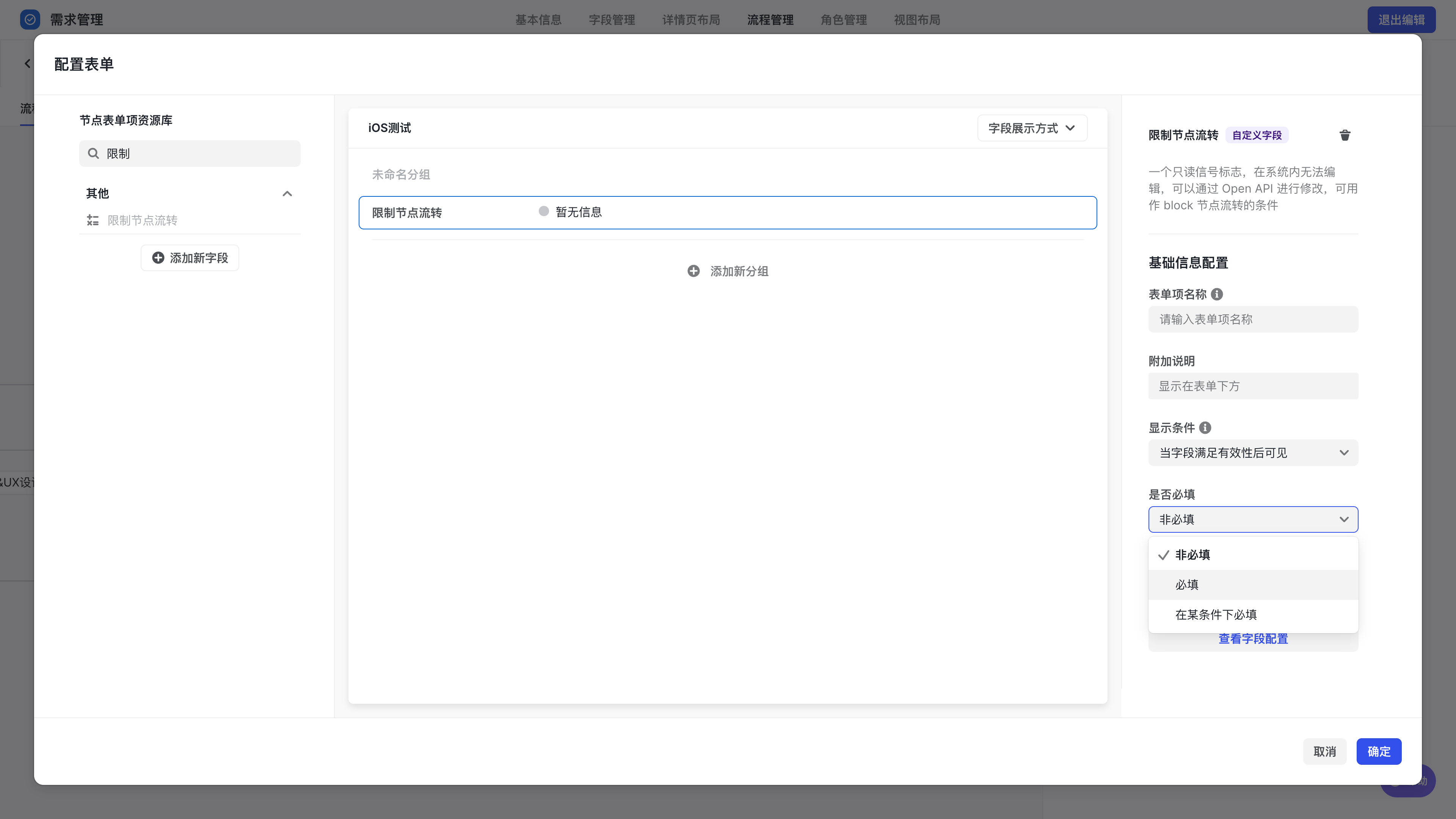
250px|700px|reset
需求详情页直接升级或者创建需求,即可完成配置。
250px|700px|reset
注意:信号对增量无法正确计算,意味着增加一个新的缺陷,不影响完成节点是否已经流转。且 if() 必须 true 和 false 才能生成布尔值
扩展场景:
- 到达开发排期开始时间后,自动完成“启动开发”节点并流转至开发中:if(count(filter(计算字段压测空间01_缺陷-关联需求_计算字段压测空间01_缺陷,each.{优先级}=="P0"))==0,true,false)
- 全部关联版本上线后,需求上线节点自动流转通过。
任务相关
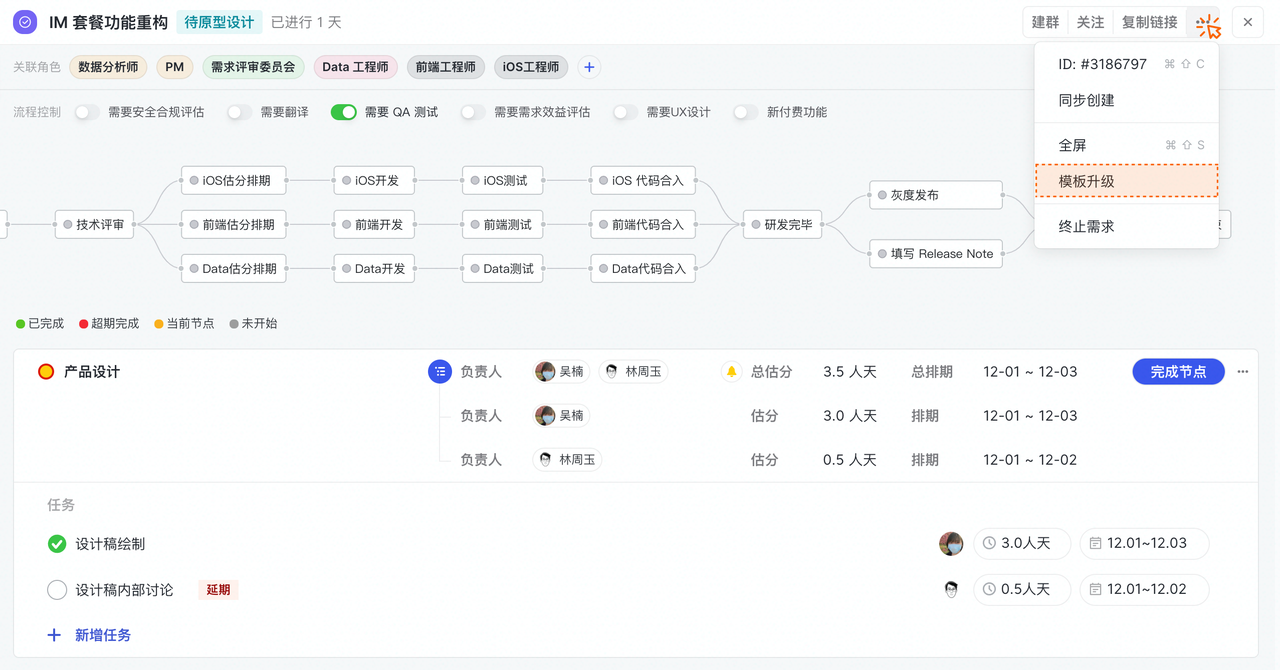
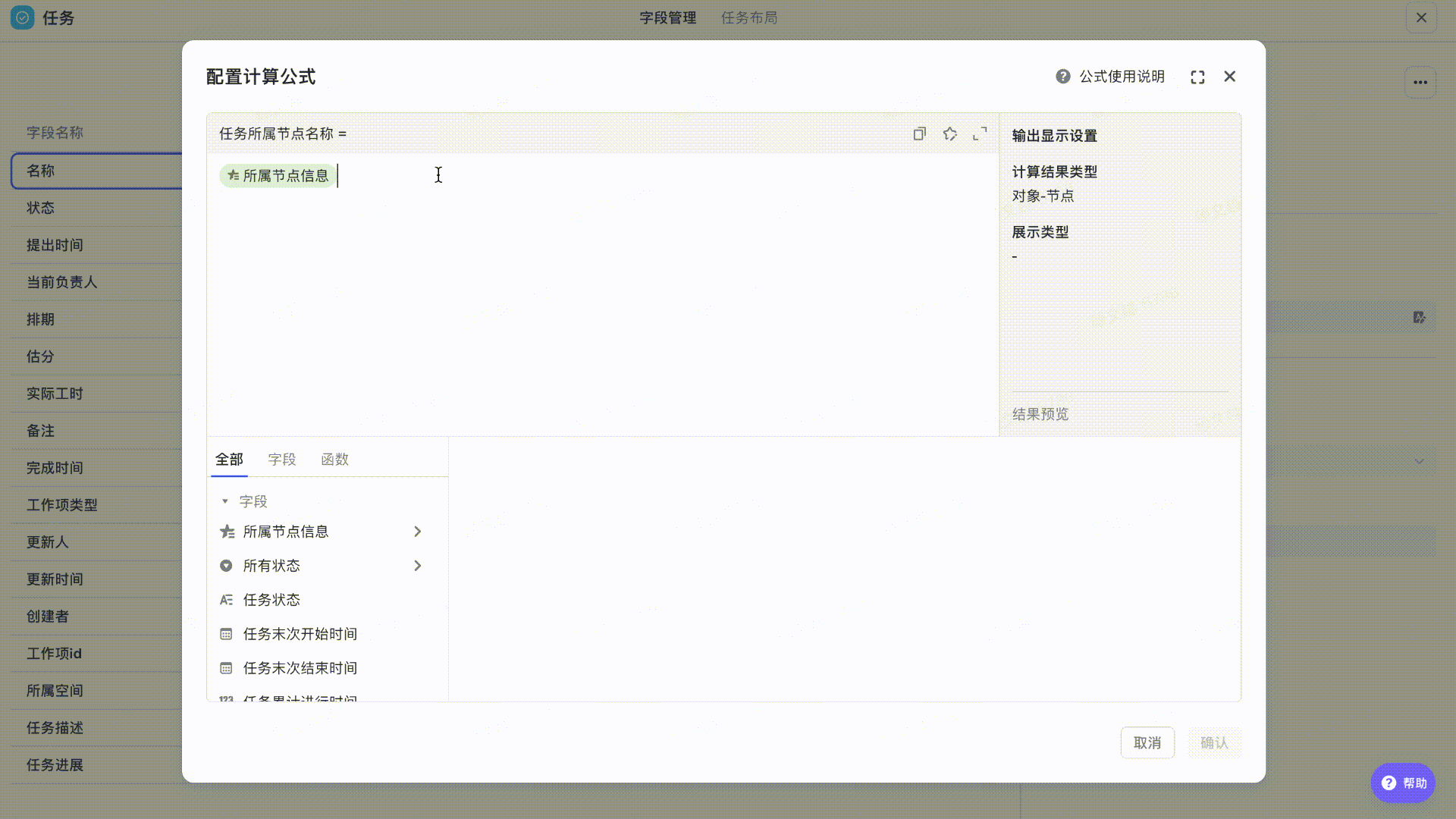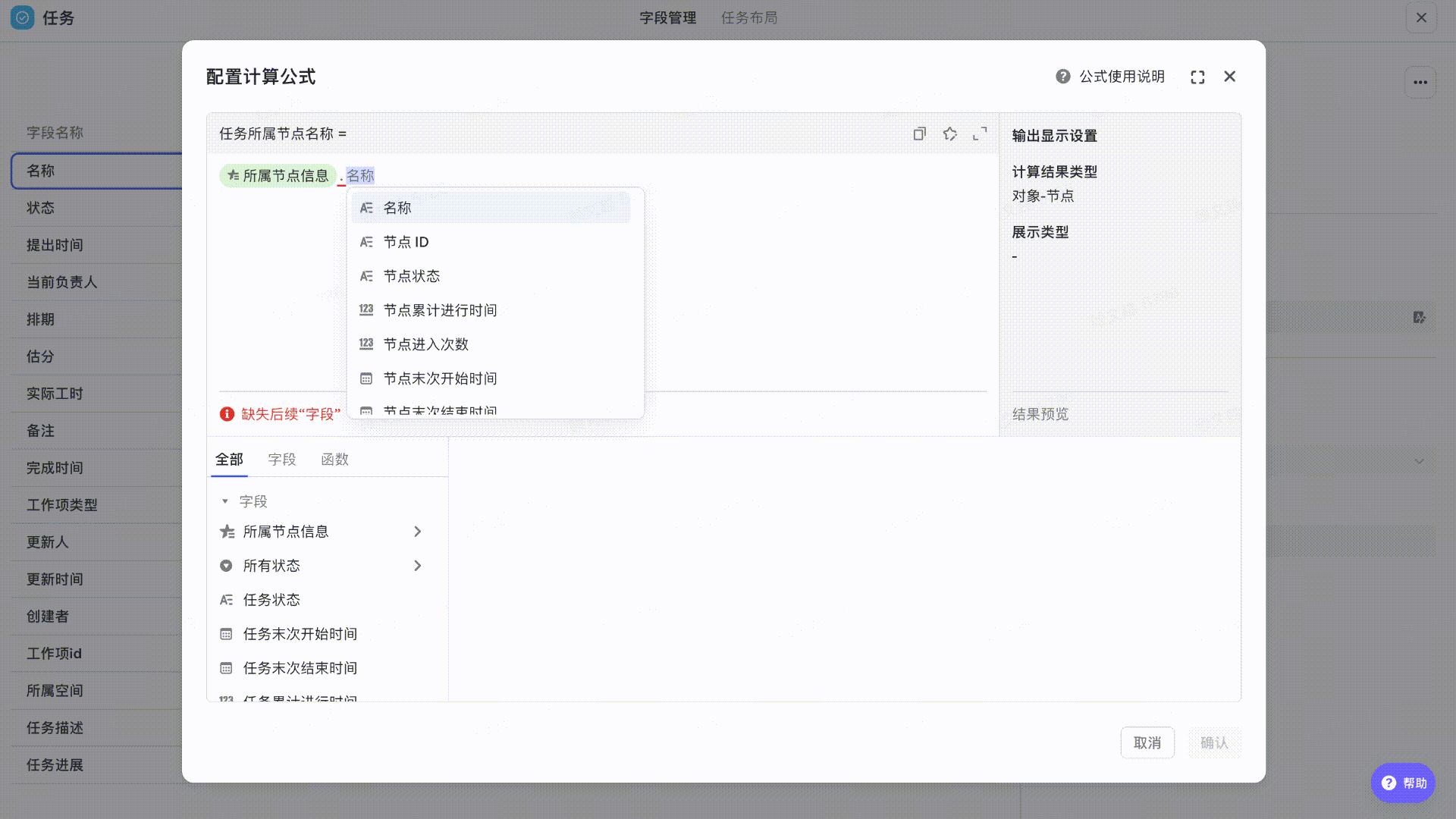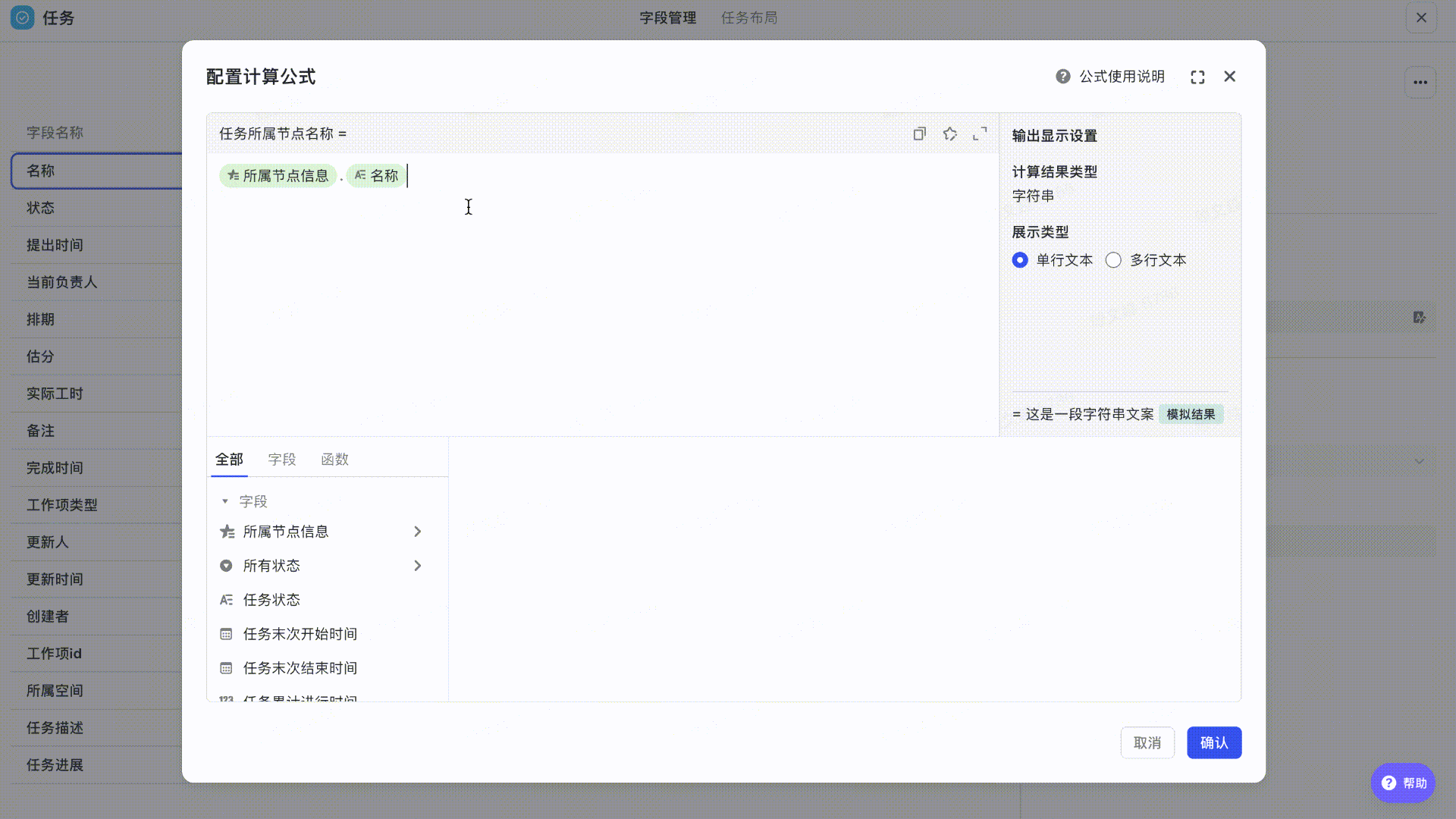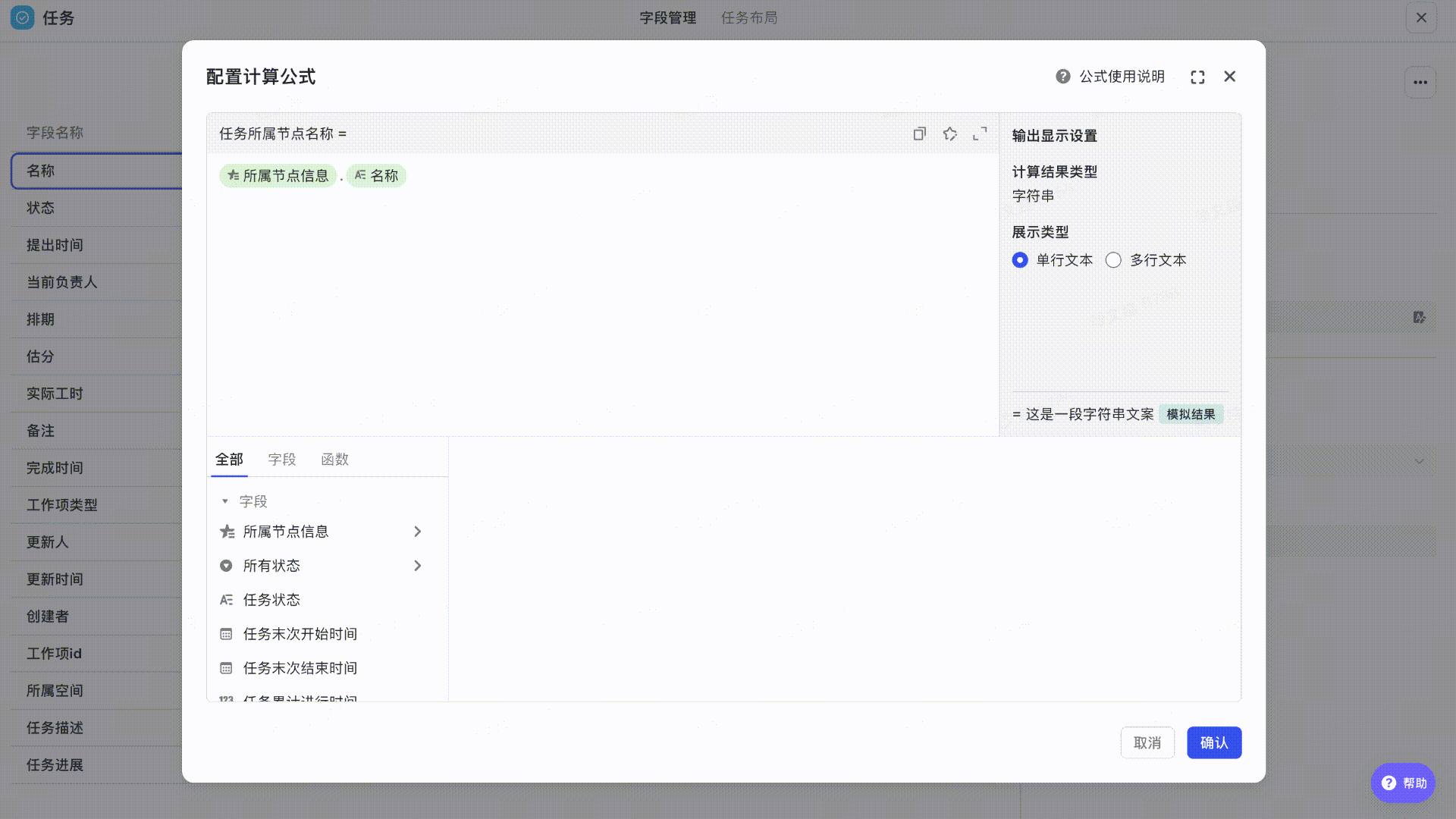
查看任务所属节点信息
场景:查看子任务的所属节点信息。
- 字段:所属节点信息、名称
- 计算公式:所属节点信息.名称
- 可复制公式:${所属节点信息}.${名称}
解析如下:
首先在任务工作项选择「所属节点信息」,输入“.“获取需要展示的所属节点对应信息,如”节点名称“
250px|700px|reset
常见问题
- 计算公式字段能否应用到度量?
支持。
- 计算公式字段能否在表格中进行编辑?
不支持,需要前往后台工作项编辑。
- 计算公式字段能否设置隐藏?
支持设置,请前往空间配置 - 用户组管理中设置。
- 如果数量出现重复数据如何处理?
请使用 countdistinct() 或者带有条件使用 countdistinctif() 函数。
- 计算公式字段是否支持数值导出?
支持,目前仅支持管理员在表格视图中导出。
- 计算公式字段是否支持内嵌飞书文档中展示?
支持。
- 计算公式字段是否支持应用到自动化?
不支持。
- 计算公式计算关联需求数据有问题原因是什么?
计算了已经终止的需求数量,需排出,使用 && =! 已终止









