2026年2月,OpenAI在官方博客发布了一篇文章,标题是Harness Engineering: leveraging Codex in an agent-first world。文章讲了一件听起来相当疯狂的事:他们用Codex Agent从零构建了一个软件产品,五个月交付上线,代码量约一百万行——没有一行是人写的。
这不是概念演示,不是Demo,而是真实上线的产品。
这意味着什么?意味着AI编程已经从"帮我写几行代码"的辅助工具,进化成了可以独立完成整个软件项目的生产力系统。但问题也随之而来:当编码行为本身可以被系统化委托时,真正的稀缺资源从"写代码的能力"变成了什么?
答案是:设计和构建这个"系统"的能力——也就是Harness Engineering。
如果你对AI编程还停留在"用ChatGPT帮我写函数"的理解上,这篇文章会刷新你的认知。我们系统性地拆解Harness Engineering的来龙去脉、核心方法和真实价值,不管你是软件工程师、技术管理者还是AI从业者,看完都会有实质收获。
一、AI软件工程的三次范式跃迁
过去三年,AI编程领域经历了三次认知升级,每一次都在回答同一个问题:"AI的问题到底出在哪里?"
1.1 Prompt Engineering:教AI说话
2022-2024年,AI编程的主流范式是Prompt Engineering。
这个阶段的核心逻辑是:通过精心设计提示词,让AI在单次交互中给出更好的代码。代表性技术包括Chain-of-Thought(思维链)、Few-Shot Learning(少样本学习)、Role Prompting(角色扮演)等。
250px|700px|reset
这个阶段的局限性也很清晰:单次交互能处理的任务复杂度有上限。AI会"遗忘"对话早期的重要上下文,会在长任务中逐渐漂移,也会在面对需要多步骤推理的工程问题时给出逻辑连贯但局部错误的答案。
Prompt Engineering解决的是"怎么说"的问题,但解决不了"说什么"的问题——因为当任务本身需要跨文件、跨模块理解时,单次Prompt的上下文窗口根本不够用。
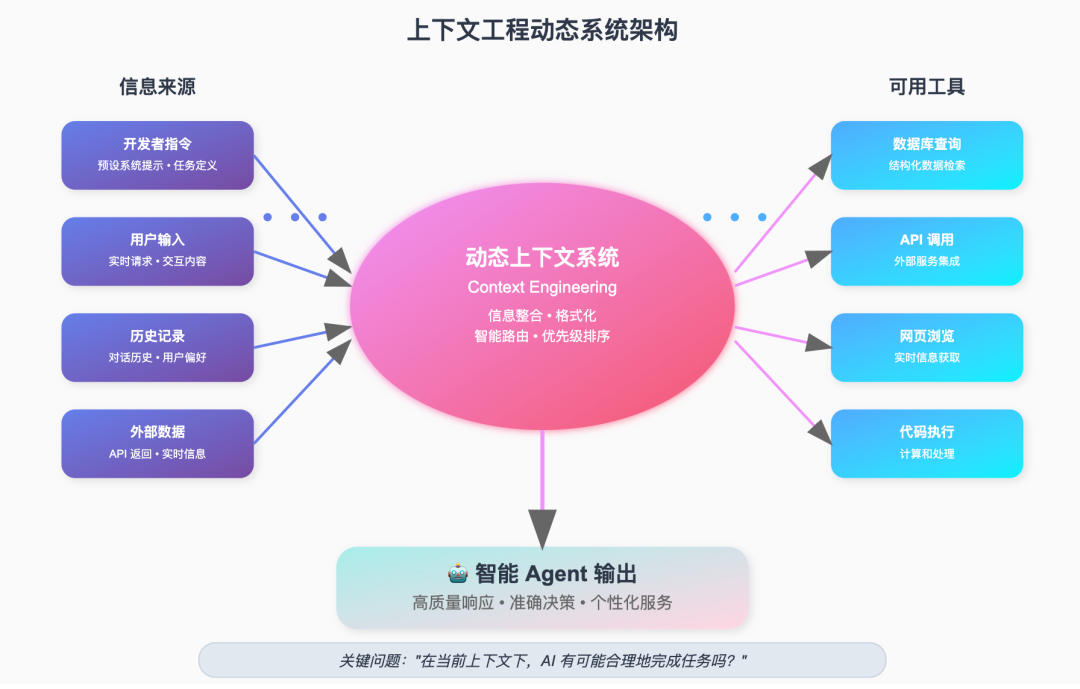
1.2 Context Engineering:给AI正确的上下文
2024年下半年,Context Engineering(上下文工程)开始崛起。
这个阶段的核心逻辑变了:AI表现不好,不是因为"说错了话",而是因为"没有正确的信息"。所以关键从"怎么说"转向了"给AI什么信息"。
代表性技术包括:RAG(检索增强生成)、向量知识库、AGENTS.md文档系统、以及各种记忆机制。开发者开始意识到,当AI能稳定访问项目文档、代码结构、历史决策这些上下文时,它的输出质量会显著提升。
250px|700px|reset
Context Engineering解决的是"说什么"的问题——但很快人们又发现,光有上下文还不够。AI拿到正确的上下文后,还是会漂移、会生成风格不一致的代码、会在复杂任务中执行路径混乱。
也就是说,AI的问题不只是"不知道",还有"不稳定"。
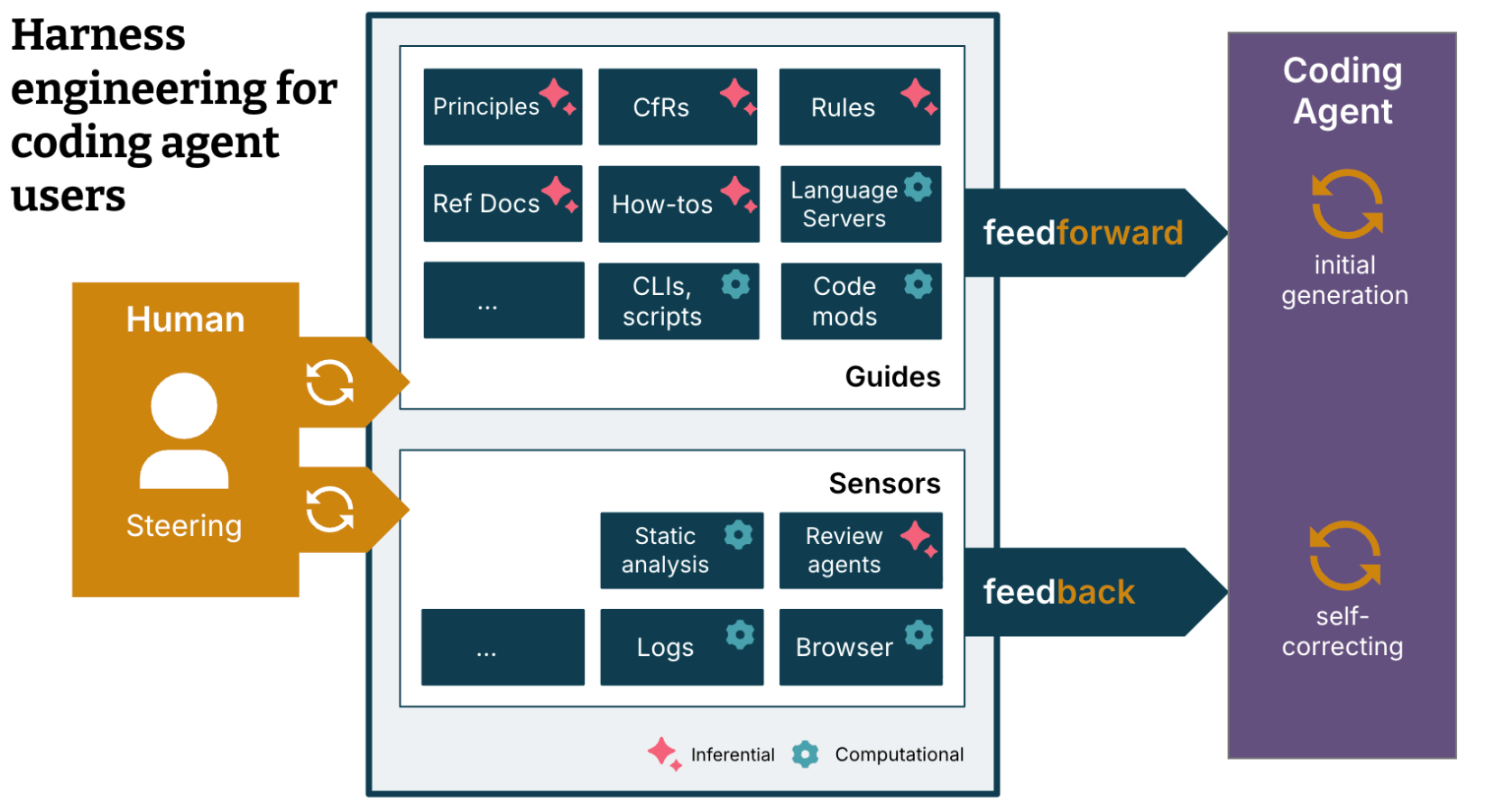
1.3 Harness Engineering:为AI构建运行环境
2026年2月,Mitchell Hashimoto(HashiCorp联合创始人、Terraform创作者)在博客中首次明确命名了Harness Engineering,OpenAI紧接着发布百万行代码实验报告,Martin Fowler跟进深度分析——这个概念迅速成为AI工程领域最热的话题。
Harness Engineering的核心问题变成:不是"怎么跟AI说话",而是"在什么环境里让AI跑"。
如果说Prompt Engineering研究的是"怎么驾驶",Context Engineering研究的是"地图和导航",那么Harness Engineering研究的则是整条赛道的设计——包括弯道、护栏、反馈系统、以及赛车本身的工程结构。
Martin Fowler提出了一个很有说服力的比喻:
如果AI是一个精力充沛但不知道往哪跑的马,那么Harness(驾驭具)不是骑师的鞭子,而是整条赛道的工程设计——你设计的是马必须跑在哪条路上、遇到什么障碍会触发什么反应、以及整个系统如何保证马最终跑向终点。
二、为什么Harness Engineering才是答案
2.1 Agent最大的问题不是"不够聪明",而是"不可预测"
让我们直接看OpenAI的实验数据:
- 5个月从零构建一个完整软件产品
- 0行人工编写的代码
- 约100万行代码全部由Codex Agent生成
- 每天约3.5个PR(Pull Request)的产出速度
- 最终成功上线并稳定运行
但问题也随之出现:当AI的产出速度远超人类的审查能力时,传统的代码质量控制方式完全失效了。
在没有约束的情况下,Agent会漂移——代码风格逐渐混乱,同一个功能出现多种不同实现,架构决策被反复推翻,注释和代码不一致。OpenAI把这种现象称为"熵增":代码库在没有系统性约束的情况下,自然地趋向混乱和无序。
这不是AI能力的问题,这是系统的问题。当产出速度超过人工审查能力时,必须用系统而非人工来保证质量。
2.2 流程管行为,环境管认知
Harness Engineering领域有一个核心洞察,来自Anthropic和OpenAI的实践经验:
"Agents aren't hard; the Harness is hard."(Agent本身不难,构建Harness才是难点。)
怎么理解这句话?我们来看两个不同思路的对比。
Anthropic的思路:管行为。 他们设计了Sprint Contract机制——每轮迭代开工前,Generator(生成者)和Evaluator(评估者)两个Agent先协商"做完长什么样",像甲方和施工队签验收标准。不是人类定的标准,是两个Agent自己谈出来的。这种机制管住的是Agent的具体行为模式。
OpenAI的思路:管认知。 他们提出了"Repo-as-truth"(代码仓库即真相源)的概念——不是告诉Agent"你不能做什么",而是确保Agent感知到的整个世界都是准确的、可执行的、自动维护的。整个代码仓库的架构约束、依赖规则、Linter配置、CI管线,都是Agent认知环境的组成部分。环境对了,Agent的行为自然不会漂移。
流程管住的是行为,环境管住的是认知。 这是两种不同层次的控制论解决方案,而Harness Engineering更侧重的是后者。
2.3 与其调教Agent,不如升级环境
Harness Engineering有一句话被开发者社区广泛引用:
"每当发现Agent犯错,就花时间设计一个解决方案,确保Agent永远不会再犯同样的错误。"
这不是在调教Agent,这是在升级环境。当一个错误被环境约束解决掉之后,所有未来经过这个环境的Agent都会自动受益——不需要逐个修复Prompt,不需要逐个更新指令。
这个思路的颠覆性在于:你不是在"用AI",你是在"建设AI能够稳定工作的系统"。
三、Harness Engineering五大核心实践
这一章我们来看Harness Engineering在工程层面具体是怎么做的。基于 OpenAI、Anthropic、LangChain、Cursor等团队的实践经验,我们提炼出五个最核心的实践方向。
实践一:AGENTS.md不是规则文档,而是目录地图
很多团队踩过的坑:一开始把AGENTS.md写成了一本超长的规则手册,把所有代码规范、架构决策、技术约定全部塞进去。结果文件越来越长,AI开始"读不进去"或者"读了但执行不一致"。
正确的思路是:AGENTS.md是一张目录地图,不是规则本身。
OpenAI在他们的实验中将AGENTS.md控制在约100行,内容是"去哪里找什么"——告诉Agent要找架构文档去哪个目录,要找API规范去哪个文件,要了解团队的代码风格去哪个规则库。
核心原则:按需加载,永不预加载。 记忆量可以无限增长,但上下文开销恒定,AI每次只读取跟当前任务相关的部分。
实践二:Repo-as-truth——所有架构约束必须编码进代码仓库
在传统开发中,架构文档是给人看的。但在Harness Engineering中,架构文档是给AI看的——所以必须编码进代码仓库,让AI能够感知和遵守。
具体做法包括:
- 依赖方向由CI自动验证。 如果Agent写了一段UI代码直接调用了Repo层(违反了分层架构),CI直接报错,PR过不了。
- 错误信息本身就是Prompt。 当Agent看到"你在这一层调用了那一层的模块,请修正"时,不需要额外的上下文就知道怎么改。
- 文档结构和代码结构同等重要。 AI不仅读代码,也读文档——文档是AI理解架构意图的核心渠道。
这样做的好处是:架构约束不再依赖人类的持续监督,而是被嵌入到了系统的每一次检查和验证中。
实践三:Linter + CI自动化反馈循环
Harness Engineering的核心工程闭环是:
Agent写代码 → Linter检查 → 发现违规 → 错误消息包含修复指引 → Agent读取指引 → 修复代码 → 再次检查 → 通过
这个循环的神奇之处在于:人类品味被编码一次,然后持续强制执行于每一行新代码。
OpenAI团队在实践中发现,到后来每周五不再需要人工清理代码风格问题——Agent每天自己扫一遍,发现问题自己修。人类的审美偏好变成了一次性的工程投入,然后由系统持续回收回报。
LangChain在Terminal Bench 2.0上的评测数据也验证了这一点:同一个模型,换一套更精巧的Harness架构,成绩从52.8%跳到66.5%,排名从Top 30跃升到Top 5。模型没变,分数大幅提升——这就是Harness的力量。
实践四:并发Agent的隔离与协调机制
当多Agent并行工作成为常态时,新的工程问题出现了。
Cursor团队在《Scaling long-running autonomous coding》中记录了一次失败实验:他们尝试让数百个Agent同时处理一个大型项目。结果,当20个Agent并发工作时,有效吞吐量急剧下降——因为锁机制成了瓶颈,多个Agent互相等待。更糟糕的是,等待中的Agent为了显示自己"还在工作",开始大量修改无关紧要的内容(注释、格式、空格),整个代码库被迅速污染。
解决方案是Coordinator Mode(协调者模式):一个主Agent充当工头,派出多个Worker执行具体任务。Worker要执行危险操作(比如删文件、跑脚本),必须向Coordinator申请许可。同一时间同一操作只有一张许可单,系统自动防止冲突。
这是Harness Engineering在并发场景下的典型工程挑战:不仅要保证单个Agent的行为可控,还要保证多个Agent并行工作时不会互相干扰。
实践五:多轮对抗评估与快速纠正机制
Anthropic在Agent评测中设计了一种"Sprint Contract"机制:Generator写代码,Evaluator对抗验收,两个Agent进行多轮博弈,直到Generator的产出被Evaluator接受。
他们在实验中观察到一个有趣的现象:经过九轮对抗后,Generator推翻了最初的所有设计方案,做出了一个3D CSS透视环境加空间导航的实现——这是被对抗压力逼出来的创造力,不是人类设计师提出的。
这揭示了Harness Engineering的一个核心信仰:出错了能快速被发现和纠正,比"保证Agent不出错"更现实,也更有效。
传统开发中,代码质量靠Code Review保证,但当Agent每天产出3.5个PR时,人工逐行审查成了瓶颈。Harness Engineering的解法是用系统化的对抗和评估机制替代人工审查,让问题在CI管线中被自动捕获,而不是等到上线后才发现。
四、Harness Engineering的局限性
没有任何工程方法论是银弹,Harness Engineering也不例外。在拥抱这个新范式之前,有必要清醒地认识它的局限。
局限一:高度定制,难以迁移
OpenAI自己在实验报告中明确写道:
"This behavior depends heavily on the specific structure and tooling of this repository and should not be assumed to generalize without similar investment."
翻译过来就是:这套能力高度依赖特定仓库的结构和工具配置,换一个项目基本等于重建。
这意味着Harness Engineering的初期投入是巨大的——可能需要数月的沉淀才能建立起一套稳定运转的环境系统。这和传统软件开发中"写好代码就能复用"的逻辑完全不同。
局限二:初期投入巨大,ROI周期长
对于只有几个人的创业团队或小型项目来说,花两个月构建Harness可能比直接写代码的成本还高。Harness Engineering目前更适合代码量大、团队规模大、迭代频率高的中大型项目。
局限三:模型能力决定天花板
再精巧的Harness架构,也没法让一个能力不足的模型产出高质量代码。这条限制对所有Harness实践都是通用的——Harness解决的是系统可靠性问题,不是模型智能问题。
Cursor团队在实践中总结出一句话:"影响系统行为最大的因素是prompt,其次是harness结构,最后才是模型本身。" 但这句话有一个隐藏前提:Cursor的harness已经过了多轮迭代优化,达到了一个相当高的水准。在那个水准之上,prompt的边际影响力才凸显出来。
局限四:对工程师能力提出新要求
Harness Engineering对"软件工程师"的定义提出了新要求:不再只是"能写代码",而是要理解系统设计、反馈机制、约束构建。Martin Fowler说得直接:
"What they describe sounds like much more work than just generating a bunch of Markdown rules files."
翻译:他们做的事比你写一堆Markdown规则文件要复杂得多。 需要真正理解"工程"而非仅仅擅长"编码"的人才能做好Harness Engineering。
五、谁应该学习Harness Engineering
这可能是你第一次听说Harness Engineering,但很可能,你其实已经在做一些相关的事情了。
如果你已经在用AGENTS.md或.cursorrules等规则文件管理AI编程助手的输出质量——你已经在做Harness Engineering的入门级实践。
更系统化的Harness Engineering能力,会让你在以下几个维度显著提升:
人群 | 核心收益 | 入门路径 |
软件工程师 | 用Agent提效的同时保持代码质量可控 | AGENTS.md优化 + CI反馈循环 |
技术管理者 | 评估和指导团队AI落地能力 | 理解Harness五层架构及其局限性 |
AI产品经理 | 设计真正能稳定运行的AI功能 | Agent评估体系 + 错误恢复机制 |
AI研究者 | 理解工程实践侧的核心挑战 | 多Agent协作 + 评估基准设计 |
结语
从Prompt Engineering到Context Engineering,再到Harness Engineering,过去三年AI编程领域的三次认知跃迁,回答的是同一个问题:AI的问题到底出在哪里?
Prompt Engineering说:是Prompt说得不够清楚。Context Engineering说:是上下文给得不够完整。Harness Engineering说:是环境设计得不够系统。
每一次跃迁都在扩大"环境"二字的边界。当我们把环境从单次对话扩展到整个代码仓库、CI管线、反馈系统、并发协调机制时,我们实际上是在把对AI的信任从个人能力转移到系统设计。
这也许是Harness Engineering最深刻的价值:它不是在加速"写代码"这件事,它是在重新定义"软件工程"本身。
2026年,Harness Engineering刚刚开始走进主流视野。不管你是主动拥抱还是被动接受,AI编程的游戏规则已经变了。你准备好吗?